
eBPF 运行原理,eBPF 学习(二)
eBPF 运行原理篇
eBPF 虚拟机是如何工作的
eBPF 的五个模块
eBPF 是一个运行在内核中的虚拟机,很多人在初次接触它时,会把它跟系统虚拟化(比如 kvm)中的虚拟机弄混。其实,虽然都被称为“虚拟机”,系统虚拟化和 eBPF 虚拟机还是有着本质不同的。
系统虚拟化基于 x86 或 arm64 等通用指令集,这些指令集足以完成完整计算机的所有功能。而为了确保在内核中安全地执行,eBPF 只提供了非常有限的指令集。这些指令集可用于完成一部分内核的功能,但却远不足以模拟完整的计算机。为了更高效地与内核进行交互,eBPF 指令还有意采用了 C 调用约定,其提供的辅助函数可以在 C 语言中直接调用,极大地方便了 eBPF 程序的开发。
如下图(图片来自 BPF Internals)所示,eBPF 在内核中的运行时主要由 5 个模块组成:
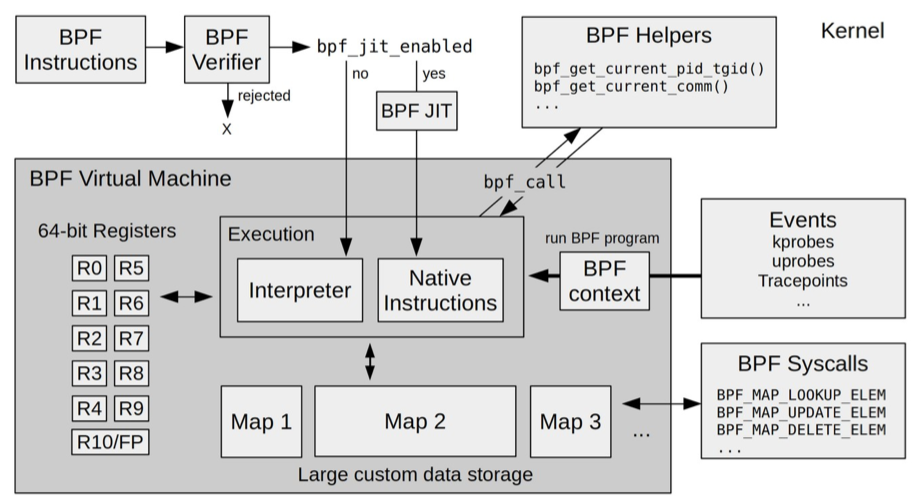
- 第一个模块是 eBPF 辅助函数。它提供了一系列用于 eBPF 程序与内核其他模块进行交互的函数。这些函数并不是任意一个 eBPF 程序都可以调用的,具体可用的函数集由 BPF 程序类型决定。
- 第二个模块是 eBPF 验证器。它用于确保 eBPF 程序的安全。验证器会将待执行的指令创建为一个有向无环图(DAG),确保程序中不包含不可达指令;接着再模拟指令的执行过程,确保不会执行无效指令。
- 第三个模块是由 11 个 64 位寄存器、一个程序计数器和一个 512 字节的栈组成的存储模块。这个模块用于控制 eBPF 程序的执行。其中,R0 寄存器用于存储函数调用和 eBPF 程序的返回值,这意味着函数调用最多只能有一个返回值;R1-R5 寄存器用于函数调用的参数,因此函数调用的参数最多不能超过 5 个;而 R10 则是一个只读寄存器,用于从栈中读取数据。
- 第四个模块是即时编译器,它将 eBPF 字节码编译成本地机器指令,以便更高效地在内核中执行。
- 第五个模块是 BPF 映射(map),它用于提供大块的存储。这些存储可被用户空间程序用来进行访问,进而控制 eBPF 程序的运行状态。
关于 BPF 辅助函数和 BPF 映射的具体内容我会放在后续的文章里面详细编写,现在我们先来看看 BPF 指令的具体格式,以及它是如何加载到内核中,又是何时运行的。
BPF 指令是什么样的
用上一讲的 Hello World 作为例子,一起看下 BPF 指令到底是什么样子的。
它的逻辑其实很简单,先调用 bpf_trace_printk 输出一个 “Hello, World!” 字符串,然后就返回成功了:
1 | int hello_world(void *ctx) |
