
tabby 工具学习
0x01 前言
看到很多师傅都通过 tabby 来分析 CTF 题目以及找链子,所以最近自己也学一学
0x02 环境
- 当时自己在搭建环境的时候大致是在 2022 年的 12 月底左右,然后搭建环境踩坑了接近半个月多一点,最终还是放弃了;不过在 2023.3.1 附近的时间,H3Q3 哥哥说他起 tabby 很快,在他的帮助下我终于是把新版本的 tabby 搭建起来了
tabby 的项目地址 https://github.com/wh1t3p1g/tabby
我们去到 releases 下,选择 v1.2.0-1 的版本,也就是目前最新版本(可能过一段时间也会变,不过这个版本似乎很稳定
很不建议 IDEA 与 tabby 联动,我之前一直跑的有问题
首先需要先配置 Neo4j 的环境,强烈建议用 Neo4j 5.x 的版本。apoc 的两个插件需要与数据库版本对应。Neo4j 的配置我这里就不重复了
然后原作者说需要加上 tabby-path-finder 这个附加工具,加上这个是对的,但是无需把 neo4j.conf 当中的这一段修改
1 | dbms.security.procedures.unrestricted=jwt.security.*,apoc.* |
将 neo4j 配置完毕之后需要在 tabby 里面配置一下 settings.properties,如下,就能够跑得起来了,若是有踩坑的地方欢迎师傅们和我交流
1 | # enables |
按照上述步骤,应该是可以跑起来的
0x03 neo4j 教程
- 先说一说 neo4j 与 tabby 的关系,tabby 是一个将 jar 包中的信息提取出来,再到 neo4j 里面进行可视化的操作。这样可以让我们找反序列化的链子更加清晰快速。
其实写的不是很完全好,因为没什么例子可参考性。后续自己应该会重新学一学 CQL 语法,做一些简单的练习。这一部分会放在后面部分,如果师傅们想直接练习,可以直接看。
简介
MATCH:要匹配的图形模式。这是从图表中获取数据的最常用方法。WHERE: 本身不是一个子句,而是MATCH,OPTIONAL MATCH和的一部分WITH。向模式添加约束,或过滤通过WITHRETURN: 返回什么。
让我们使用以下查询创建一个简单的示例图
1 | CREATE (john:Person {name: 'John'}) |
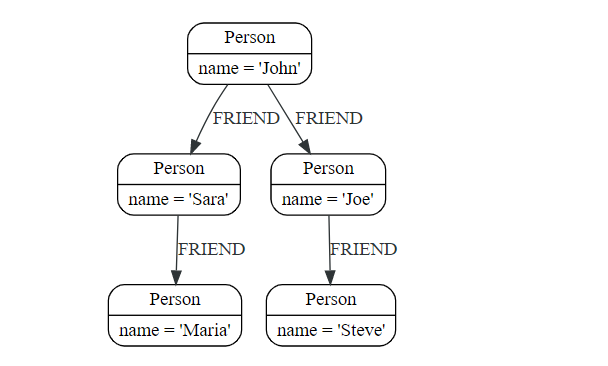
- 找到 John 的朋友的朋友
1 | MATCH (john {name: 'John'})-[:FRIEND]->()-[:FRIEND]->(fof) |
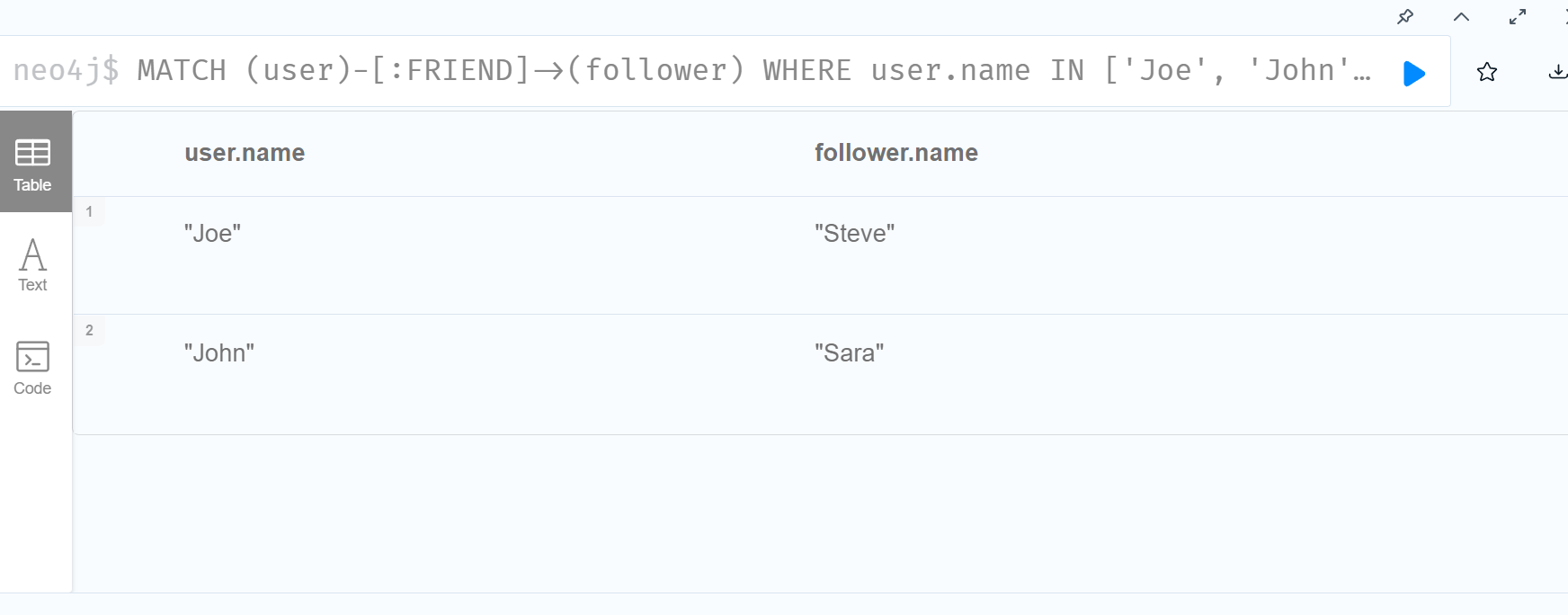
接下来,我们将添加过滤
我们获取一个用户名列表,并从该列表中找到具有名称的所有节点,匹配他们的朋友并仅返回那些具有以 ‘S’ 开头的 ‘name’ 属性的被关注用户。
1 | MATCH (user)-[:FRIEND]->(follower) |
1. CQL
CQL 代表 Cypher 查询语言。 像 Oracle 数据库具有查询语言 SQL,Neo4j 具有 CQL 作为查询语言
Neo4j CQL 命令/条款
| CQL 命令 / 条 | 用法 | |
|---|---|---|
| 1 | CREATE 创建 | 创建节点,关系和属性 |
| 2 | MATCH 匹配 | 检索有关节点,关系和属性数据 |
| 3 | RETURN 返回 | 返回查询结果 |
| 4 | WHERE 哪里 | 提供条件过滤检索数据 |
| 5 | DELETE 删除 | 删除节点和关系 |
| 6 | REMOVE 移除 | 删除节点和关系的属性 |
| 7 | ORDER BY 以… 排序 | 排序检索数据 |
| 8 | SET 组 | 添加或更新标签 |
Neo4j CQL 函数
| S.No. | 定制列表功能 | 用法 |
|---|---|---|
