
eBPF 内核跟踪,eBPF 学习(四)
eBPF 内核跟踪
今天我们先来看看,怎样使用 eBPF 去跟踪内核的状态,特别是最简单的 bpftrace 的使用方法。在下一讲中,我还将介绍两种 eBPF 程序的进阶编程方法。
上一讲中提到过,跟踪类 eBPF 程序主要包含内核插桩(BPF_PROG_TYPE_KPROBE)、跟踪点(BPF_PROG_TYPE_TRACEPOINT)以及性能事件(BPF_PROG_TYPE_PERF_EVENT)等程序类型,而每类 eBPF 程序类型又可以挂载到不同的内核函数、内核跟踪点或性能事件上。当这些内核函数、内核跟踪点或性能事件被调用的时候,挂载到其上的 eBPF 程序就会自动执行。
那么,你可能想问了:当我不知道内核中都有哪些内核函数、内核跟踪点或性能事件的时候,可以在哪里查询到它们的列表呢?对于内核函数和内核跟踪点,在需要跟踪它们的传入参数和返回值的时候,又该如何查询这些数据结构的定义格式呢?别担心,接下来就跟我一起去探索下吧。
bpftrace 查询跟踪点的几种方法
官方文档 https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md
利用调试信息查询跟踪点
实际上,作为一个软件系统,内核也经常会发生各种各样的问题,比如安全漏洞、逻辑错误、性能差,等等。因此,内核本身的调试与跟踪一直都是内核提供的核心功能之一。
比如,为了方便调试,内核把所有函数以及非栈变量的地址都抽取到了 /proc/kallsyms 中,这样调试器就可以根据地址找出对应的函数和变量名称。很显然,具有实际含义的名称要比 16 进制的地址易读得多。对内核插桩类的 eBPF 程序来说,它们要挂载的内核函数就可以从 /proc/kallsyms 这个文件中查到。
注意,内核函数是一个非稳定 API,在新版本中可能会发生变化,并且内核函数的数量也在不断增长中。以 v5.13.0 为例,总的内核符号表数量已经超过了 16 万:
1 | $ cat /proc/kallsyms | wc -l |
不过需要提醒你的是,这些符号表不仅包含了内核函数,还包含了非栈数据变量。而且,并不是所有的内核函数都是可跟踪的,只有显式导出的内核函数才可以被 eBPF 进行动态跟踪。因而,通常我们并不直接从内核符号表查询可跟踪点,而是使用我接下来介绍的方法。
为了方便内核开发者获取所需的跟踪点信息,内核调试文件系统还向用户空间提供了内核调试所需的基本信息,如内核符号列表、跟踪点、函数跟踪(ftrace)状态以及参数格式等。你可以在终端中执行 sudo ls /sys/kernel/debug 来查询内核调试文件系统的具体信息。比如,执行下面的命令,就可以查询 execve 系统调用的参数格式:
1 | sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_execve/format |
注意,eBPF 程序的执行也依赖于调试文件系统。如果你的系统没有自动挂载它,那么我推荐你把它加入到系统开机启动脚本里面,这样机器重启后 eBPF 程序也可以正常运行。