然后,我们通过 BCC 的 Python 库,加载并运行了这个 eBPF 程序:
1 | #!/usr/bin/env python3 |
在终端中运行下面的命令,就可以启动这个 eBPF 程序(注意, BCC 帮你完成了编译和加载的过程)
1 | python3 hello.py |
接下来我们使用一个新的工具 bpftool,用它可以查看 eBPF 程序的运行状态。
首先,打开一个新的终端,执行下面的命令,查询系统中正在运行的 eBPF 程序:
1 | sudo bpftool prog list |
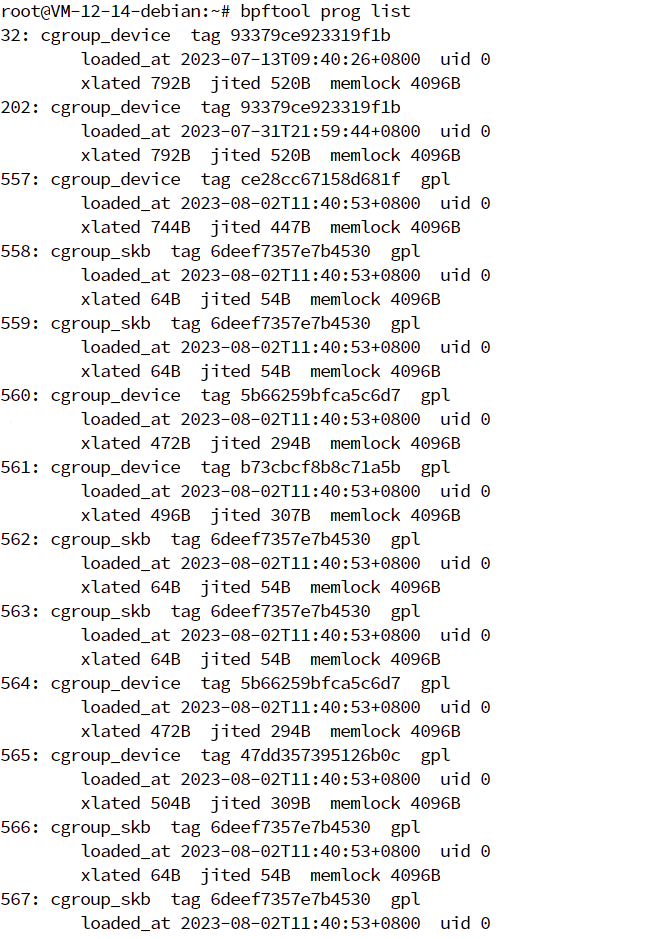
输出中,579 是这个 eBPF 程序的编号,kprobe 是程序的类型,而 hello_world 是程序的名字。
有了 eBPF 程序编号之后,执行下面的命令就可以导出这个 eBPF 程序的指令(注意把 579 替换成你查询到的编号)
1 | sudo bpftool prog dump xlated id 579 |
这里有个小坑,需要自己手动编译 libelf-dev 的源码,具体见 https://blog.csdn.net/Withdraw_end/article/details/132127777
输出结果
1 | int hello_world(void * ctx): |
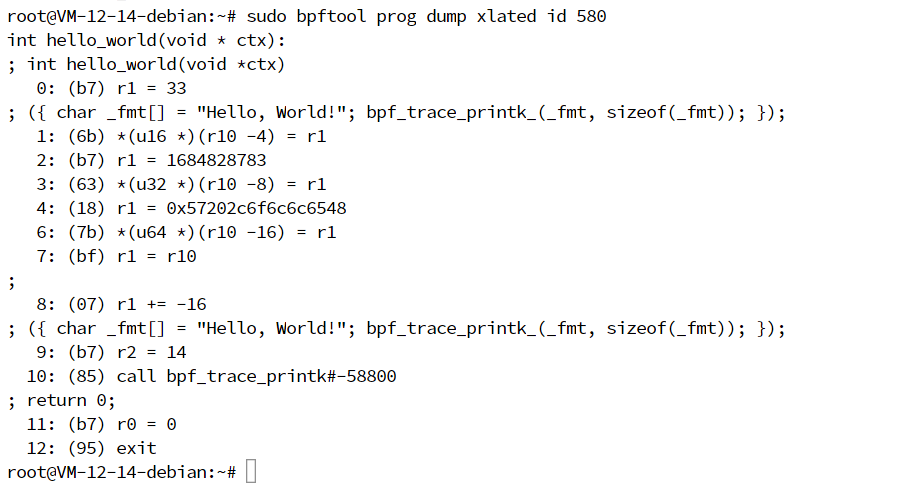
其中,分号开头的部分,正是我们前面写的 C 代码,而其他行则是具体的 BPF 指令。具体每一行的 BPF 指令又分为三部分:
- 第一部分,冒号前面的数字 0-12 ,代表 BPF 指令行数;
- 第二部分,括号中的 16 进制数值,表示 BPF 指令码。它的具体含义你可以参考 IOVisor BPF 文档,比如第 0 行的 0xb7 表示为 64 位寄存器赋值。
- 第三部分,括号后面的部分,就是 BPF 指令的伪代码。
结合前面讲述的各个寄存器的作用,不难理解这些 BPF 指令的含义:
- 第 0-8 行,借助 R10 寄存器从栈中把字符串 “Hello, World!” 读出来,并放入 R1 寄存器中;
- 第 9 行,向 R2 寄存器写入字符串的长度 14(即代码注释里面的
sizeof(_fmt)); - 第 10 行,调用 BPF 辅助函数
bpf_trace_printk输出字符串; - 第 11 行,向 R0 寄存器写入 0,表示程序的返回值是 0;
- 最后一行,程序执行成功退出。
总结起来,这些指令先通过 R1 和 R2 寄存器设置了 bpf_trace_printk 的参数,然后调用 bpf_trace_printk 函数输出字符串,最后再通过 R0 寄存器返回成功。