| 1 | String 字符串 | 它们用于使用 String 字面量。 |
| 2 | Aggregation 聚合 | 它们用于对 CQL 查询结果执行一些聚合操作。 |
| 3 | Relationship 关系 | 他们用于获取关系的细节,如 startnode,endnode 等。 |
Neo4j CQL 数据类型
这些数据类型与 Java 语言类似。 它们用于定义节点或关系的属性 Neo4j CQL 支持以下数据类型:
| S.No. | CQL 数据类型 | 用法 |
|---|---|---|
| 1 | boolean | 用于表示布尔文字:true,false。 |
| 2 | byte | 用于表示 8 位整数。 |
| 3 | short | 用于表示 16 位整数。 |
| 4 | int | 用于表示 32 位整数。 |
| 5 | long | 用于表示 64 位整数。 |
| 6 | float | I 用于表示 32 位浮点数。 |
| 7 | double | 用于表示 64 位浮点数。 |
| 8 | char | 用于表示 16 位字符。 |
| 9 | String | 用于表示字符串。 |
2. 命令
1. CREATE
和 SQL 语句大差不差
创建一个没有属性的节点
1 | CREATE (<node-name>:<label-name>) |
语法说明
规范说法是节点标签名称,其实相当于 Mysql 数据库中的表名,而是节点名称,其实代指创建的此行数据。
示例
1 | CREATE (emp:Employee) |
或者
1 | CREATE (:Employee) |
Neo4j CQL创建具有属性的节点
Neo4j CQL“CREATE” 命令用于创建带有属性的节点。 它创建一个具有一些属性(键值对)的节点来存储数据。
1 | CREATE ( |
实例
1 | CREATE (dept:Dept { deptno:10,dname:"Accounting",location:"Hyderabad" }) |
创建多个标签到节点
语法:
1 | CREATE (<node-name>:<label-name1>:<label-name2>.....:<label-namen>) |
2. MATCH 查询
Neo4j CQL MATCH命令用于
- 从数据库获取有关节点和属性的数据
- 从数据库获取有关节点,关系和属性的数据
比较像 SQL 语句当中的 select
MATCH 命令语法:
1 | MATCH |
示例
1 | MATCH (dept:Dept) |
但是执行后会报错:
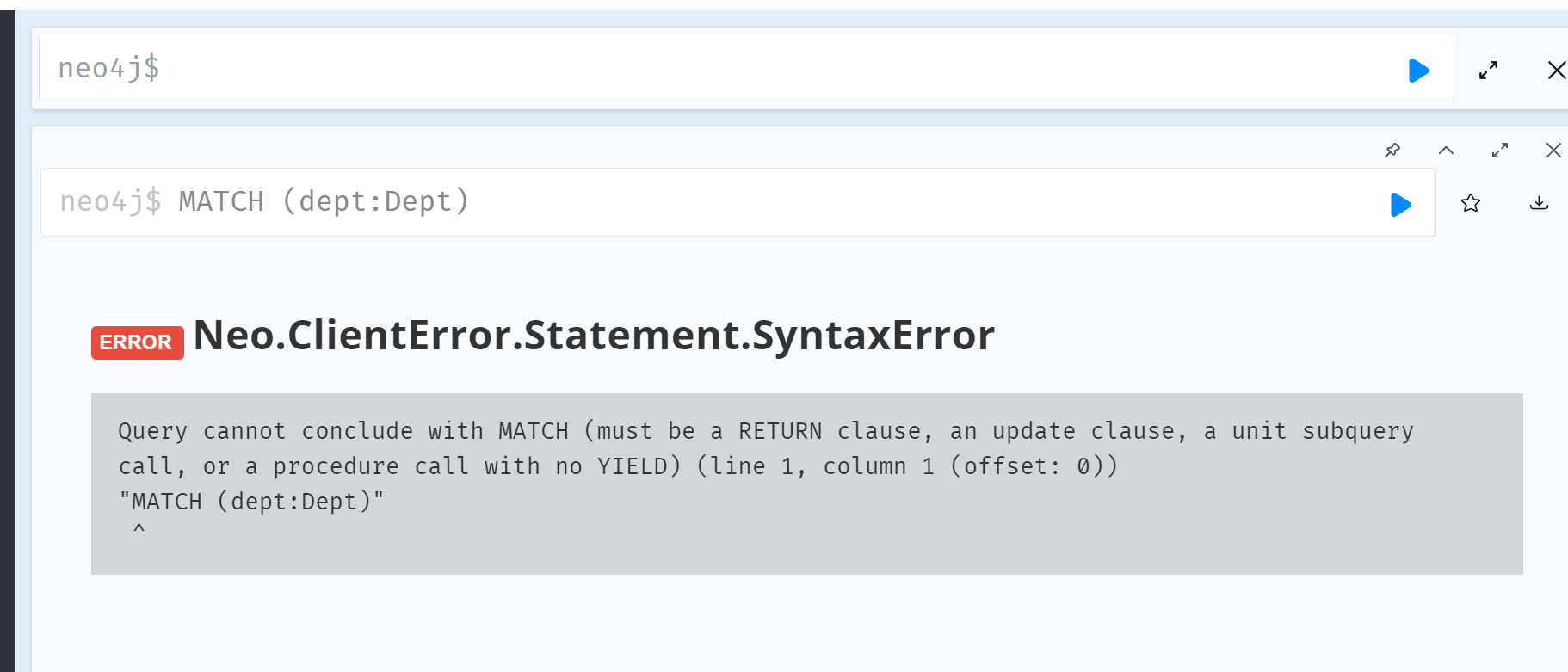
1 | Neo.ClientError.Statement.SyntaxError: |
如果你观察到错误消息,它告诉我们,我们可以使用 MATCH 命令与 RETURN 子句或 UPDATA 子句。
其实这里不难发现,因为之前在创建 Person 图的时候,我们查看它的节点,就是这样的 CQL 语句
1 | MATCH (n:Person) RETURN n LIMIT 25 |
3. RETURN 返回
Neo4j CQL RETURN 子句用于
- 检索节点的某些属性
- 检索节点的所有属性
- 检索节点和关联关系的某些属性
- 检索节点和关联关系的所有属性
RETURN 命令语法:
1 | RETURN |
示例
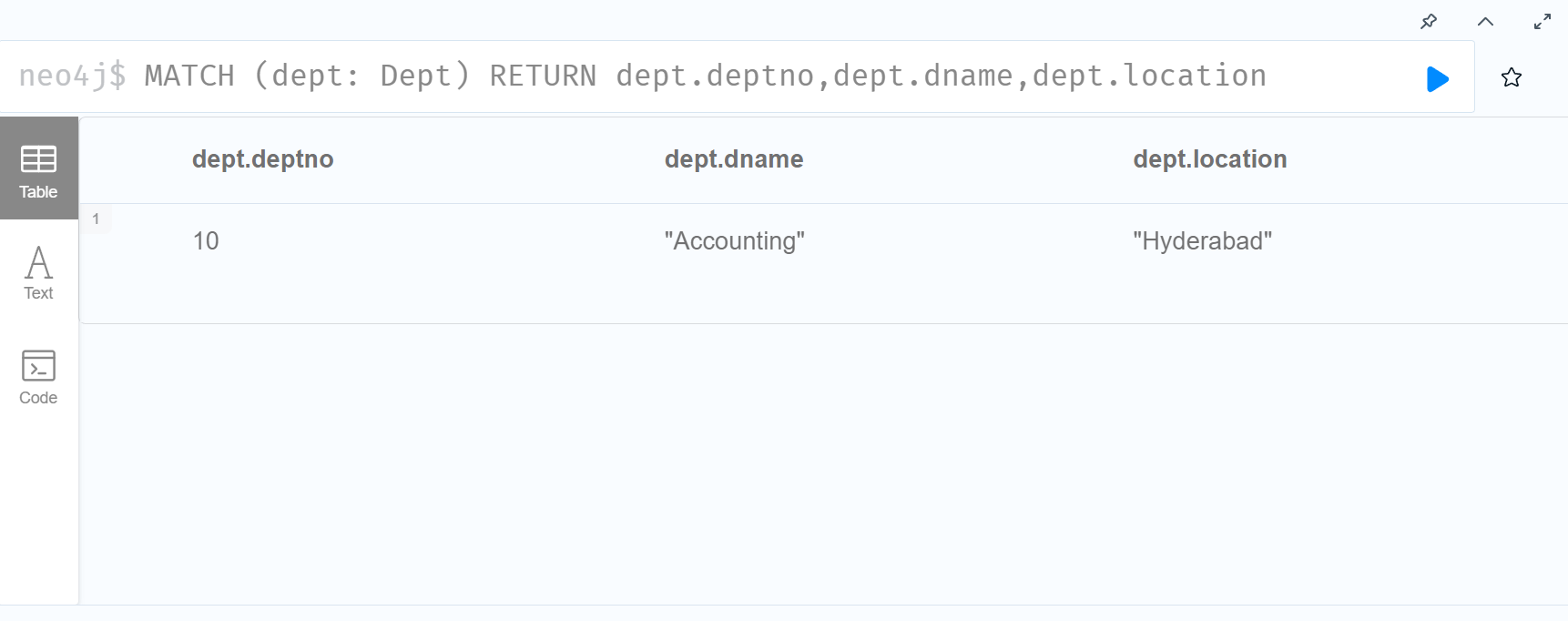
1 | MATCH (e:Employee) RETURN e |
或
1 | MATCH (dept: Dept) |
4. 关系基础
Neo4j图数据库遵循属性图模型来存储和管理其数据。
根据属性图模型,关系应该是定向的。 否则,Neo4j将抛出一个错误消息。
基于方向性,Neo4j关系被分为两种主要类型。
- 单向关系
- 双向关系
使用新节点创建关系
示例