有了调试文件系统,你就可以从 /sys/kernel/debug/tracing 中找到所有内核预定义的跟踪点,进而可以在需要时把 eBPF 程序挂载到对应的跟踪点。
除了内核函数和跟踪点之外,性能事件又该如何查询呢?你可以使用 Linux 性能工具 perf 来查询性能事件的列表。如下面的命令所示,你可以不带参数查询所有的性能事件,也可以加入可选的事件类型参数进行过滤:
1 | sudo perf list [hw|sw|cache|tracepoint|pmu|sdt|metric|metricgroup] |
利用 bpftrace 查询跟踪点
虽然你可以利用内核调试信息和 perf 工具查询内核函数、跟踪点以及性能事件的列表,但它们的位置比较分散,并且用这种方法也不容易查询内核函数的定义格式。所以,我再给你推荐一个更好用的 eBPF 工具 bpftrace。
bpftrace 在 eBPF 和 BCC 之上构建了一个简化的跟踪语言,通过简单的几行脚本,就可以实现复杂的跟踪功能。并且,多行的跟踪指令也可以放到脚本文件中执行(脚本后缀通常为 .bt)。
如下图(图片来自 bpftrace文档)所示,bpftrace 会把你开发的脚本借助 BCC 编译加载到内核中执行,再通过 BPF 映射获取执行的结果:
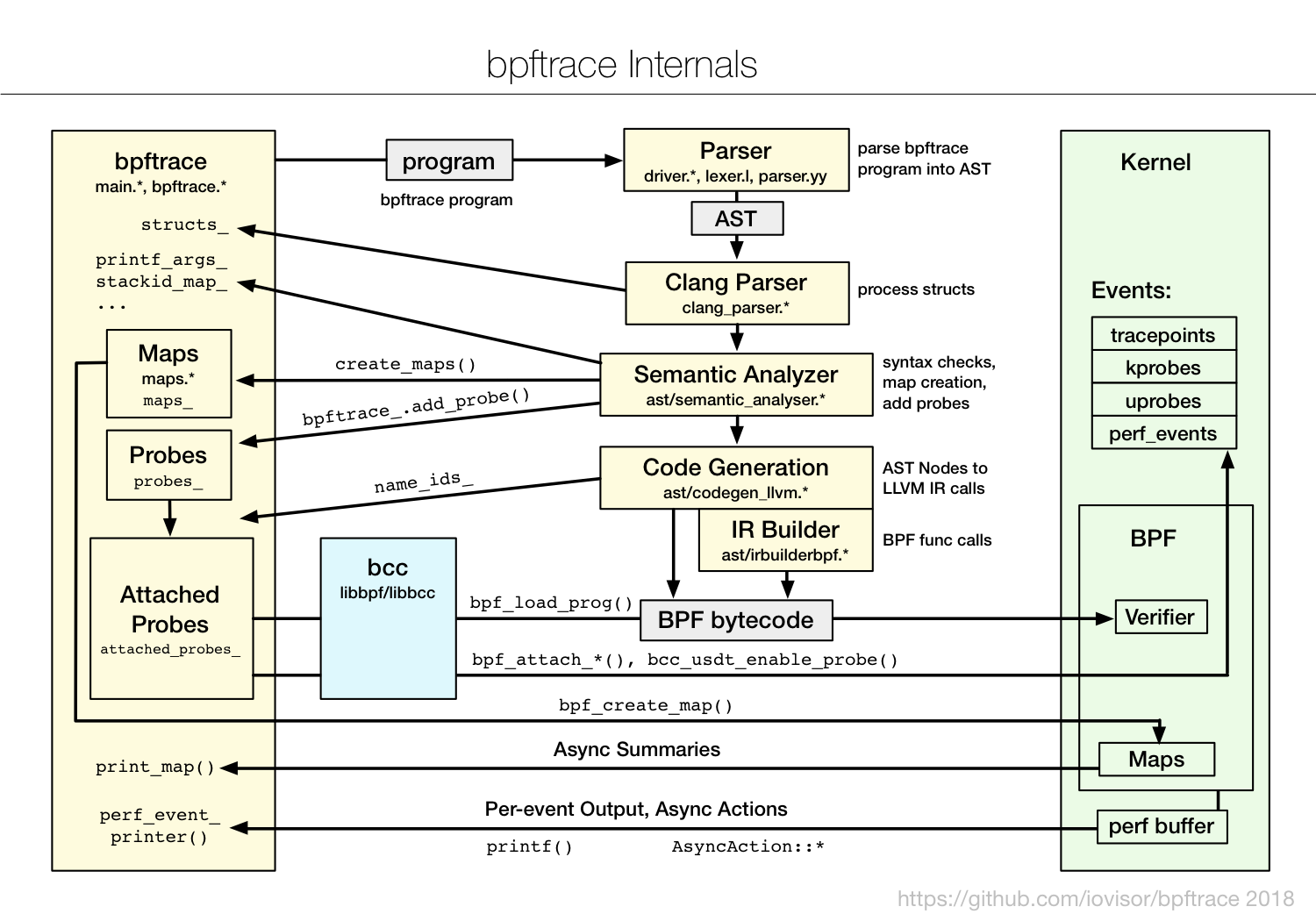
因此,在编写简单的 eBPF 程序,特别是编写的 eBPF 程序用于临时的调试和排错时,你可以考虑直接使用 bpftrace ,而不需要用 C 或 Python 去开发一个复杂的程序。
- 安装 bpf
1 | sudo apt-get install -y bpftrace |
安装好 bpftrace 之后,你就可以执行 bpftrace -l 来查询内核插桩和跟踪点了。比如你可以通过以下几种方式来查询:
1 | # 查询所有内核插桩和跟踪点 |
对于跟踪点来说,你还可以加上 -v 参数查询函数的入口参数或返回值。而由于内核函数属于不稳定的 API,在 bpftrace 中只能通过 arg0、arg1 这样的参数来访问,具体的参数格式还需要参考内核源代码。
比如,下面就是一个查询系统调用 execve 入口参数(对应系统调用 sys_enter_execve)和返回值(对应系统调用 sys_exit_execve)的示例:
1 | # 查询execve入口参数格式 |
所以,你既可以通过内核调试信息和 perf 来查询内核函数、跟踪点以及性能事件的列表,也可以使用 bpftrace 工具来查询。
在这两种方法中,我更推荐使用更简单的 bpftrace 进行查询。这是因为,我们通常只需要在开发环境查询这些列表,以便去准备 eBPF 程序的挂载点。也就是说,虽然 bpftrace 依赖 BCC 和 LLVM 开发工具,但开发环境本来就需要这些库和开发工具。综合来看,用 bpftrace 工具来查询的方法显然更简单快捷。
在开发 eBPF 程序之前,还需要在这些长长的函数列表中进行选择,确定你应该挂载到哪一个上。那么,具体该如何选择呢?接下来,就进入我们的案例环节,一起看看内核跟踪点的具体使用方法。
如何利用内核跟踪点排查短时进程问题?