实际上我们也可以通过类似的 BPF 指令来开发 eBPF 程序,不过相对于一开始的 C 程序相比,BPF 指令的可读性和维护性明显差得多。所以还是建议使用 C 语言开发 eBPF 程序,而只把 BPF 指令作为排查 eBPF 程序疑难杂症时的参考。
这里,来简单看看 BPF 指令加载后是如何运行的。当这些 BPF 指令加载到内核后, BPF 即时编译器会将其编译成本地机器指令,最后才会执行编译后的机器指令:
1 |
|
这些机器指令的含义跟前面的 BPF 指令是类似的,但具体的指令和寄存器都换成了 x86 的格式。你不需要掌握这些机器指令的具体含义,只要知道查询的具体方法就足够了。这是因为,就像你曾接触过的其他高级语言一样,在实际的 eBPF 使用过程中,并不需要直接使用机器指令,而是 eBPF 虚拟机帮你自动完成了转换。
eBPF 程序是什么时候执行的
到这里,我想你已经理解了 BPF 指令的具体格式,以及它与 C 源代码之间的对应关系。不过,这个 eBPF 程序到底是什么时候执行的呢?接下来,我们再一起看看 BPF 指令的加载和执行过程。
在上一讲中我提到,BCC 负责了 eBPF 程序的编译和加载过程。因而,要了解 BPF 指令的加载过程,就可以从 BCC 执行 eBPF 程序的过程入手。
那么,怎么才能查看到 BCC 的执行过程呢?那就是跟踪它的系统调用过程。首先,我们打开一个终端,执行下面的命令:
1 | # -ebpf表示只跟踪bpf系统调用 |
输出如下
1 | bpf(BPF_BTF_LOAD, { |

这些参数看起来很复杂,但实际上,如果你查询 bpf 系统调用的格式(执行 man bpf 命令),就可以发现,它实际上只需要三个参数:
1 | int bpf(int cmd, union bpf_attr *attr, unsigned int size); |
对应前面的 strace 输出结果,这三个参数的具体含义如下。
- 第一个参数是 BPF_PROG_LOAD , 表示加载 BPF 程序。
- 第二个参数是 bpf_attr 类型的结构体,表示 BPF 程序的属性。其中,有几个需要你留意的参数,比如:
prog_type表示 BPF 程序的类型,这儿是BPF_PROG_TYPE_KPROBE,跟我们 Python 代码中的attach_kprobe一致;insn_cnt (instructions count)表示指令条数;insns (instructions) 包含了具体的每一条指令,这儿的 13 条指令跟我们前面bpftool prog dump的结果是一致的(具体的指令格式,你可以参考内核中 bpf_insn 的定义);prog_name则表示 BPF 程序的名字,即hello_world。