1 | CREATE (e:Employee)-[r:DemoRelation]->(c:Employee) |
这句会创建节点e,节点c,以及e -> c的关系r,这里需要注意方向,比如双向是
1 | CREATE (e:Employee)<-[r:DemoRelation]->(c:Employee) |
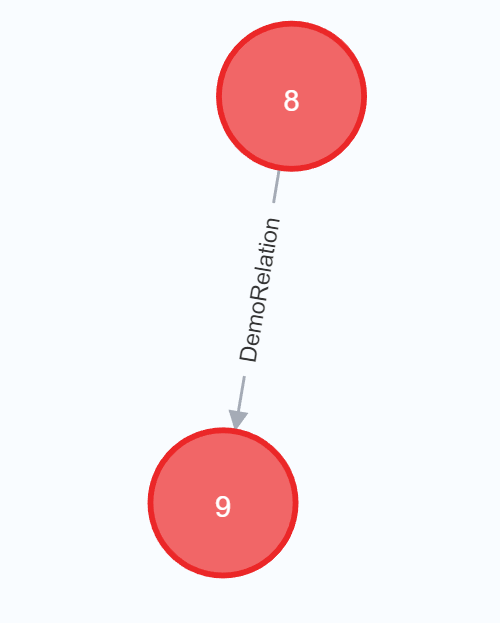
使用已知节点创建带属性的关系:
1 | MATCH (<node1-label-name>:<node1-name>),(<node2-label-name>:<node2-name>) |
还是一系列键值对
示例
1 | MATCH (cust:Customer),(cc:CreditCard) |
检索关系节点的详细信息:
1 | MATCH |
示例
1 | MATCH (cust)-[r:DO_SHOPPING_WITH]->(cc) |
5. WHERE 子句
像 SQL 一样,Neo4j CQL 在CQL MATCH命令中提供了WHERE子句来过滤MATCH查询的结果。
简单 WHERE 子句语法
1 | WHERE <property-name> <comparison-operator> <value> |
语法说明:
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1 | WHERE | 它是一个Neo4j CQL关键字。 |
| 2 | <属性名称> | 它是节点或关系的属性名称。 |
| 3 | <比较运算符> | 它是Neo4j CQL比较运算符之一。 |
| 4 | <值> | 它是一个字面值,如数字文字,字符串文字等。 |
Neo4j CQL中的比较运算符
Neo4j 支持以下的比较运算符,在 Neo4j CQL WHERE 子句中使用来支持条件
| S.No. | 布尔运算符 | 描述 |
|---|---|---|
| 1. | = | 它是Neo4j CQL“等于”运算符。 |
| 2. | <> | 它是一个Neo4j CQL“不等于”运算符。 |
| 3. | < | 它是一个Neo4j CQL“小于”运算符。 |
| 4. | > | 它是一个Neo4j CQL“大于”运算符。 |
| 5. | <= | 它是一个Neo4j CQL“小于或等于”运算符。 |
| 6. | = | 它是一个Neo4j CQL“大于或等于”运算符。 |
我们可以使用布尔运算符在同一命令上放置多个条件。
Neo4j CQL中的布尔运算符
Neo4j支持以下布尔运算符在Neo4j CQL WHERE子句中使用以支持多个条件。
| S.No. | 布尔运算符 | 描述 |
|---|---|---|
| 1 | AND | 它是一个支持AND操作的Neo4j CQL关键字。 |
| 2 | OR | 它是一个Neo4j CQL关键字来支持OR操作。 |
| 3 | NOT | 它是一个Neo4j CQL关键字支持NOT操作。 |
| 4 | XOR | 它是一个支持XOR操作的Neo4j CQL关键字。 |
示例
1 | MATCH (emp:Employee) |
利用 WHERE 创建指定关系节点:
1 | MATCH (cust:Customer),(cc:CreditCard) |
有必要补充一下,可以不使用WHERE达到WHERE的一些效果,比如
1 | MATCH p=(m:Bot{id:123})<-[:BotRelation]->(:Bot) |
6. DELETE 删除
Neo4j使用CQL DELETE子句
- 删除节点。
- 删除节点及相关节点和关系。
DELETE节点子句语法
1 | DELETE <node-name-list> |
示例
1 | MATCH (e: Employee) DELETE e |
DELETE节点和关系子句语法
1 | DELETE <node1-name>,<node2-name>,<relationship-name> |