在排查系统 CPU 使用率高的问题时,我想你很可能遇到过这样的困惑:明明通过 top 命令发现系统的 CPU 使用率(特别是用户 CPU 使用率)特别高,但通过 ps、pidstat 等工具都找不出 CPU 使用率高的进程。这是什么原因导致的呢?你可以先停下来思考一下,再继续下面的内容。
你想到可能的原因了吗?在我看来,一般情况下,这类问题很可能是以下两个原因导致的:
- 第一,应用程序里面直接调用其他二进制程序,并且这些程序的运行时间很短,通过 top 工具不容易发现;
- 第二,应用程序自身在不停地崩溃重启中,且重启间隔较短,启动过程中资源的初始化导致了高 CPU 使用率。
使用 top、ps 等性能工具很难发现这类短时进程,这是因为它们都只会按照给定的时间间隔采样,而不会实时采集到所有新创建的进程。那要如何才能采集到所有的短时进程呢?你肯定已经想到了,那就是利用 eBPF 的事件触发机制,跟踪内核每次新创建的进程,这样就可以揪出这些短时进程。
要跟踪内核新创建的进程,首先得找到要跟踪的内核函数或跟踪点。如果你了解过 Linux 编程中创建进程的过程,我想你已经知道了,创建一个新进程通常需要调用 fork() 和 execve() 这两个标准函数,它们的调用过程如下图所示:
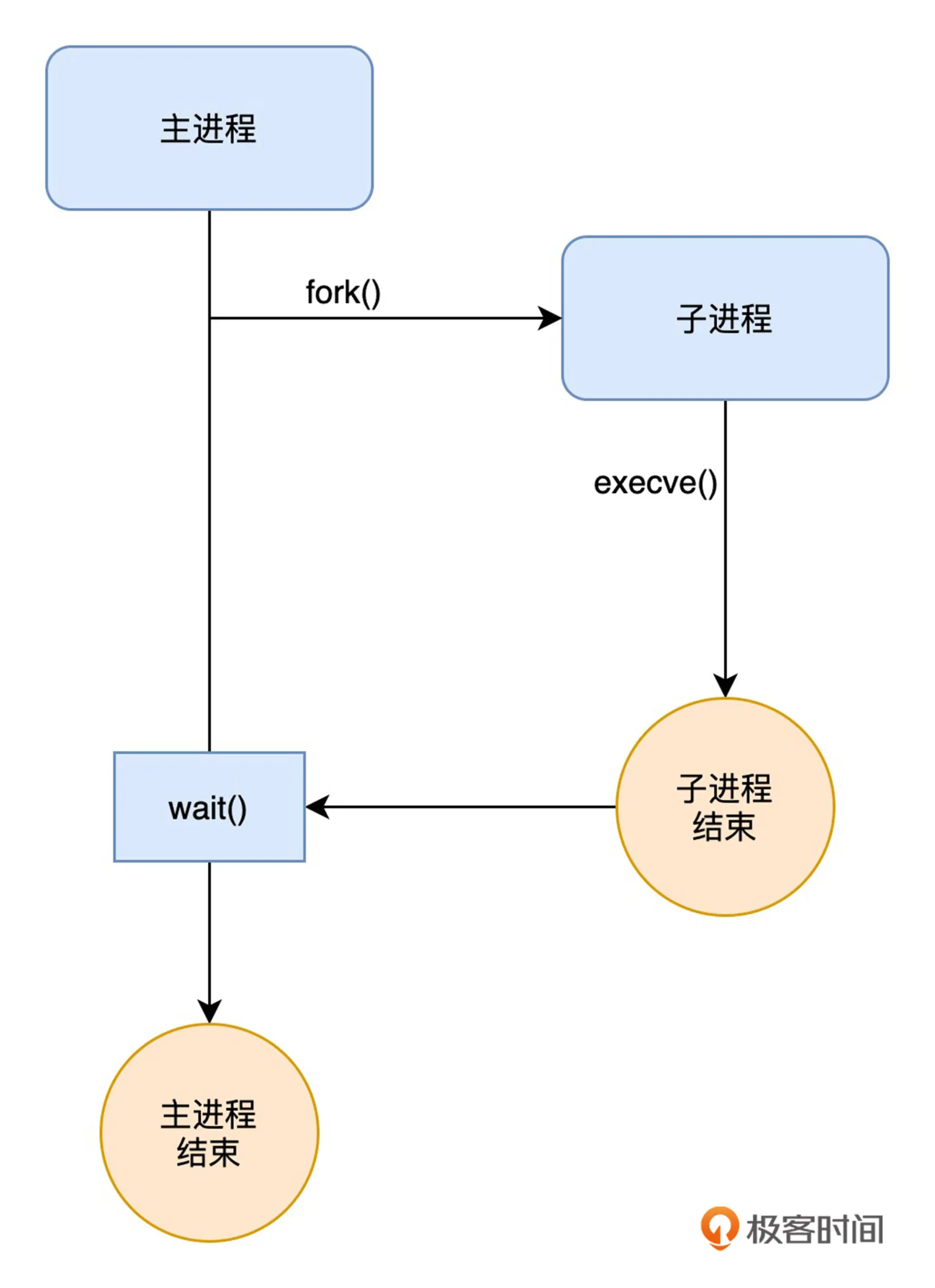
因为我们要关心的主要是新创建进程的基本信息,而像进程名称和参数等信息都在 execve() 的参数里,所以我们就要找出 execve() 所对应的内核函数或跟踪点。
借助刚才提到的 bpftrace 工具,你可以执行下面的命令,查询所有包含 execve 关键字的跟踪点:
1 | sudo bpftrace -l '*execve*' |
命令执行后,你会得到如下的输出内容:
1 | kprobe:__ia32_compat_sys_execve |
从输出中,你可以发现这些函数可以分为内核插桩(kprobe)和跟踪点(tracepoint)两类。在上一小节中我曾提到,内核插桩属于不稳定接口,而跟踪点则是稳定接口。因而,在内核插桩和跟踪点两者都可用的情况下,应该选择更稳定的跟踪点,以保证 eBPF 程序的可移植性(即在不同版本的内核中都可以正常执行)。
排除掉 kprobe 类型之后,剩下的 tracepoint:syscalls:sys_enter_execve、tracepoint:syscalls:sys_enter_execveat、tracepoint:syscalls:sys_exit_execve 以及 tracepoint:syscalls:sys_exit_execveat 就是我们想要的 eBPF 跟踪点。其中,sys_enter_ 和 sys_exit_ 分别表示在系统调用的入口和出口执行。
只有跟踪点的列表还不够,因为我们还想知道具体启动的进程名称、命令行选项以及返回值,而这些也都可以通过 bpftrace 来查询。在命令行中执行下面的命令,即可查询:
1 | # 查询sys_enter_execve入口参数 |
从输出中可以看到,sys_enter_execveat() 比 sys_enter_execve() 多了两个参数,而文件名 filename、命令行选项 argv 以及返回值 ret 的定义都是一样的。
到这里,我带你使用 bpftrace 查询到了 execve 相关的跟踪点,以及这些跟踪点的具体格式。接下来,为了帮你全方位掌握 eBPF 程序的开发过程,我会以 bpftrace、BCC 和 libbpf 这三种方式为例,带你开发一个跟踪短时进程的 eBPF 程序。这三种方式各有优缺点,在实际的生产环境中都有大量的应用:
- bpftrace 通常用在快速排查和定位系统上,它支持用单行脚本的方式来快速开发并执行一个 eBPF 程序。不过,bpftrace 的功能有限,不支持特别复杂的 eBPF 程序,也依赖于 BCC 和 LLVM 动态编译执行。
- BCC 通常用在开发复杂的 eBPF 程序中,其内置的各种小工具也是目前应用最为广泛的 eBPF 小程序。不过,BCC 也不是完美的,它依赖于 LLVM 和内核头文件才可以动态编译和加载 eBPF 程序。
- libbpf 是从内核中抽离出来的标准库,用它开发的 eBPF 程序可以直接分发执行,这样就不需要每台机器都安装 LLVM 和内核头文件了。不过,它要求内核开启 BTF 特性,需要非常新的发行版才会默认开启(如 RHEL 8.2+ 和 Ubuntu 20.10+ 等)。
在实际应用中,你可以根据你的内核版本、内核配置、eBPF 程序复杂度,以及是否允许安装内核头文件和 LLVM 等编译工具等,来选择最合适的方案。
bpftrace 方法