- 第三个参数 120 表示属性的大小。
到这里,我们已经了解了 bpf 系统调用的基本格式。对于 bpf 系统调用在内核中的实现原理,你并不需要详细了解。我们只要知道它的具体功能,就可以掌握 eBPF 的核心原理了。当然,如果你对它的实现方法有兴趣的话,可以参考内核源码 kernel/bpf/syscall.c 中 SYSCALL_DEFINE3 的实现。
BPF 程序加载到内核后,并不会立刻执行,而是基于它的基本原理来的
eBPF 程序并不像常规的线程那样,启动后就一直运行在那里,它需要事件触发后才会执行。这些事件包括系统调用、内核跟踪点、内核函数和用户态函数的调用退出、网络事件,等等。
对于我们的 Hello World 来说,由于调用了 attach_kprobe 函数,很明显,这是一个内核跟踪事件:
1 | b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world") |
所以,除了把 eBPF 程序加载到内核之外,还需要把加载后的程序跟具体的内核函数调用事件进行绑定。在 eBPF 的实现中,诸如内核跟踪(kprobe)、用户跟踪(uprobe)等的事件绑定,都是通过 perf_event_open() 来完成的。
为什么这么说呢?我们再用 strace 来确认一下。把前面 strace 命令中的 -ebpf 参数去掉,重新执行:
1 | sudo strace -v -f python3 ./hello.py |
忽略无关的输出后,会发现如下的系统调用:
1 | ... |
从输出中,我们可以看出 BPF 与性能事件的绑定过程分为以下几步:
- 首先,借助 bpf 系统调用,加载 BPF 程序,并记住返回的文件描述符;
- 然后,查询 kprobe 类型的事件编号。BCC 实际上是通过
/sys/bus/event_source/devices/kprobe/type来查询的; - 接着,调用
perf_event_open创建性能监控事件。比如,事件类型(type 是上一步查询到的 6)、事件的参数( config1 包含了内核函数do_sys_openat2)等; - 最后,再通过
ioctl的PERF_EVENT_IOC_SET_BPF命令,将 BPF 程序绑定到性能监控事件。
小结 eBPF 虚拟机工作原理
梳理 eBPF 在内核中的实现原理,并以上一讲的 Hello World 程序为例,借助 bpftool、strace 等工具,观察了 BPF 指令的具体格式。
然后,我们从 BCC 执行 eBPF 程序的过程入手,一起看了 BPF 指令的加载和执行过程。用高级语言开发的 eBPF 程序,需要首先编译为 BPF 字节码(即 BPF 指令),然后借助 bpf 系统调用加载到内核中,最后再通过性能监控等接口,与具体的内核事件进行绑定。这样,内核的性能监控模块才会在内核事件发生时,自动执行我们开发的 eBPF 程序。