示例
1 | MATCH (cc: CreditCard)-[rel]-(c:Customer) |
7. REMOVE 删除
有时基于我们的客户端要求,我们需要向现有节点或关系添加或删除属性。
我们使用Neo4j CQL SET子句向现有节点或关系添加新属性。
我们使用Neo4j CQL REMOVE子句来删除节点或关系的现有属性。
Neo4j CQL REMOVE命令用于
- 删除节点或关系的标签
- 删除节点或关系的属性
Neo4j CQL DELETE和REMOVE命令之间的主要区别 -
- DELETE操作用于删除节点和关联关系。
- REMOVE操作用于删除标签和属性。
Neo4j CQL DELETE和REMOVE命令之间的相似性 -
- 这两个命令不应单独使用。
- 两个命令都应该与MATCH命令一起使用。
REMOVE属性子句语法
1 | REMOVE <node-name>.<property1-name>,<node-name>.<property2-name> |
语法说明:
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1 | 它是节点的名称。 | |
| 2 | 它是节点的属性名称。 |
例如 DebitCard 节点包含6个属性。
在数据浏览器上键入以下命令删除 cvv 属性
1 | MATCH (dc:DebitCard) |
REMOVE一个Label子句语法:
1 | REMOVE <label-name-list> |
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1 | REMOVE | 它是一个Neo4j CQL关键字。 |
| 2 | 它是一个标签列表,用于永久性地从节点或关系中删除它。 |
语法
1 | <node-name>:<label2-name>, |
示例
1.我们创建一个含有两个标签的节点:
1 | CREATE (m:Movie:Pic) |
2.查询该节点
1 | MATCH (n:Movie) |
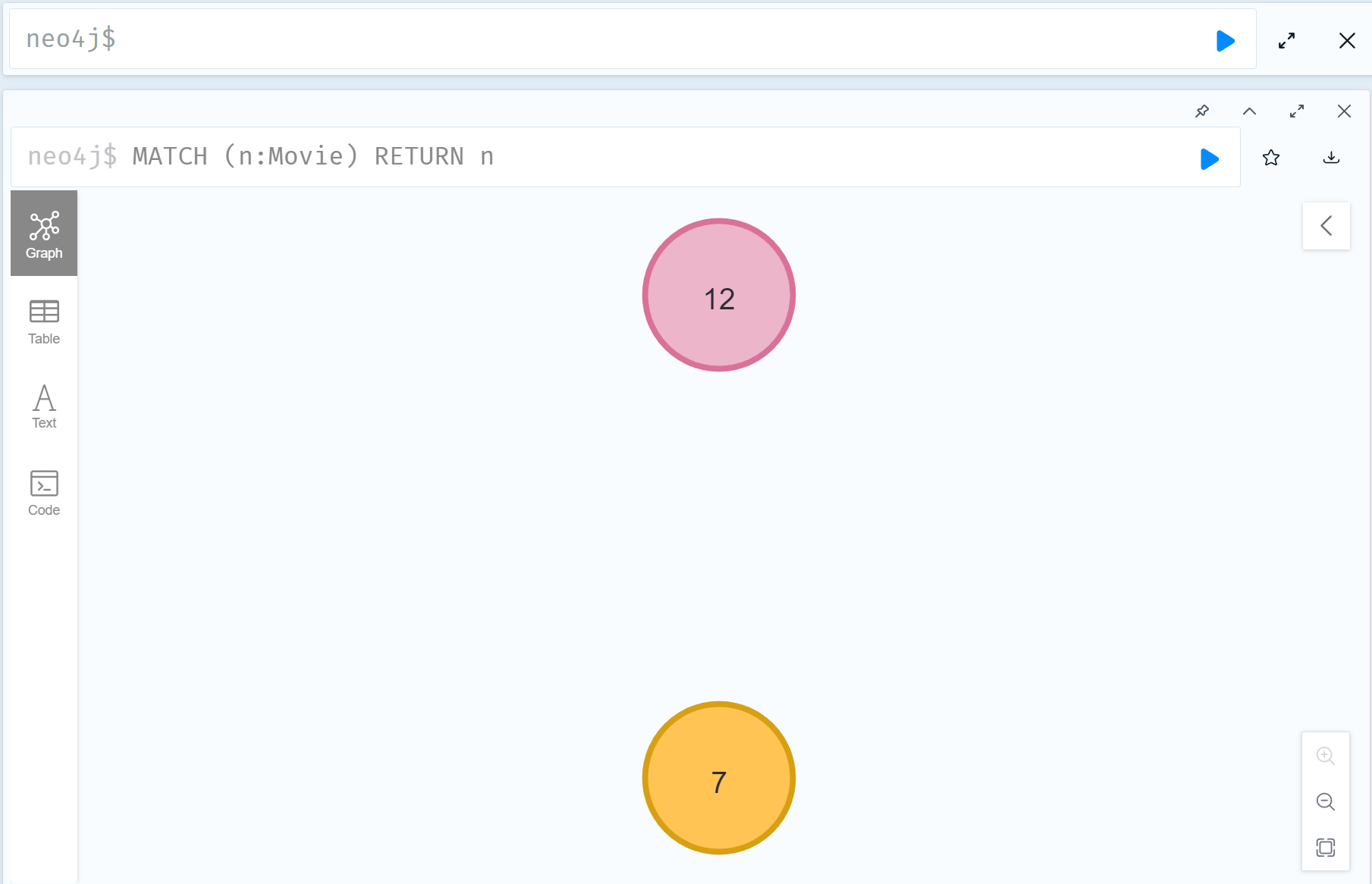
3.删除标签
1 | MATCH (m:Movie) |
4.再次查询
1 | MATCH (n:Movie) |
看到 Pic 已经被删除了
8. SET子句
有时,根据我们的客户端要求,我们需要向现有节点或关系添加新属性。
要做到这一点,Neo4j CQL提供了一个SET子句。
Neo4j CQL已提供SET子句来执行以下操作。
- 向现有节点或关系添加新属性
- 添加或更新属性值
SET子句语法
1 | SET <node-label-name>.<property1-name>,...<node-laben-name>.<propertyn-name> |
语法说明:
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1 | <节点标签名称> | 这是一个节点的标签名称。 |
| 2 | <属性名称> | 它是一个节点的属性名。 |
示例
1 | MATCH (dc:DebitCard) |
9. ORDER BY排序
Neo4j CQL ORDER BY子句
Neo4j CQL在MATCH命令中提供了“ORDER BY”子句,对MATCH查询返回的结果进行排序。
我们可以按升序或降序对行进行排序。
默认情况下,它按升序对行进行排序。 如果我们要按降序对它们进行排序,我们需要使用DESC子句。
ORDER BY子句语法
1 | ORDER BY <property-name-list> [DESC] |
语法:
1 | <node-label-name>.<property1-name>, |
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1 | 它是节点的标签名称。 | |
| 2 | 它是节点的属性名称。 |
示例