这一讲我们先来看看,如何使用 bpftrace 来跟踪短时进程。
由于 execve() 和 execveat() 这两个系统调用的入口参数文件名 filename 和命令行选项 argv ,以及返回值 ret 的定义都是一样的,因而我们可以把这两个跟踪点放到一起来处理。
1 | sudo bpftrace -e 'tracepoint:syscalls:sys_enter_execve,tracepoint:syscalls:sys_enter_execveat { printf("%-6d %-8s", pid, comm); join(args->argv);}' |
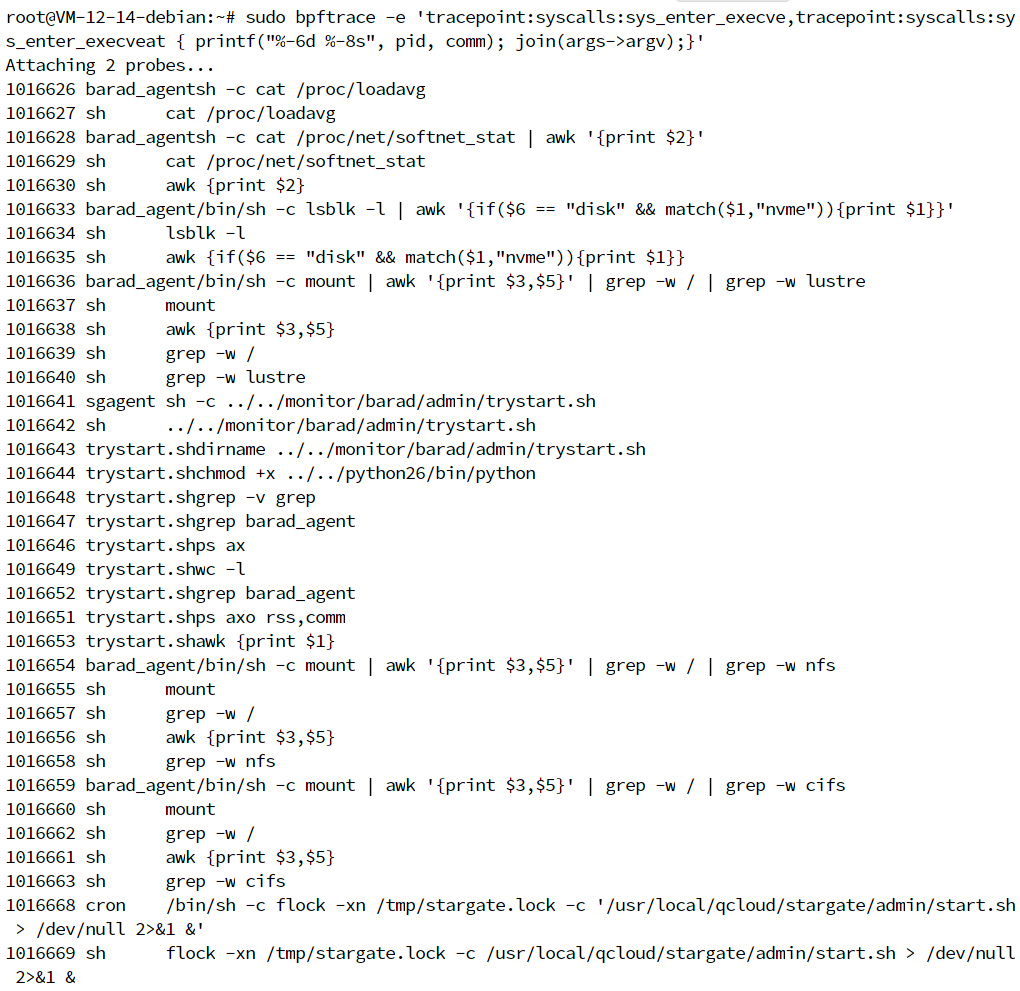
这个命令中的具体内容含义如下:
bpftrace -e表示直接从后面的字符串参数中读入 bpftrace 程序(除此之外,它还支持从文件中读入 bpftrace 程序);tracepoint:syscalls:sys_enter_execve,tracepoint:syscalls:sys_enter_execveat表示用逗号分隔的多个跟踪点,其后的中括号表示跟踪点的处理函数;printf()表示向终端中打印字符串,其用法类似于 C 语言中的printf()函数;pid和comm是 bpftrace 内置的变量,分别表示进程 PID 和进程名称(你可以在其官方文档中找到其他的内置变量);join(args->argv)表示把字符串数组格式的参数用空格拼接起来,再打印到终端中。对于跟踪点来说,你可以使用args->参数名的方式直接读取参数(比如这里的args->argv就是读取系统调用中的argv参数)。
在另一个终端中执行 ls 命令,然后你会在第一个终端中看到如下的输出:
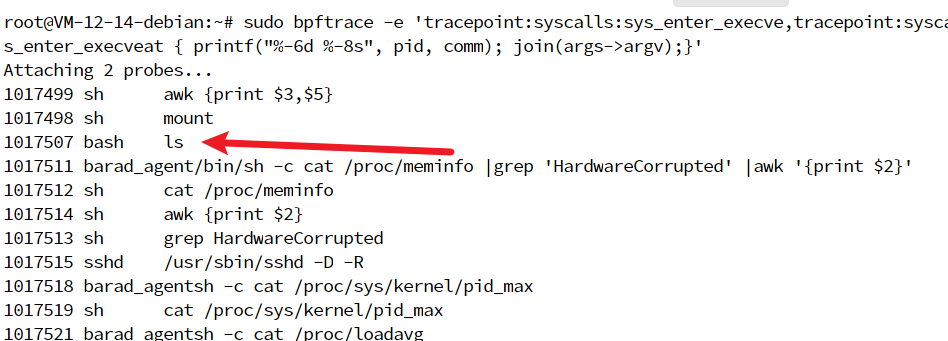
一个最简单的思路就是在系统调用的入口把参数保存到 BPF 映射中,然后再在系统调用出口获取返回值后一起输出。比如,你可以尝试执行下面的命令,把新进程的参数存入哈希映射中:
1 | # 其中,tid表示线程ID,@execs[tid]表示创建一个哈希映射 |
很遗憾,这条命令并不能正常运行。根据下面的错误信息,你可以发现,join() 这个内置函数没有返回字符串,不能用来赋值:
1 | stdin:1:90-106: ERROR: join() should not be used in an assignment or as a map key |
实际上,在 bpftrace 的 GitHub 页面上,已经有其他用户汇报了同样的问题,并且到现在还是没有解决。
bpftrace 本身并不适用于所有的 eBPF 应用。如果是复杂的应用,我还是推荐使用 BCC 或者 libbpf 开发。
再举一用例,在解决短时进程引发的性能问题时,找出短时进程才是最重要的。至于短时进程的执行结果,我们一般可以通过日志看到详细的运行过程。
不过,这个跟踪程序还是有一些比较大的限制,比如:
- 没有输出时间戳,这样去大量日志里面定位问题就比较困难;
- 没有父进程 PID,还需要一些额外的工具或经验,才可以找出父进程。
那么,这些问题该如何解决呢?
1 | ---------------- execsnoop.bt ----------------- |
bpftrace 小结
今天,我带你梳理了查询 eBPF 跟踪点的常用方法,并以短时进程的跟踪为例,通过 bpftrace 实现了短时进程的跟踪程序。
在跟踪内核时,你要记得,所有的内核跟踪都是被内核函数、内核跟踪点或性能事件等事件源触发后才执行的。所以,在跟踪内核之前,我们就需要通过调试信息、perf、bpftrace 等,找到这些事件源,然后再利用 eBPF 提供的强大功能去跟踪这些事件的执行过程。
bpftrace 是一个使用最为简单的 eBPF 工具,因此在初学 eBPF 时,建议你可以从它开始。bpftrace 提供了一个简单的脚本语言,只需要简单的几条脚本就可以实现很丰富的 eBPF 程序。它通常用在快速排查和定位系统上,并支持用单行脚本的方式来快速开发并执行一个 eBPF 程序。
BCC 开发内核追踪程序
BCC 方法
我们先来看看如何使用 BCC 来开发上一讲中短时进程的跟踪程序。这里先说明下,由于 execveat 的处理逻辑同 execve 基本相同,限于篇幅的长度,接下来的 BCC 和 libbpf 程序都以 execve 为例。
这里先回顾一下之前的内容,使用 BCC 开发 eBPF 程序包含两部分
- 第一部分是用 C 语言开发的 eBPF 程序。在 eBPF 程序中,你可以利用 BCC 提供的库函数和宏定义简化你的处理逻辑。