eBPF 程序是怎么跟内核进行交互的
eBPF 程序到底是如何跟内核事件进行绑定的?又该如何跟内核中的其他模块进行交互呢?今天,一起看看 eBPF 程序的编程接口。
如下图(图片来自 brendangregg.com)所示,一个完整的 eBPF 程序通常包含用户态和内核态两部分。其中,用户态负责 eBPF 程序的加载、事件绑定以及 eBPF 程序运行结果的汇总输出;内核态运行在 eBPF 虚拟机中,负责定制和控制系统的运行状态。
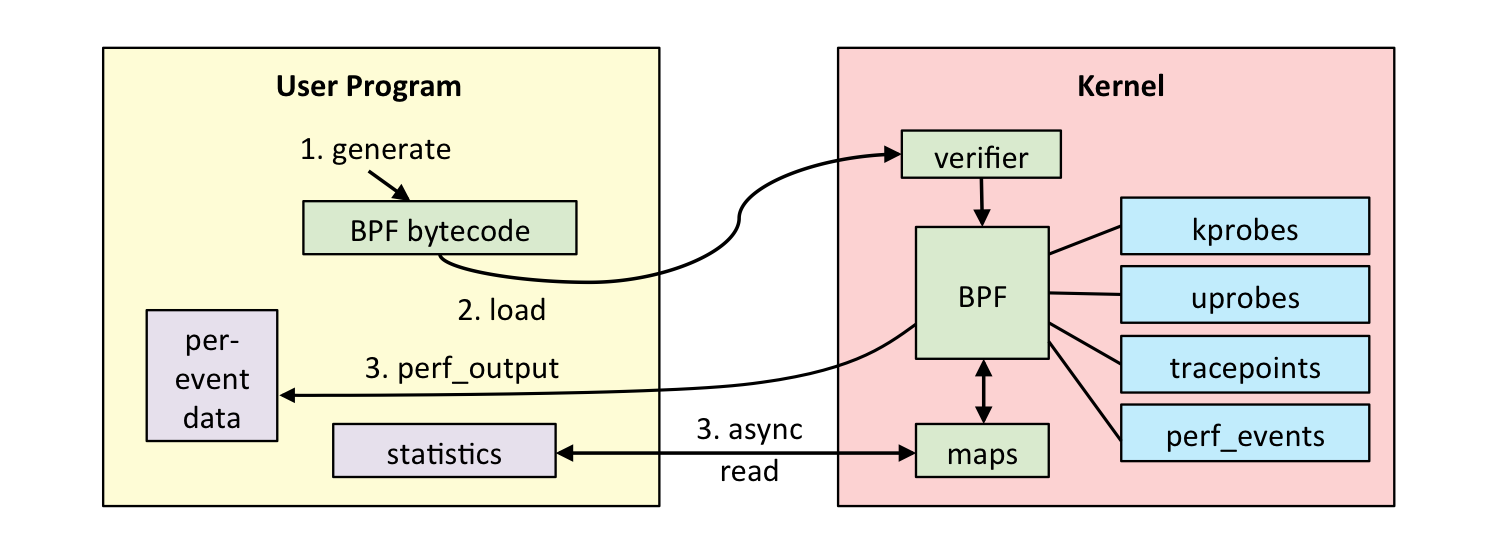
对于用户态程序来说,我想你已经了解,它们与内核进行交互时必须要通过系统调用来完成。而对应到 eBPF 程序中,我们最常用到的就是 bpf 系统调用。
在命令行中输入 man bpf ,就可以查询到 BPF 系统调用的调用格式(虽然前面已经看过了
1 |
|
BPF 系统调用接受三个参数:
- 第一个,cmd ,代表操作命令,比如上一讲中我们看到的
BPF_PROG_LOAD就是加载 eBPF 程序; - 第二个,attr,代表
bpf_attr类型的 eBPF 属性指针,不同类型的操作命令需要传入不同的属性参数; - 第三个,size ,代表属性的大小。
注意,不同版本的内核所支持的 BPF 命令是不同的,具体支持的命令列表可以参考内核头文件 include/uapi/linux/bpf.h 中 bpf_cmd 的定义。比如,v5.13 内核已经支持 36 个 BPF 命令:
1 | enum bpf_cmd { |
命令对应的表格
BPF 辅助函数
说完用户态程序的 bpf 系统调用格式,我们再来看看内核态的 eBPF 程序。
eBPF 程序并不能随意调用内核函数,因此,内核定义了一系列的辅助函数,用于 eBPF 程序与内核其他模块进行交互,这一个实现方式其实是通过 eBPF helpers 来做的。
比如,上一讲的 Hello World 示例中使用的 bpf_trace_printk() 就是最常用的一个辅助函数,用于向调试文件系统(/sys/kernel/debug/tracing/trace_pipe)写入调试信息。
这里补充一个知识点:从内核 5.13 版本开始,部分内核函数(如 tcp_slow_start()、tcp_reno_ssthresh() 等)也可以被 BPF 程序直接调用了,具体你可以查看这个链接。 不过,这些函数只能在 TCP 拥塞控制算法的 BPF 程序中调用,此处不再做过多的介绍。