1 | MATCH (emp:Employee) |
10. UNION 子句
它将两组结果中的公共行组合并返回到一组结果中。 它不从两个节点返回重复的行。
限制:
结果列类型和来自两组结果的名称必须匹配,这意味着列名称应该相同,列的数据类型应该相同。
UNION子句语法
1 | <MATCH Command1> |
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1 | 它是CQL MATCH命令,由UNION子句使用。 | |
| 2 | 它是CQL MATCH命令两个由UNION子句使用。 | |
| 3 | UNION | 它是UNION子句的Neo4j CQL关键字。 |
注意
如果这两个查询不返回相同的列名和数据类型,那么它抛出一个错误。
UNION ALL 子句
它结合并返回两个结果集的所有行成一个单一的结果集。它还返回由两个节点重复行。
限制
结果列类型,并从两个结果集的名字必须匹配,这意味着列名称应该是相同的,列的数据类型应该是相同的。
UNION ALL子句语法
1 | <MATCH Command1> |
示例
1 | MATCH (cc:CreditCard) RETURN cc.id,cc.number |
11. LIMIT 和 SKIP 子句
Neo4j CQL已提供LIMIT子句和SKIP来过滤或限制查询返回的行数。
简单来说:LIMIT返回前几行,SKIP返回后几行。
LIMIT 示例
1 | MATCH (emp:Employee) |
它只返回Top的两个结果,因为我们定义了limit = 2。这意味着前两行。
SKIP示例
1 | MATCH (emp:Employee) |
它只返回来自Bottom的两个结果,因为我们定义了skip = 2。这意味着最后两行。
12. MERGE 命令
Neo4j使用CQL MERGE命令
- 创建节点,关系和属性
- 为从数据库检索数据
MERGE命令是CREATE命令和MATCH命令的组合。
1 | MERGE = CREATE + MATCH |
Neo4j CQL MERGE命令在图中搜索给定模式,如果存在,则返回结果
如果它不存在于图中,则它创建新的节点/关系并返回结果。
Neo4j CQL MERGE语法
1 | MERGE (<node-name>:<label-name> |
注意
Neo4j CQL MERGE命令语法与CQL CREATE命令类似。
我们将使用这两个命令执行以下操作 -
- 创建具有一个属性的配置文件节点:Id,名称
- 创建具有相同属性的同一个Profile节点:Id,Name
- 检索所有Profile节点详细信息并观察结果
我们将使用CREATE命令执行这些操作:
1 | MERGE (gp2:GoogleProfile2{ Id: 201402,Name:"Nokia"}) |
1 | MERGE (gp2:GoogleProfile2{ Id: 201402,Name:"Nokia"}) |
1 | MATCH (gp1:GoogleProfile1) |
如果我们观察上面的查询结果,它只显示一行,因为CQL MERGE命令检查该节点在数据库中是否可用。 如果它不存在,它创建新节点。 否则,它不创建新的。
通过观察这些结果,我们可以说,CQL MERGE命令将新的节点添加到数据库,只有当它不存在。
13. NULL值
Neo4j CQL将空值视为对节点或关系的属性的缺失值或未定义值。
当我们创建一个具有现有节点标签名称但未指定其属性值的节点时,它将创建一个具有NULL属性值的新节点。
让我们用一个例子来看这个。
1 | MATCH (e:Employee) |
提供了一个 WHERE 子句来过滤该行,即Id属性不应该包含NULL值。
1 | MATCH (e:Employee) |
这里我们使用IS操作符来仅返回NULL行。
14. IN操作符
与SQL一样,Neo4j CQL提供了一个IN运算符,以便为CQL命令提供值的集合。