- 第二部分是用 Python 语言开发的前端界面,其中包含 eBPF 程序加载、挂载到内核函数和跟踪点,以及通过 BPF 映射获取和打印执行结果等部分。在前端程序中,你同样可以利用 BCC 库来访问 BPF 映射。
数据结构定义
我们先看第一部分。为了在系统调用入口跟踪点和出口跟踪点间共享进程信息等数据,我们可以定义一个哈希映射(比如命名为 tasks);同样地,因为我们想要在用户空间实时获取跟踪信息,这就需要一个性能事件映射。对于这两种映射的创建步骤,BCC 已经提供了非常方便的宏定义,你可以直接使用。
比如,你可以用下面的方式来创建这两个映射:
1 | struct data_t { |
代码中指令的具体作用如下:
struct data_t定义了一个包含进程基本信息的数据结构,它将用在哈希映射的值中(其中的参数大小args_size会在读取参数内容的时候用到);BPF_PERF_OUTPUT(events)定义了一个性能事件映射;BPF_HASH(tasks, u32, struct data_t)定义了一个哈希映射,其键为 32 位的进程 PID,而值则是进程基本信息data_t。
两个映射定义好之后,接下来就是定义跟踪点的处理函数。在 BCC 中,你可以通过 TRACEPOINT_PROBE(category, event) 来定义一个跟踪点处理函数。BCC 会将所有的参数放入 args 这个变量中,这样使用 args-><参数名> 就可以访问跟踪点的参数值。
对我们要跟踪的短时进程问题来说,也就是下面这两个跟踪点:
1 | // 定义sys_enter_execve跟踪点处理函数. |
入口跟踪点处理
对于入口跟踪点 sys_enter_execve 的处理,还是按照上一讲中 bpftrace 的逻辑,先获取进程的 PID、进程名称和参数列表之后,再存入刚刚定义的哈希映射中。
其中,进程 PID 和进程名称都比较容易获取。如下面的代码所示,你可以调用 bpf_get_current_pid_tgid() 查询进程 PID,调用 bpf_get_current_comm() 读取进程名称:
1 | // 获取进程PID和进程名称 |
而命令行参数的获取就没那么容易了。因为 BCC 把所有参数都放到了 args 中,你可以使用 args->argv 来访问参数列表:
1 | const char **argv = (const char **)(args->argv); |
注意,argv 是一个用户空间的字符串数组(指针数组),这就需要调用 bpf_probe_read 系列的辅助函数,去这些指针中读取数据。并且,字符串的数量(即参数的个数)和每个字符串的长度(即每个参数的长度)都是未知的,由于 eBPF 栈大小只有 512 字节,如果想要把它们读入一个临时的字符数组中,必须要保证每次读取的内容不超过栈的大小。这类问题有很多种不同的处理方法,其中一个比较简单的方式就是把多余的参数截断,使用...代替过长的参数。一般来说,知道了进程的名称和前几个参数,对调试和排错来说就足够了。
你可以定义最大读取的参数个数和参数长度,然后在哈希映射的值中定义一个字符数组,代码如下所示:
1 | // 定义参数长度和参数个数常量 |
有了字符数组,接下来再定义一个辅助函数,从参数数组中读取字符串参数(限定最长 ARGSIZE):
1 | // 从用户空间读取字符串 |
在这个函数中,有几点需要你注意:
bpf_probe_read_user_str()返回的是包含字符串结束符\0的长度。为了拼接所有的字符串,在计算已读取参数长度的时候,需要把\0排除在外。&data->argv[data->args_size]用来获取要存放参数的位置指针,这是为了把多个参数拼接到一起。- 在调用
bpf_probe_read_user_str()前后,需要对指针位置和返回值进行校验,这可以帮助 eBPF 验证器获取指针读写的边界(如果你感兴趣,可以参考这篇文章,了解更多的内存访问验证细节)。 - 在调用
bpf_probe_read_user_str()前后,需要对指针位置和返回值进行校验,这可以帮助 eBPF 验证器获取指针读写的边界(如果你感兴趣,可以参考这篇文章,了解更多的内存访问验证细节)。
有了这个辅助函数之后,因为 eBPF 在老版本内核中并不支持循环(有界循环在 5.3 之后才支持),要访问字符串数组,还需要一个小技巧:使用 #pragma unroll 告诉编译器,把源码中的循环自动展开。这就避免了最终的字节码中包含循环。
完整的处理函数如下所示(具体的每一步我都加了详细的注释,你可以参考注释来加深理解):
1 | // 引入内核头文件 |