需要注意的是,并不是所有的辅助函数都可以在 eBPF 程序中随意使用,不同类型的 eBPF 程序所支持的辅助函数是不同的。比如,对于 Hello World 示例这类内核探针(kprobe)类型的 eBPF 程序,你可以在命令行中执行 bpftool feature probe ,来查询当前系统支持的辅助函数列表:
1 | $ bpftool feature probe |
对于这些辅助函数的详细定义,你可以在命令行中执行 man bpf-helpers ,或者参考内核头文件 bpf.h - include/uapi/linux/bpf.h,来查看它们的详细定义和使用说明。为了方便掌握,我把常用的辅助函数整理成了一个表格,可以在需要时参考:

这其中,需要你特别注意的是以 bpf_probe_read 开头的一系列函数。在上一讲中已经提到,eBPF 内部的内存空间只有寄存器和栈。所以,要访问其他的内核空间或用户空间地址,就需要借助 bpf_probe_read 这一系列的辅助函数。这些函数会进行安全性检查,并禁止缺页中断的发生。
而在 eBPF 程序需要大块存储时,就不能像常规的内核代码那样去直接分配内存了,而是必须通过 BPF 映射(BPF Map)来完成。接下来,我带你看看 BPF 映射的具体原理。
BPF 映射
BPF 映射用于提供大块的键值存储,这些存储可被用户空间程序访问,进而获取 eBPF 程序的运行状态。eBPF 程序最多可以访问 64 个不同的 BPF 映射,并且不同的 eBPF 程序也可以通过相同的 BPF 映射来共享它们的状态。下图(图片来自docs.cilium.io)展示了 BPF 映射的基本使用方法。

在前面的 BPF 系统调用和辅助函数小节中,你也看到,有很多系统调用命令和辅助函数都是用来访问 BPF 映射的。我相信细心的你已经发现了:BPF 辅助函数中并没有 BPF 映射的创建函数,BPF 映射只能通过用户态程序的系统调用来创建。比如,你可以通过下面的示例代码来创建一个 BPF 映射,并返回映射的文件描述符:
1 | int bpf_create_map(enum bpf_map_type map_type, |
这其中,最关键的是设置映射的类型。内核头文件 include/uapi/linux/bpf.h 中的 bpf_map_type 定义了所有支持的映射类型,你可以使用如下的 bpftool 命令,来查询当前系统支持哪些映射类型:
1 | $ bpftool feature probe | grep map_type |
在下面的表格中,整理了几种最常用的映射类型及其功能和使用场景:
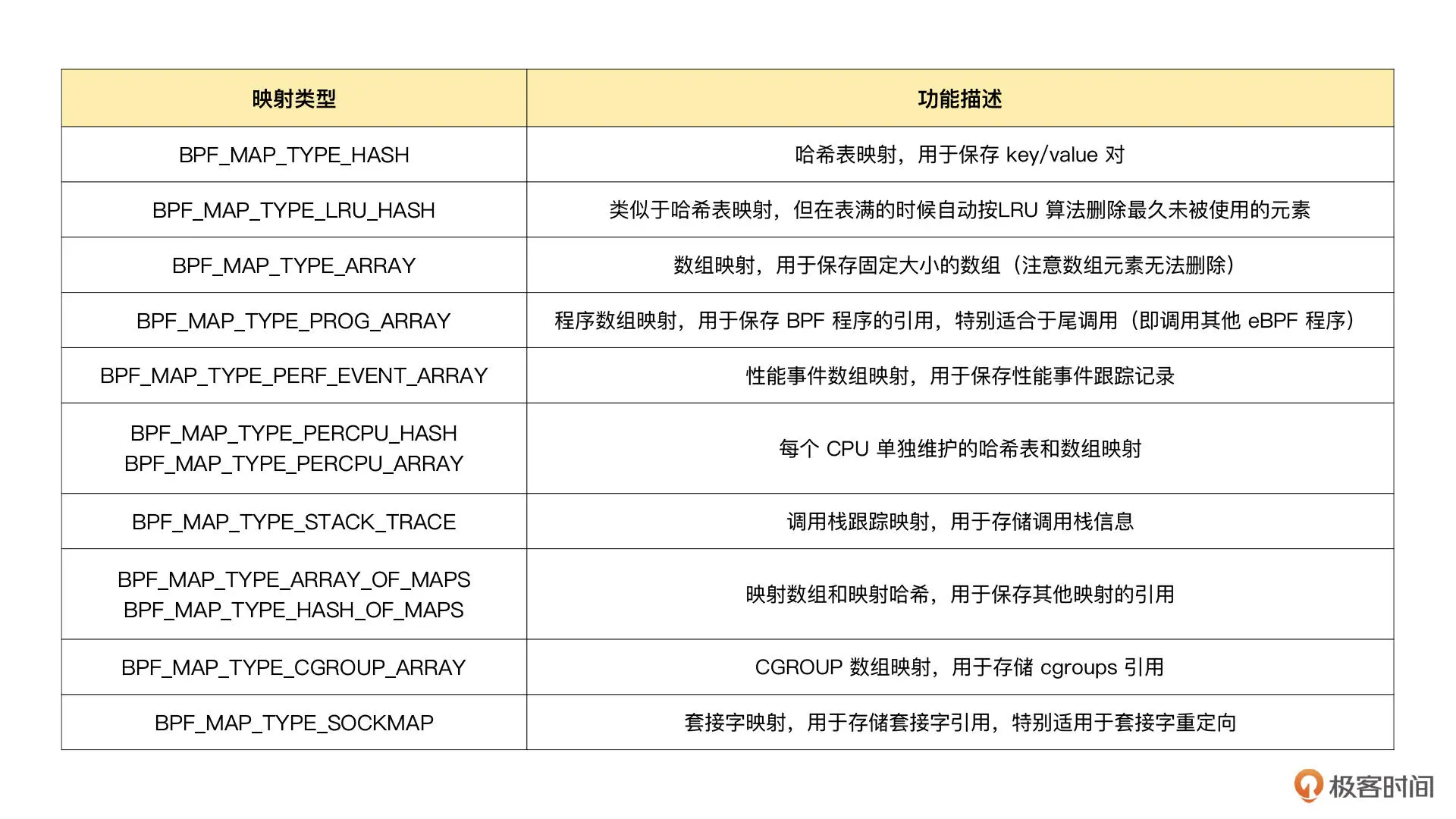