IN操作符语法
1 | IN[<Collection-of-values>] |
它是由逗号运算符分隔的值的集合。
示例
1 | MATCH (e:Employee) |
15. INDEX索引
Neo4j SQL支持节点或关系属性上的索引,以提高应用程序的性能。
我们可以为具有相同标签名称的所有节点的属性创建索引。
我们可以在MATCH或WHERE或IN运算符上使用这些索引列来改进CQL Command的执行。
Neo4J索引操作
- Create Index 创建索引
- Drop Index 丢弃索引
我们将在本章中用示例来讨论这些操作。
创建索引的语法:
1 | CREATE INDEX ON :<label_name> (<property_name>) |
注意
冒号 (:) 运算符用于引用节点或关系标签名称。
上述语法描述它在节点或关系的的上创建一个新索引。
示例
1 | CREATE INDEX ON :Customer (name) |
删除索引的语法:
1 | DROP INDEX ON :<label_name> (<property_name>) |
示例
1 | DROP INDEX ON :Customer (name) |
16. UNIQUE约束
在Neo4j数据库中,CQL CREATE命令始终创建新的节点或关系,这意味着即使您使用相同的值,它也会插入一个新行。 根据我们对某些节点或关系的应用需求,我们必须避免这种重复。 然后我们不能直接得到这个。 我们应该使用一些数据库约束来创建节点或关系的一个或多个属性的规则。
像SQL一样,Neo4j数据库也支持对NODE或Relationship的属性的UNIQUE约束
UNIQUE约束的优点
- 避免重复记录。
- 强制执行数据完整性规则
创建唯一约束语法
1 | CREATE CONSTRAINT ON (<label_name>) |
语法说明:
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1 | CREATE CONSTRAINT ON | 它是一个Neo4j CQL关键字。 |
| 2 | 它是节点或关系的标签名称。 | |
| 3 | ASSERT | 它是一个Neo4j CQL关键字。 |
| 4 | 它是节点或关系的属性名称。 | |
| 5 | IS UNIQUE | 它是一个Neo4j CQL关键字,通知Neo4j数据库服务器创建一个唯一约束。 |
注意:
上述语法描述了只需要 节点或关系就可以创造一个独特的约束。
示例
1 | CREATE CONSTRAINT ON (cc:CreditCard) |
注意
如果创建约束时节点属性有重复值,Neo4j DB服务器将会抛出一个错误,表示无法创建。
删除UNIQUE约束语法:
1 | DROP CONSTRAINT ON (<label_name>) |
示例
1 | DROP CONSTRAINT ON (cc:CreditCard) |
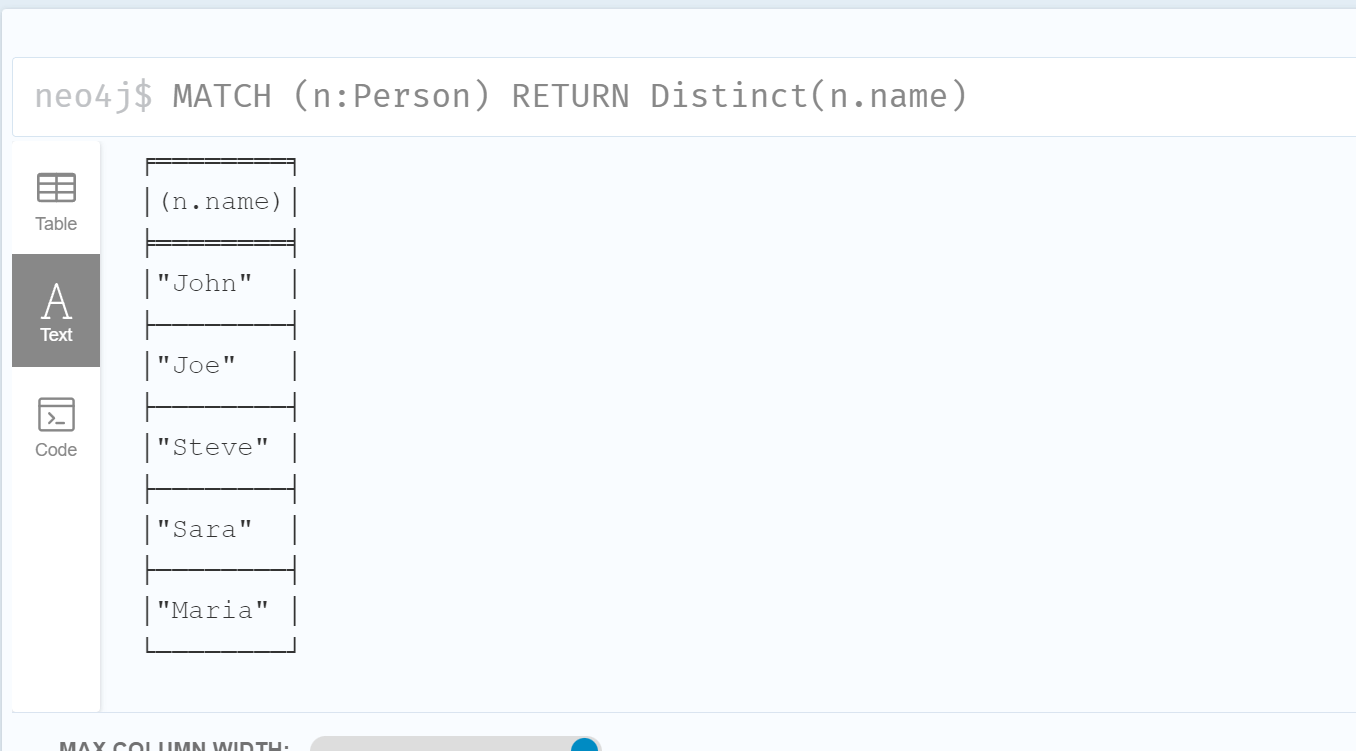
17. DISTINCT独特
这个函数的用法就像SQL中的distinct关键字,返回的是所有不同值。
示例
1 | MATCH (n:Person) RETURN Distinct(n.name) |
18. 运算符

值的排序与比较
比较运算符 <=,<(升序)和 >=,>(降序)可以用于值排序的比较。如下所示:
- 数字型值的排序比较采用数字顺序
java.lang.Double.NaN大于所有值- 字符串排序的比较采用字典顺序。如
"x" < "xy" - 布尔值的排序遵循
false < true - 当有个参数为 null 的时候,比较结果为 null。如
null < 3的结果为 null - 将其他类型的值相互比较进行排序将报错
19. 转义字符
Cypher 中的字符串可以包含如下转义字符
| 字符 | 含义 |
|---|---|
| \t | 制表符 |
| \b | 退格 |