注意,为了获取内核数据结构的定义,在文件的开头需要引入相关的内核头文件。此外,读取参数完成之后,不要忘记调用 tasks.update() 把进程的基本信息存储到哈希映射中。因为返回值需要等到出口跟踪点时才可以获取,这儿只需要更新哈希映射就可以了,不需要把进程信息提交到性能事件映射中去。
出口跟踪点处理
入口跟踪点 sys_enter_execve 处理好之后,我们再来看看出口跟踪点 sys_exit_execve 该如何处理。
由于进程的基本信息已经保存在了哈希映射中,所以出口事件的处理可以分为查询进程基本信息、填充返回值、最后再提交到性能事件映射这三个步骤。具体代码如下所示:
1 | // 定义sys_exit_execve跟踪点处理函数. |
到这里,完整的 eBPF 程序就开发好了,你可以把上述的代码保存到一个本地文件中,并命名为 execsnoop.c
1 | /* Tracing execve system call. */ |
Python 前端处理
eBPF 程序开发完成后,最后一步就是为它增加一个 Python 前端。
同之前写的 Hello World 类似,Python 前端逻辑需要 eBPF 程序加载、挂载到内核函数和跟踪点,以及通过 BPF 映射获取和打印执行结果等几个步骤。其中,因为我们已经使用了 TRACEPOINT_PROBE 宏定义,来定义 eBPF 跟踪点处理函数,BCC 在加载字节码的时候,会帮你自动把它挂载到正确的跟踪点上,所以挂载的步骤就可以忽略。完整的 Python 程序如下所示:
1 | # 引入库函数 |
把上述的代码保存到 execsnoop.py 中,然后通过 Python 运行,并在另一个终端中执行 ls 命令,你就可以得到如下的输出:
1 | $ sudo python3 execsnoop.py |
到此处,我们就开发了一个新的 eBPF 程序,它的作用也是排查短时进程相关的性能。
不过,在你想要分发这个程序到生产环境时,又会碰到一个新的难题:BCC 依赖于 LLVM 和内核头文件才可以动态编译和加载 eBPF 程序,而出于安全策略的需要,在生产环境中通常又不允许安装这些开发工具。
这个难题应该怎么克服呢?一种很容易想到的方法是把 BCC 和开发工具都安装到容器中,容器本身不提供对外服务,这样可以降低安全风险。另外一种方法就是参考内核中的 eBPF 示例,开发一个匹配当前内核版本的 eBPF 程序,并编译为字节码,再分发到生产环境中。
除此之外,如果你的内核已经支持了 BPF 类型格式 (BTF),我推荐你使用从内核源码中抽离出来的 libbpf 进行开发,这样可以借助 BTF 和 CO-RE 获得更好的移植性。实际上,BCC 的很多工具都在向 BTF 迁移中,相信未来 libbpf 会成为最受欢迎的 eBPF 程序开发基础库,甚至 Windows eBPF 也会支持 libbpf。
libbpf 开发内核追踪程序
libbpf 方法
那么,如何用 libbpf 来开发一个 eBPF 程序呢?跟刚才的 BCC 程序类似,使用 libbpf 开发 eBPF 程序也是分为两部分:
- 第一,内核态的 eBPF 程序;
- 第二,用户态的加载、挂载、映射读取以及输出程序等。
在 eBPF 程序中,由于内核已经支持了 BTF,你不再需要引入众多的内核头文件来获取内核数据结构的定义。取而代之的是一个通过 bpftool 生成的 vmlinux.h 头文件,其中包含了内核数据结构的定义。
这样,使用 libbpf 开发 eBPF 程序就可以通过以下四个步骤完成:
- 使用 bpftool 生成内核数据结构定义头文件。BTF 开启后,你可以在系统中找到
/sys/kernel/btf/vmlinux这个文件,bpftool 正是从它生成了内核数据结构头文件。 - 开发 eBPF 程序部分。为了方便后续通过统一的 Makefile 编译,eBPF 程序的源码文件一般命名为
<程序名>.bpf.c。 - 编译 eBPF 程序为字节码,然后再调用
bpftool gen skeleton为 eBPF 字节码生成脚手架头文件(Skeleton Header)。这个头文件包含了 eBPF 字节码以及相关的加载、挂载和卸载函数,可在用户态程序中直接调用。 - 最后就是用户态程序引入上一步生成的头文件,开发用户态程序,包括 eBPF 程序加载、挂载到内核函数和跟踪点,以及通过 BPF 映射获取和打印执行结果等。
通常,这几个步骤里面的编译、库链接、执行 bpftool 命令等,都可以放到 Makefile 中,这样就可以通过一个 make 命令去执行所有的步骤。比如,下面是一个简化版本的 Makefile:
1 | APPS = execsnoop |
有了这个 Makefile 之后,你执行 make vmlinux 命令就可以生成 vmlinux.h 文件,再执行 make 就可以编译 APPS 里面配置的所有 eBPF 程序(多个程序之间以空格分隔)。