如果你的 eBPF 程序使用了 BCC 库,你还可以使用预定义的宏来简化 BPF 映射的创建过程。比如,对哈希表映射来说,BCC 定义了 BPF_HASH(name, key_type=u64, leaf_type=u64, size=10240),因此,你就可以通过下面的几种方法来创建一个哈希表映射:
1 | // 使用默认参数 key_type=u64, leaf_type=u64, size=10240 |
除了创建之外,映射的删除也需要你特别注意。BPF 系统调用中并没有删除映射的命令,这是因为 BPF 映射会在用户态程序关闭文件描述符的时候自动删除(即close(fd) )。 如果你想在程序退出后还保留映射,就需要调用 BPF_OBJ_PIN 命令,将映射挂载到 /sys/fs/bpf 中。
在调试 BPF 映射相关的问题时,你还可以通过 bpftool 来查看或操作映射的具体内容。比如,你可以通过下面这些命令创建、更新、输出以及删除映射:
1 | //创建一个哈希表映射,并挂载到/sys/fs/bpf/stats_map(Key和Value的大小都是2字节) |

BPF 类型格式(BTF)
了解过 BPF 辅助函数和映射之后,我们再来看一个开发 eBPF 程序时最常碰到的问题:内核数据结构的定义。
在安装 BCC 工具的时候,你可能就注意到了,内核头文件 linux-headers-$(uname -r) 也是必须要安装的一个依赖项。这是因为 BCC 在编译 eBPF 程序时,需要从内核头文件中找到相应的内核数据结构定义。这样,你在调用 bpf_probe_read 时,才能从内存地址中提取到正确的数据类型。
但是,编译时依赖内核头文件也会带来很多问题。主要有这三个方面:
- 首先,在开发 eBPF 程序时,为了获得内核数据结构的定义,就需要引入一大堆的内核头文件;
- 其次,内核头文件的路径和数据结构定义在不同内核版本中很可能不同。因此,你在升级内核版本时,就会遇到找不到头文件和数据结构定义错误的问题;
- 最后,在很多生产环境的机器中,出于安全考虑,并不允许安装内核头文件,这时就无法得到内核数据结构的定义。在程序中重定义数据结构虽然可以暂时解决这个问题,但也很容易把使用着错误数据结构的 eBPF 程序带入新版本内核中运行。
那么,这么多的问题该怎么解决呢?不用担心,BPF 类型格式(BPF Type Format, BTF)的诞生正是为了解决这些问题。
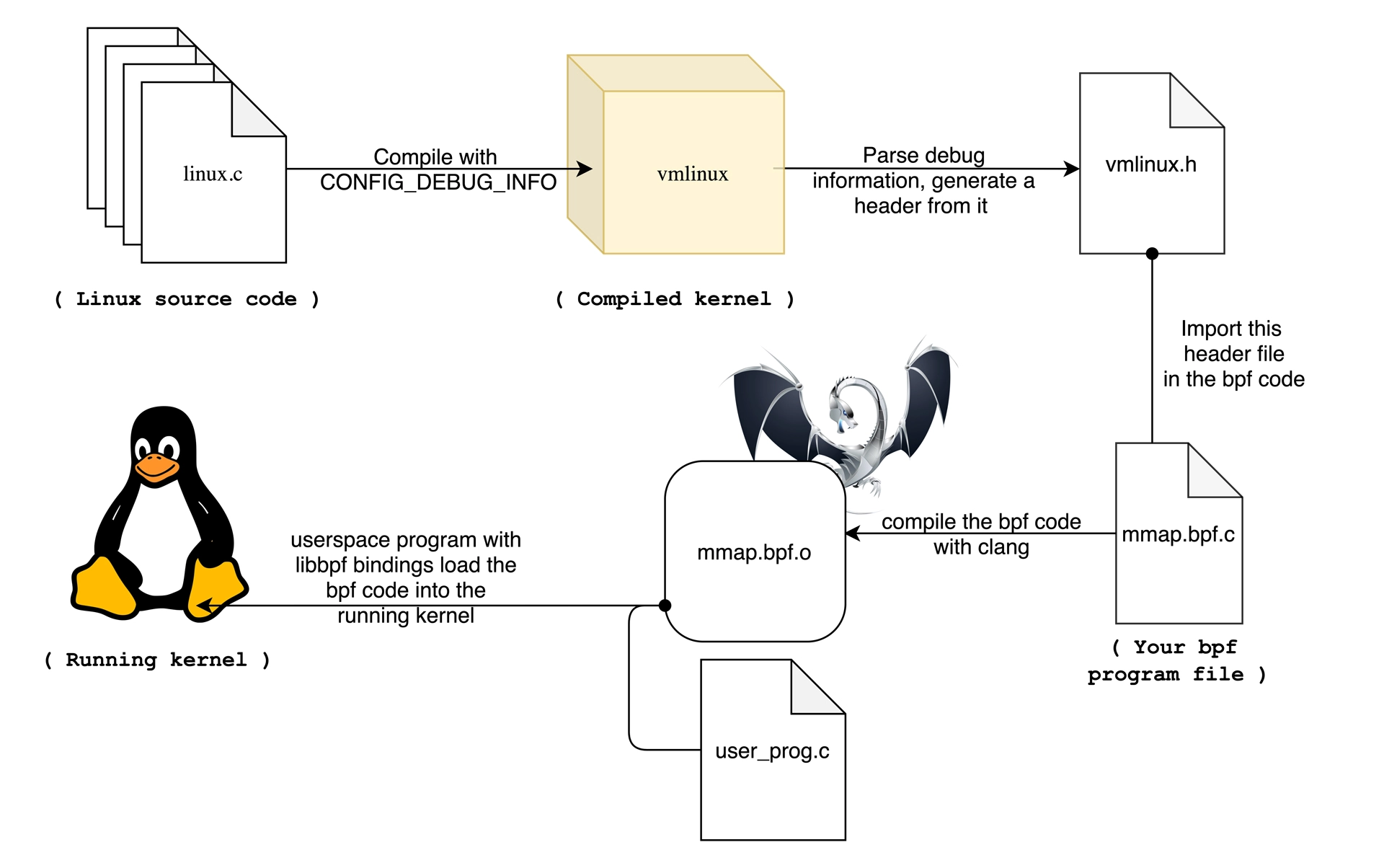
从内核 5.2 开始,只要开启了 CONFIG_DEBUG_INFO_BTF,在编译内核时,内核数据结构的定义就会自动内嵌在内核二进制文件 vmlinux 中。并且,你还可以借助下面的命令,把这些数据结构的定义导出到一个头文件中(通常命名为 vmlinux.h):