| \n | 换行 |
| \r | 回车 |
| \f | 换页 |
| ' | 单引号 |
| " | 双引号 |
| \ | 反斜杠 |
| \uxxxx | Unicode UTF-16 编码点(4 位的十六进制数字必须跟在 \u 后面) |
| \Uxxxxxxxx | Unicode UTF-32 编码点(8 位的十六进制数字必须跟在 \U 后面) |
3. 函数
字符串函数
与SQL一样,Neo4j CQL提供了一组String函数,用于在CQL查询中获取所需的结果。
这里我们将讨论一些重要的和经常使用的功能。
字符串函数列表
| S.No. | 功能 | 描述 |
|---|---|---|
| 1 | UPPER | 它用于将所有字母更改为大写字母。 |
| 2 | LOWER | 它用于将所有字母改为小写字母。 |
| 3 | SUBSTRING | 它用于获取给定String的子字符串。 |
| 4 | REPLACE | 它用于替换一个字符串的子字符串。 |
注意:所有CQL函数应使用“()”括号。
现在我们将通过示例详细讨论每个Neo4J CQL字符串函数
UPPER
它需要一个字符串作为输入并转换为大写字母。 所有CQL函数应使用“()”括号。
函数语法
它需要一个字符串作为输入并转换为大写字母。 所有CQL函数应使用“()”括号。
函数语法
1 | UPPER (<input-string>) |
注意
可以是来自 Neo4j 数据库的节点或关系的属性名称。
示例
1 | MATCH (e:Employee) |
LOWER
它需要一个字符串作为输入并转换为小写字母。 所有CQL函数应使用“()”括号。
函数语法
1 | LOWER (<input-string>) |
注意:
可以是来自Neo4J数据库的节点或关系的属性名称
1 | MATCH (e:Employee) |
SUBSTRING
它接受一个字符串作为输入和两个索引:一个是索引的开始,另一个是索引的结束,并返回从StartInded到EndIndex-1的子字符串。 所有CQL函数应使用“()”括号。
函数的语法
1 | SUBSTRING(<input-string>,<startIndex> ,<endIndex>) |
注意:
在Neo4J CQL中,如果一个字符串包含n个字母,则它的长度为n,索引从0开始,到n-1结束。
是SUBSTRING函数的索引值。
是可选的。 如果我们省略它,那么它返回给定字符串的子串从startIndex到字符串的结尾。
示例
1 | MATCH (e:Employee) |
AGGREGATION聚合
和SQL一样,Neo4j CQL提供了一些在RETURN子句中使用的聚合函数。 它类似于SQL中的GROUP BY子句。
我们可以使用MATCH命令中的RETURN +聚合函数来处理一组节点并返回一些聚合值。
聚合函数列表
| S.No. | 聚集功能 | 描述 |
|---|---|---|
| 1 | COUNT | 它返回由MATCH命令返回的行数。 |
| 2 | MAX | 它从MATCH命令返回的一组行返回最大值。 |
| 3 | MIN | 它返回由MATCH命令返回的一组行的最小值。 |
| 4 | SUM | 它返回由MATCH命令返回的所有行的求和值。 |
| 5 | AVG | 它返回由MATCH命令返回的所有行的平均值。 |
现在我们将通过示例详细讨论每个Neo4j CQL AGGREGATION函数
计数
它从MATCH子句获取结果,并计算结果中出现的行数,并返回该计数值。 所有CQL函数应使用“()”括号。
函数语法
1 | COUNT(<value>) |
**注意 **
可以是*,节点或关系标签名称或属性名称。
示例
1 | MATCH (e:Employee) RETURN COUNT(*) |
MAX
它采用一组行和节点或关系的作为输入,并从给定行的give 列中查找最小值。
函数语法
1 | MAX(<property-name> ) |