内核头文件生成
首先,对于第一步,我们只需要执行下面的命令,即可生成内核数据结构的头文件:
1 | sudo bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h |
如果命令执行失败了,并且错误说 BTF 不存在,那说明当前系统内核没有开启 BTF 特性。这时候,你需要开启 CONFIG_DEBUG_INFO_BTF=y 和 CONFIG_DEBUG_INFO=y 这两个编译选项,然后重新编译和安装内核。
eBPF 程序定义
第二步就是开发 eBPF 程序,包括定义哈希映射、性能事件映射以及跟踪点的处理函数等,而对这些数据结构和跟踪函数的定义都可以通过 SEC() 宏定义来完成。在编译时,通过 SEC() 宏定义的数据结构和函数会放到特定的 ELF 段中,这样后续在加载 BPF 字节码时,就可以从这些段中获取所需的元数据。
比如,你可以使用下面的代码来定义映射和跟踪点处理函数:
1 | // 包含头文件 |
让我们来看看这段代码的具体含义:
- 头文件
vmlinux.h包含了内核数据结构,而bpf/bpf_helpers.h包含了之前提到的 BPF 辅助函数; struct event定义了进程基本信息数据结构,它会用在后面的哈希映射中;SEC(".maps")定义了哈希映射和性能事件映射;SEC("tracepoint/<跟踪点名称>")定义了跟踪点处理函数,系统调用跟踪点的格式是tracepoint/syscalls/<系统调用名称>"。以后你需要定义内核插桩和用户插桩的时候,也是以类似的格式定义,比如kprobe/do_unlinkat或uprobe/func;- 最后的
SEC("license")定义了 eBPF 程序的许可证。在上述的 BCC eBPF 程序中,我们并没有定义许可证,这是因为 BCC 自动帮你使用了 GPL 许可。
有了基本的程序结构,接下来就是实现系统调用入口和出口跟踪点的处理函数。它们的基本过程跟上述的 BCC 程序是类似的。
入口跟踪点处理
对于入口跟踪点 sys_enter_execve 的处理,还是按照上述 BCC 程序的逻辑,先获取进程的 PID、进程名称和参数列表之后,再存入刚刚定义的哈希映射中。完整代码如下所示,具体每一步的内容我都加了详细的注释:
1 | SEC("tracepoint/syscalls/sys_enter_execve") |
其中,你需要注意这三点:
- 第一,程序使用了
bpf_probe_read_user()来查询参数。由于它把\0也算到了已读取参数的长度里面,所以最终event->args中保存的各个参数是以\0分隔的。在用户态程序输出参数之前,需要用空格替换\0。 - 第二,程序在一开始的时候向哈希映射存入了一个空事件,在后续出口跟踪点处理的时候需要确保空事件也能正确清理。
- 第三,程序在最后又尝试多读取了一次参数列表。如果还有未读取参数,参数数量增加了 1。用户态程序可以根据参数数量来决定是不是需要在参数结尾输出一个
...。
出口跟踪点处理
入口跟踪点处理好之后,再来看看出口跟踪点的处理方法。它的步骤跟 BCC 程序也是类似的,也是查询进程基本信息、填充返回值、提交到性能事件映射这三个步骤。
除此之外,由于刚才入口跟踪点的处理中没有读取进程名称,所以在提交性能事件之前还需要先查询一下进程名称。完整的程序如下所示,具体每一步的内容我也加了详细的注释:
1 | SEC("tracepoint/syscalls/sys_exit_execve") |
从这些代码中你可以看到,它的处理逻辑跟上述的 BCC 程序基本上是相同的。不过,详细对比一下,你会发现它们之间还是有不同的,不同点主要在两个方面:
- 第一,函数名的定义格式不同。BCC 程序使用的是
TRACEPOINT_PROBE宏,而 libbpf 程序用的则是SEC宏。 - 第二,映射的访问方法不同。BCC 封装了很多更易用的映射访问函数(如
tasks.lookup()),而 libbpf 程序则需要调用 05 讲 提到过的 BPF 辅助函数(比如查询要使用bpf_map_lookup_elem())。
到这里,新建一个目录,并把上述代码存入 execsnoop.bpf.c 文件中,eBPF 部分的代码也就开发好了。
编译并生成脚手架头文件
有了 eBPF 程序,执行下面的命令,你就可以使用 clang 和 bpftool 将其编译成 BPF 字节码,然后再生成其脚手架头文件 execsnoop.skel.h (注意,脚手架头文件的名字一般定义为 <程序名>.skel.h):