1 | bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h |
如下图(图片来自 GRANT SELTZER 博客)所示,有了内核数据结构的定义,你在开发 eBPF 程序时只需要引入一个 vmlinux.h 即可,不用再引入一大堆的内核头文件了。
同时,借助 BTF、bpftool 等工具,我们也可以更好地了解 BPF 程序的内部信息,这也会让调试变得更加方便。比如,在查看 BPF 映射的内容时,你可以直接看到结构化的数据,而不只是十六进制数值:
1 | # bpftool map dump id 386 |
解决了内核数据结构的定义问题,接下来的问题就是,如何让 eBPF 程序在内核升级之后,不需要重新编译就可以直接运行。eBPF 的一次编译到处执行(Compile Once Run Everywhere,简称 CO-RE)项目借助了 BTF 提供的调试信息,再通过下面的两个步骤,使得 eBPF 程序可以适配不同版本的内核:
- 第一,通过对 BPF 代码中的访问偏移量进行重写,解决了不同内核版本中数据结构偏移量不同的问题;
- 第二,在 libbpf 中预定义不同内核版本中的数据结构的修改,解决了不同内核中数据结构不兼容的问题。
BTF 和一次编译到处执行带来了很多的好处,但你也需要注意这一点:它们都要求比较新的内核版本(>=5.2),并且需要非常新的发行版(如 Ubuntu 20.10+、RHEL 8.2+ 等)才会默认打开内核配置 CONFIG_DEBUG_INFO_BTF。对于旧版本的内核,虽然它们不会再去内置 BTF 的支持,但开源社区正在尝试通过 BTFHub 等方法,为它们提供 BTF 调试信息。
小结 eBPF 程序是怎么跟进程进行交互的
一个完整的 eBPF 程序,通常包含用户态和内核态两部分:用户态程序需要通过 BPF 系统调用跟内核进行交互,进而完成 eBPF 程序加载、事件挂载以及映射创建和更新等任务;而在内核态中,eBPF 程序也不能任意调用内核函数,而是需要通过 BPF 辅助函数完成所需的任务。尤其是在访问内存地址的时候,必须要借助 bpf_probe_read 系列函数读取内存数据,以确保内存的安全和高效访问。
在 eBPF 程序需要大块存储时,我们还需要根据应用场景,引入特定类型的 BPF 映射,并借助它向用户空间的程序提供运行状态的数据。
Ref
极客时间 eBPF 核心技术与实战
- 本文标题:eBPF 运行原理
- 创建时间:2023-08-03 22:48:30
- 本文链接:2023/08/03/eBPF-运行原理/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!