MIN
它采用一组行和节点或关系的作为输入,并从给定行的give 列中查找最小值。
函数语法
1 | MIN(<property-name> ) |
**注意 **
应该是节点或关系的名称。
让我们用一个例子看看MAX和MIN的功能。
示例
1 | MATCH (e:Employee) |
AVG
它采用一组行和节点或关系的作为输入,并从给定行的give 列中查找平均值。
函数的语法
1 | AVG(<property-name> ) |
SUM
它采用一组行和节点或关系的作为输入,并从给定行的give 列中查找求和值。
函数的语法
1 | SUM(<property-name> ) |
让我们用一个例子来检查SUM和AVG函数。
1 | MATCH (e:Employee) |
此命令从数据库中可用的所有Employee节点查找总和平均值.
关系函数
Neo4j CQL提供了一组关系函数,以在获取开始节点,结束节点等细节时知道关系的细节。
关系函数列表
| S.No. | 功能 | 描述 |
|---|---|---|
| 1 | STARTNODE | 它用于知道关系的开始节点。 |
| 2 | ENDNODE | 它用于知道关系的结束节点。 |
| 3 | ID | 它用于知道关系的ID。 |
| 4 | TYPE | 它用于知道字符串表示中的一个关系的TYPE。 |
现在我们将通过示例详细讨论每个Neo4j CQL关系函数
STARTNODE
它需要一个字符串作为输入并转换为大写字母。 所有CQL函数应使用“()”括号。
函数语法
1 | STARTNODE (<relationship-label-name>) |
注意:
可以是来自Neo4j数据库的节点或关系的属性名称。
示例
1 | MATCH (a)-[movie:ACTION_MOVIES]->(b) |
ENDNODE
1 | MATCH (a)-[movie:ACTION_MOVIES]->(b) |
ID TYPE
1 | MATCH (a)-[movie:ACTION_MOVIES]->(b) |
0x04 tabby 的使用
污点分析
help
1 | call tabby.help("all") |
目前,tabby-path-finder 支持两种方式的路径查找
- 正向查找,
from source to sink - 逆向查找,
from sink to source
正向查找:
1 | tabby.algo.findVul(source, sinks, maxDepth, depthFirst) yield path tabby.algo.findJavaGadget(source, sinks, maxDepth, depthFirst) yield path |
其中 findJavaGadget 会根据 Java 原生反序列化的规则来查找利用链,但是会有一些 bug。推荐用完该函数之后再用 findVul 精确一下
逆向查找:
1 | tabby.algo.allSimplePaths(sink, sources, maxDepth, state, depthFirst) yield path |
tabby 分析模板语句
1 | match (source:Method {NAME:"readObject"}) // 限定source |
Properties Key
点击一个节点看右边,里面都有属性
这里有一些很重要的属性
- CLASSNAME: 类的位置
- NAME:方法名
- NAME0:类名 + 方法名
tabby 中练习 neo4j 语法
模板语句
1 | match (source:Method {NAME:"execute"}) |
- 本文标题:tabby 工具学习
- 创建时间:2022-12-26 11:05:09
- 本文链接:2022/12/26/tabby-工具学习/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!