1 | clang -g -O2 -target bpf -D__TARGET_ARCH_x86_64 -I/usr/include/x86_64-linux-gnu -I. -c execsnoop.bpf.c -o execsnoop.bpf.o |
其中,clang 的参数 -target bpf 表示要生成 BPF 字节码,-D__TARGET_ARCH_x86_64 表示目标的体系结构是 x86_64,而 -I 则是引入头文件路径。
命令执行后,脚手架头文件会放到 execsnoop.skel.h 中,这个头文件包含了 BPF 字节码和相关的管理函数。因而,当用户态程序引入这个头文件并编译之后,只需要分发最终用户态程序生成的二进制文件到生产环境即可(如果用户态程序使用了其他的动态库,还需要分发动态库)。
开发用户态程序
有了脚手架头文件之后,还剩下最后一步,也就是用户态程序的开发。
同 BCC 的 Python 前端程序类似,libbpf 用户态程序也需要 eBPF 程序加载、挂载到跟踪点,以及通过 BPF 映射获取和打印执行结果等几个步骤。虽然 C 语言听起来可能比 Python 语言麻烦一些,但实际上,这几个步骤都可以通过脚手架头文件中自动生成的函数来完成。
下面是忽略了错误处理逻辑之后,用户态程序的一个基本框架:
1 | // 引入脚手架头文件 |
其中,execsnoop_ 开头的数据结构和函数都包含在脚手架头文件 execsnoop.skel.h 中。而具体到每一步的含义如下:
- 第 1 步的调试输出函数中,可以调用
printf()把调试信息输出到终端中。 - 第 2 步增大锁定内存限制
RLIMIT_MEMLOCK是必要的,因为系统默认的锁定内存通常过小,无法满足 BPF 映射的需要。 - 第 3~5 步,直接调用脚手架头文件中的函数,加载 BPF 字节码并挂载到跟踪点。
- 第 6~7 步为性能事件设置回调函数,并从缓冲区中循环读取数据。注意,性能事件映射
skel->maps.events也是 bpftool 自动帮你生成好的。
接下来,在性能事件回调函数中,把数据格式转换为 struct event 格式之后,由于参数列表是使用 \0 来分割的,并不能直接向终端打印所有参数。所以,还需要把 \0 先替换为空格,然后再打印。完整的回调函数如下所示:
1 | // 性能事件回调函数(向终端中打印进程名、PID、返回值以及参数) |
把上面的代码保存到 execsnoop.c 文件中,然后执行下面的命令,将其编译为可执行文件:
1 | clang -g -O2 -Wall -I . -c execsnoop.c -o execsnoop.o |
最后,执行 execsnoop,你就可以得到如下的结果:
1 | $ sudo ./execsnoop |
你还可以直接把这个文件复制到开启了 BTF 的其他机器中,无需安装额外的 LLVM 开发工具和内核头文件,也可以直接执行。
如果命令失败,并且你看到如下的错误,这说明当前机器没有开启 BTF,需要重新编译内核开启 BTF 才可以运行:
1 | Failed to load and verify BPF skeleton |
虽然这三种方法的步骤和实现代码各不相同,但实际上它们的实现逻辑都是类似的,无非就是找出跟踪点,然后在 eBPF 部分获取想要的数据并保存到 BPF 映射中,最后在用户空间程序中读取 BPF 映射的内容并输出出来。
小结
在实际的应用中,这三种方法有不同的使用场景:
- bpftrace 通常用在快速排查和定位系统上,它支持用单行脚本的方式来快速开发并执行一个 eBPF 程序;
- BCC 通常用在开发复杂的 eBPF 程序中,它内置的各种小工具也是目前应用最为广泛的 eBPF 小程序;
- libbpf 是从内核中抽离出来的标准库,用它开发的 eBPF 程序可以直接分发执行,不再需要在每台机器上都安装 LLVM 和内核头文件。
通常情况下,你可以用 bpftrace 或 BCC 做一些快速原型,验证你的设计思路是不是可行,然后再切换到 libbpf ,开发完善的 eBPF 程序后再去分发执行。这样,不仅 eBPF 程序运行得更快(无需编译步骤),还避免了在运行环境中安装开发工具和内核头文件。
在不支持 BTF 的机器中,如果不想在运行 eBPF 时依赖于 LLVM 编译和内核头文件,你还可以参考内核中的 BPF 示例,直接引用内核源码中的 tools/lib/bpf/ 库,以及内核头文件中的数据结构,来开发 eBPF 程序。
- 本文标题:eBPF 内核跟踪
- 创建时间:2023-08-06 15:38:53
- 本文链接:2023/08/06/eBPF-内核跟踪/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!